Interpretable Action Recognition on Hard to Classify Actions
作者: Anastasia Anichenko, Frank Guerin, Andrew Gilbert
分类: cs.CV, cs.AI
发布日期: 2024-09-19
备注: 5 pages, This manuscript has been accepted at the Human-inspired Computer Vision (HCV) ECCV 2024 Workshop. arXiv admin note: text overlap with arXiv:2107.05319
💡 一句话要点
针对易混淆行为,提出基于3D感知的可解释行为识别模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 行为识别 3D感知 深度估计 可解释性 视频理解
📋 核心要点
- 现有行为识别模型在区分相似动作时存在困难,缺乏对3D信息的有效利用。
- 通过引入物体形状和深度关系,增强模型对场景3D结构的理解,提升区分能力。
- 实验表明,引入深度关系显著提升了模型在易混淆“放置”动作上的识别性能。
📝 摘要(中文)
本文研究了一种类人的、可解释的视频理解模型。人类通过识别明确识别的物体和部分之间的关键时空关系来识别视频中的复杂活动,例如,物体进入容器的孔径。为了模仿这一点,我们建立在一个使用物体和手的位置及其运动来识别正在发生的活动的模型之上。为了改进这个模型,我们专注于三个最容易混淆的类别(对于这个模型),并确定缺乏3D信息是主要问题。为了解决这个问题,我们通过两种方式扩展了我们的基本模型,增加了3D感知:(1)对最先进的物体检测模型进行了微调,以确定“容器”和“非容器”之间的差异,以便将物体形状信息集成到现有的物体特征中。(2)使用最先进的深度估计模型来提取单个物体的深度值,并计算深度关系,以扩展我们可解释模型中使用的现有关系。这些对我们基本模型的3D扩展在一组来自Something-Something-v2数据集的表面上相似的“放置”动作子集上进行了评估。结果表明,容器检测器并没有提高性能,但是添加深度关系对性能有显著的提高。
🔬 方法详解
问题定义:论文旨在解决行为识别中,模型难以区分相似动作的问题,尤其是在缺乏3D信息的情况下。现有方法主要依赖2D信息,无法有效捕捉物体间的空间关系和场景深度信息,导致模型在区分如“将物体放入容器”等动作时表现不佳。
核心思路:论文的核心思路是通过引入3D感知来增强模型对场景的理解。具体来说,通过添加物体形状信息和深度关系,使模型能够更好地捕捉物体间的空间关系和深度信息,从而提高区分相似动作的能力。这种方法模拟了人类通过理解场景的3D结构来识别动作的方式。
技术框架:该方法在现有的基于物体和手部位置及运动的行为识别模型基础上进行扩展。主要包含以下模块:1) 物体检测模块:用于检测视频中的物体,并区分“容器”和“非容器”;2) 深度估计模块:用于估计视频中物体的深度值;3) 关系推理模块:用于根据物体的位置、运动、形状和深度信息,推断物体间的关系,从而识别动作。整体流程是先进行物体检测和深度估计,然后将这些信息输入到关系推理模块中进行动作识别。
关键创新:论文的关键创新在于将3D信息(物体形状和深度关系)融入到可解释的行为识别模型中。与现有方法相比,该方法能够更好地捕捉物体间的空间关系和深度信息,从而提高区分相似动作的能力。此外,该方法还保持了模型的可解释性,使得人们可以理解模型是如何做出决策的。
关键设计:论文使用了微调后的物体检测模型来区分“容器”和“非容器”,从而引入物体形状信息。同时,使用了最先进的深度估计模型来提取物体的深度值,并计算物体间的深度关系。在实验中,作者使用了Something-Something-v2数据集的一个子集,专注于三个易混淆的“放置”动作。具体的参数设置和网络结构细节在论文中未详细描述。
🖼️ 关键图片
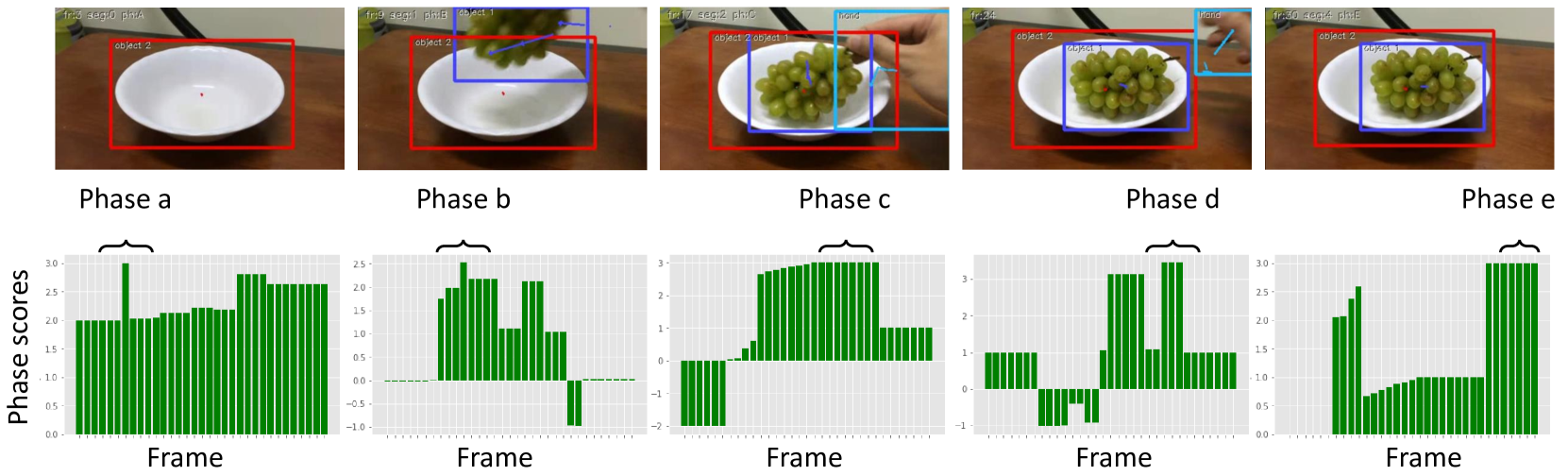
📊 实验亮点
实验结果表明,添加深度关系能够显著提高模型在区分易混淆的“放置”动作上的性能。虽然容器检测器没有带来性能提升,但深度关系的引入验证了3D信息对于区分相似动作的重要性。具体的性能提升幅度在论文中未给出明确的数值。
🎯 应用场景
该研究成果可应用于智能监控、人机交互、机器人导航等领域。例如,在智能监控中,可以利用该技术识别异常行为,提高安全性。在人机交互中,可以使机器人更好地理解人类的意图,从而实现更自然的人机交互。在机器人导航中,可以帮助机器人更好地理解周围环境,从而实现更安全的导航。
📄 摘要(原文)
We investigate a human-like interpretable model of video understanding. Humans recognise complex activities in video by recognising critical spatio-temporal relations among explicitly recognised objects and parts, for example, an object entering the aperture of a container. To mimic this we build on a model which uses positions of objects and hands, and their motions, to recognise the activity taking place. To improve this model we focussed on three of the most confused classes (for this model) and identified that the lack of 3D information was the major problem. To address this we extended our basic model by adding 3D awareness in two ways: (1) A state-of-the-art object detection model was fine-tuned to determine the difference between "Container" and "NotContainer" in order to integrate object shape information into the existing object features. (2) A state-of-the-art depth estimation model was used to extract depth values for individual objects and calculate depth relations to expand the existing relations used our interpretable model. These 3D extensions to our basic model were evaluated on a subset of three superficially similar "Putting" actions from the Something-Something-v2 dataset. The results showed that the container detector did not improve performance, but the addition of depth relations made a significant improvement to performance.