Oryx MLLM: On-Demand Spatial-Temporal Understanding at Arbitrary Resolution
作者: Zuyan Liu, Yuhao Dong, Ziwei Liu, Winston Hu, Jiwen Lu, Yongming Rao
分类: cs.CV
发布日期: 2024-09-19 (更新: 2025-02-27)
备注: Accepted to ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
Oryx:提出按需时空理解MLLM,解决任意分辨率视觉数据处理难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 视觉理解 任意分辨率 时空理解 动态压缩 长视频理解 OryxViT
📋 核心要点
- 现有多模态LLM在处理不同分辨率和时长的视觉数据时,采用固定分辨率编码,导致效率低下和理解能力受限。
- Oryx提出了一种按需时空理解框架,通过OryxViT和动态压缩模块,灵活处理任意分辨率和时长的视觉输入。
- 通过增强数据和专门训练,Oryx在图像、视频和3D多模态理解方面取得了显著效果,并开源了相关代码。
📝 摘要(中文)
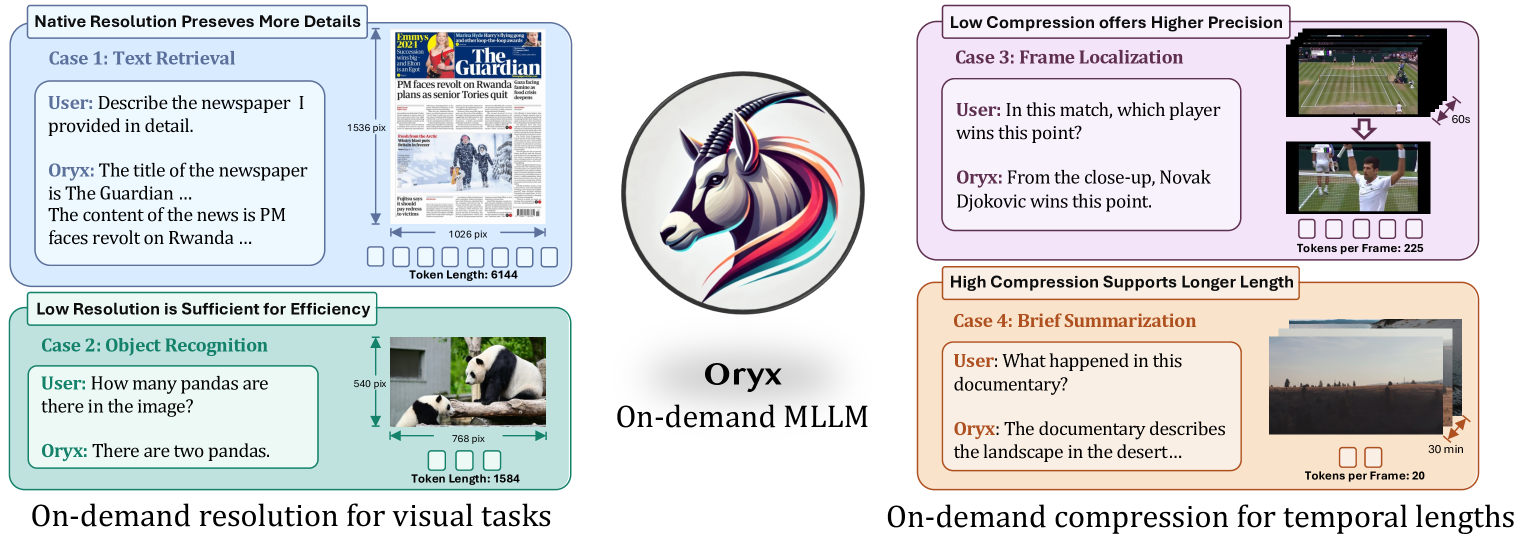
现有的多模态LLM通常将各种视觉输入标准化为固定分辨率,这对于多模态理解并非最优,且处理长短视觉内容效率低下。为了解决这个问题,我们提出了Oryx,一个统一的多模态架构,用于图像、视频和多视角3D场景的时空理解。Oryx通过两个核心创新提供了一种按需解决方案,可以无缝且高效地处理任意空间尺寸和时间长度的视觉输入:1) 一个预训练的OryxViT模型,可以将任意分辨率的图像编码为LLM友好的视觉表示;2) 一个动态压缩模块,支持按需对视觉tokens进行1x到16x的压缩。这些设计特性使Oryx能够容纳极长的视觉上下文(如视频),同时保持高识别精度,例如对于具有原始分辨率且无需压缩的文档理解任务。除了架构改进之外,增强的数据管理和对长上下文检索和空间感知数据的专门训练有助于Oryx同时在图像、视频和3D多模态理解方面实现强大的能力。我们的工作已开源。
🔬 方法详解
问题定义:现有方法在处理视觉数据时,通常将输入图像或视频缩放到固定分辨率,然后输入到视觉编码器中。这种做法忽略了不同视觉内容本身的空间和时间特性,例如,文档图像需要高分辨率才能识别文字,而长视频则需要低分辨率以减少计算量。因此,现有方法无法根据视觉内容的需求自适应地调整分辨率,导致效率低下和性能下降。
核心思路:Oryx的核心思路是提供一种“按需”的视觉处理方案,即根据视觉内容的空间和时间特性,动态地调整分辨率和token数量。具体来说,OryxViT能够处理任意分辨率的图像,并生成LLM友好的视觉表示。动态压缩模块则可以根据需要对视觉tokens进行压缩,从而在保证性能的同时,减少计算量。
技术框架:Oryx的整体架构包含以下几个主要模块:1) OryxViT:一个预训练的视觉编码器,能够处理任意分辨率的图像。2) 动态压缩模块:一个可学习的模块,能够根据需要对视觉tokens进行压缩。3) LLM:一个大型语言模型,用于处理视觉和文本信息。Oryx首先使用OryxViT对视觉输入进行编码,然后使用动态压缩模块对视觉tokens进行压缩。最后,将压缩后的视觉tokens和文本信息输入到LLM中进行处理。
关键创新:Oryx最重要的技术创新点在于其“按需”的视觉处理方案。与现有方法相比,Oryx能够根据视觉内容的空间和时间特性,动态地调整分辨率和token数量,从而在保证性能的同时,提高效率。OryxViT和动态压缩模块是实现这一目标的关键组件。
关键设计:OryxViT采用了多尺度特征融合的设计,能够有效地处理不同分辨率的图像。动态压缩模块则采用了可学习的压缩策略,能够根据视觉内容的重要性,自适应地选择需要保留的tokens。此外,Oryx还采用了增强的数据管理和专门训练策略,以提高其在长上下文检索和空间感知方面的能力。
🖼️ 关键图片


📊 实验亮点
论文通过大量实验验证了Oryx的有效性。实验结果表明,Oryx在图像、视频和3D多模态理解方面均取得了显著的性能提升。例如,在长上下文视频检索任务中,Oryx的性能优于现有方法,并且能够处理更长的视频序列。此外,Oryx在文档理解任务中也取得了优异的成绩,证明了其处理高分辨率图像的能力。
🎯 应用场景
Oryx在多个领域具有广泛的应用前景,例如文档理解、视频分析、3D场景理解等。它可以用于处理各种类型的视觉数据,包括高分辨率图像、长视频和多视角3D场景。Oryx的按需处理能力使其能够高效地处理大规模视觉数据,并为各种应用提供强大的视觉理解能力。未来,Oryx有望成为多模态LLM的重要组成部分,推动人工智能技术的发展。
📄 摘要(原文)
Visual data comes in various forms, ranging from small icons of just a few pixels to long videos spanning hours. Existing multi-modal LLMs usually standardize these diverse visual inputs to a fixed resolution for visual encoders and yield similar numbers of tokens for LLMs. This approach is non-optimal for multimodal understanding and inefficient for processing inputs with long and short visual contents. To solve the problem, we propose Oryx, a unified multimodal architecture for the spatial-temporal understanding of images, videos, and multi-view 3D scenes. Oryx offers an on-demand solution to seamlessly and efficiently process visual inputs with arbitrary spatial sizes and temporal lengths through two core innovations: 1) a pre-trained OryxViT model that can encode images at any resolution into LLM-friendly visual representations; 2) a dynamic compressor module that supports 1x to 16x compression on visual tokens by request. These design features enable Oryx to accommodate extremely long visual contexts, such as videos, with lower resolution and high compression while maintaining high recognition precision for tasks like document understanding with native resolution and no compression. Beyond the architectural improvements, enhanced data curation and specialized training on long-context retrieval and spatial-aware data help Oryx achieve strong capabilities in image, video, and 3D multimodal understanding simultaneously. Our work is open-sourced at https://github.com/Oryx-mllm/Oryx.