MMSearch: Benchmarking the Potential of Large Models as Multi-modal Search Engines
作者: Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanmin Wu, Jiayi Lei, Pengshuo Qiu, Pan Lu, Zehui Chen, Chaoyou Fu, Guanglu Song, Peng Gao, Yu Liu, Chunyuan Li, Hongsheng Li
分类: cs.CV, cs.AI, cs.CL, cs.IR
发布日期: 2024-09-19 (更新: 2024-11-27)
备注: Project Page: https://mmsearch.github.io
💡 一句话要点
提出MMSearch以解决多模态搜索引擎的潜力评估问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态搜索 大型语言模型 搜索引擎 性能评估 人工智能
📋 核心要点
- 现有的AI搜索引擎大多局限于文本处理,未能充分利用多模态信息,导致用户体验不足。
- 本文提出MMSearch-Engine,旨在为大型多模态模型赋能,使其具备处理多模态搜索任务的能力,并引入MMSearch基准进行评估。
- 实验结果表明,使用MMSearch-Engine的GPT-4o在多模态搜索任务中表现优异,超越了现有商业产品,展示了该方法的有效性。
📝 摘要(中文)
大型语言模型(LLMs)的出现为人工智能搜索引擎开辟了新天地,然而现有的AI搜索引擎大多仅限于文本,忽视了多模态用户查询和文本-图像交织的信息。本文设计了MMSearch-Engine,赋予大型多模态模型(LMMs)多模态搜索能力,并引入了MMSearch评估基准,评估LMMs的多模态搜索性能。我们构建了一个包含300个手动收集实例的数据集,确保与现有LMMs训练数据无重叠。通过MMSearch-Engine对LMMs进行评估,结果显示GPT-4o在端到端任务中表现优于商业产品Perplexity Pro,验证了我们方法的有效性。
🔬 方法详解
问题定义:本文旨在解决现有AI搜索引擎在处理多模态用户查询时的不足,尤其是文本与图像信息的交互处理能力。现有方法未能充分利用LMMs的潜力,导致多模态搜索效果不佳。
核心思路:我们设计了MMSearch-Engine,赋予LMMs多模态搜索能力,并通过MMSearch基准对其性能进行全面评估。该方法通过精心设计的管道,确保LMMs能够有效处理多模态信息。
技术框架:MMSearch-Engine的整体架构包括数据收集、任务设计和评估模块。我们构建了一个包含300个实例的数据集,涵盖14个子领域,并设计了三个独立任务(重查询、重排序和摘要)及一个完整的端到端任务。
关键创新:本文的主要创新在于引入MMSearch基准,确保评估数据与现有LMMs训练数据无重叠,从而真实反映模型的搜索能力。此外,MMSearch-Engine的设计使得LMMs能够在多模态搜索任务中表现出色。
关键设计:在模型评估中,我们采用了特定的损失函数和参数设置,以优化多模态信息的处理能力。通过对不同模型的广泛实验,我们能够识别出当前LMMs在多模态搜索任务中的不足之处,并提出改进建议。
🖼️ 关键图片

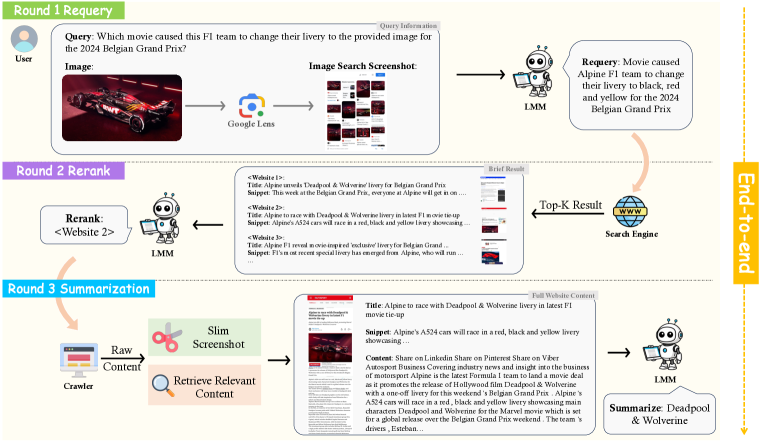
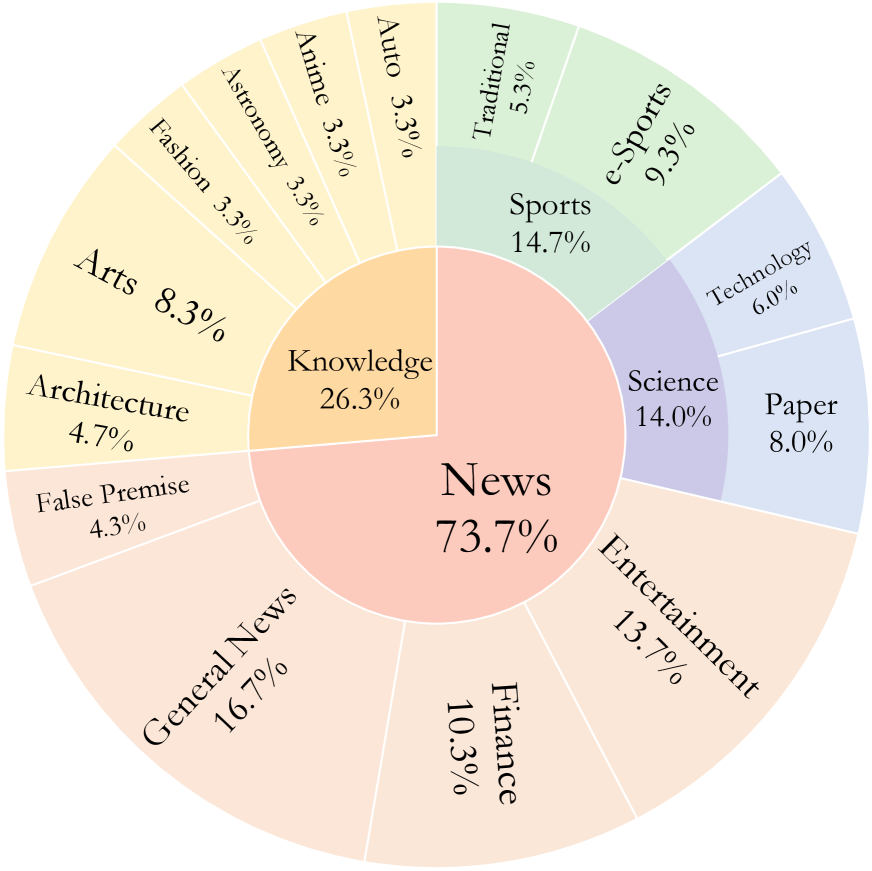
📊 实验亮点
在实验中,使用MMSearch-Engine的GPT-4o在端到端任务中表现最佳,超越了商业产品Perplexity Pro,显示出显著的性能提升。这一结果验证了MMSearch-Engine的有效性,并为多模态搜索引擎的未来发展提供了重要参考。
🎯 应用场景
该研究的潜在应用领域包括智能搜索引擎、在线教育、电子商务等,能够提升用户在多模态信息检索中的体验。未来,随着多模态AI搜索引擎的发展,用户将能够更高效地获取信息,推动人机交互的进一步升级。
📄 摘要(原文)
The advent of Large Language Models (LLMs) has paved the way for AI search engines, e.g., SearchGPT, showcasing a new paradigm in human-internet interaction. However, most current AI search engines are limited to text-only settings, neglecting the multimodal user queries and the text-image interleaved nature of website information. Recently, Large Multimodal Models (LMMs) have made impressive strides. Yet, whether they can function as AI search engines remains under-explored, leaving the potential of LMMs in multimodal search an open question. To this end, we first design a delicate pipeline, MMSearch-Engine, to empower any LMMs with multimodal search capabilities. On top of this, we introduce MMSearch, a comprehensive evaluation benchmark to assess the multimodal search performance of LMMs. The curated dataset contains 300 manually collected instances spanning 14 subfields, which involves no overlap with the current LMMs' training data, ensuring the correct answer can only be obtained within searching. By using MMSearch-Engine, the LMMs are evaluated by performing three individual tasks (requery, rerank, and summarization), and one challenging end-to-end task with a complete searching process. We conduct extensive experiments on closed-source and open-source LMMs. Among all tested models, GPT-4o with MMSearch-Engine achieves the best results, which surpasses the commercial product, Perplexity Pro, in the end-to-end task, demonstrating the effectiveness of our proposed pipeline. We further present error analysis to unveil current LMMs still struggle to fully grasp the multimodal search tasks, and conduct ablation study to indicate the potential of scaling test-time computation for AI search engine. We hope MMSearch may provide unique insights to guide the future development of multimodal AI search engine. Project Page: https://mmsearch.github.io