Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
作者: Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, Junyang Lin
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-09-18 (更新: 2024-10-03)
备注: Code is available at https://github.com/QwenLM/Qwen2-VL. arXiv admin note: text overlap with arXiv:2408.15262 by other authors
🔗 代码/项目: GITHUB
💡 一句话要点
Qwen2-VL:通过动态分辨率增强视觉语言模型对世界的感知
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 动态分辨率 多模态融合 旋转位置编码 图像理解
📋 核心要点
- 现有视觉语言模型通常采用固定分辨率处理图像,限制了模型对不同细节层次图像的理解能力和效率。
- Qwen2-VL提出朴素动态分辨率机制,使模型能根据图像分辨率动态调整视觉tokens数量,更高效地提取视觉特征。
- 实验结果表明,Qwen2-VL系列模型在多个多模态基准测试中表现出色,72B版本可与GPT-4o等领先模型媲美。
📝 摘要(中文)
Qwen2-VL系列是对先前Qwen-VL模型的重大升级,它重新定义了视觉处理中传统的预定分辨率方法。Qwen2-VL引入了朴素动态分辨率机制,使模型能够动态地处理不同分辨率的图像,并将其转换为不同数量的视觉tokens。这种方法使得模型能够生成更高效、更准确的视觉表示,更贴近人类的感知过程。该模型还集成了多模态旋转位置编码(M-RoPE),从而促进了文本、图像和视频之间位置信息的有效融合。我们采用统一的范式来处理图像和视频,从而增强了模型的视觉感知能力。为了探索大型多模态模型的潜力,Qwen2-VL研究了大型视觉语言模型(LVLM)的缩放规律。通过扩展模型大小(包括2B、8B和72B参数的版本)和训练数据量,Qwen2-VL系列取得了极具竞争力的性能。值得注意的是,Qwen2-VL-72B模型在各种多模态基准测试中取得了与GPT-4o和Claude3.5-Sonnet等领先模型相当的结果,优于其他通用模型。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)在处理图像时通常采用预先设定的固定分辨率,这导致两个主要问题。一是对于高分辨率图像,固定分辨率可能导致信息丢失,无法充分利用图像中的细节信息。二是对于低分辨率图像,固定分辨率可能引入不必要的计算开销,效率较低。因此,如何使VLM能够根据输入图像的分辨率动态调整处理方式,从而提高效率和准确性,是一个重要的研究问题。
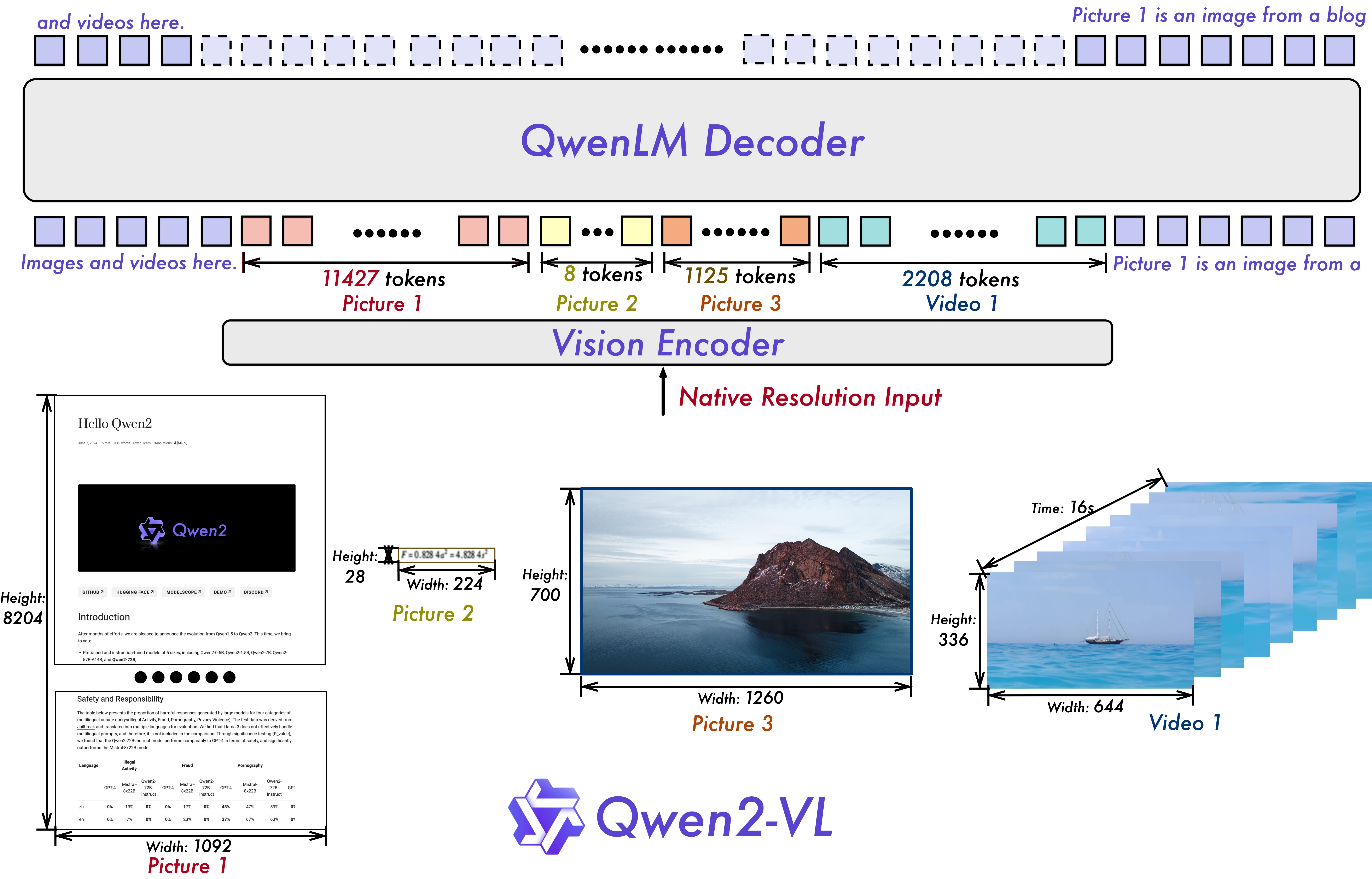
核心思路:Qwen2-VL的核心思路是引入“朴素动态分辨率”机制,允许模型根据输入图像的分辨率动态地生成不同数量的视觉tokens。这意味着模型不再需要将所有图像都缩放到相同的预定分辨率,而是可以根据图像的实际分辨率自适应地调整视觉特征的提取方式。这种设计更符合人类的视觉感知方式,能够更有效地利用图像中的信息。
技术框架:Qwen2-VL的整体框架包括视觉编码器、多模态连接器和语言模型三个主要模块。视觉编码器负责将输入图像转换为视觉特征表示,多模态连接器负责将视觉特征与文本特征进行融合,语言模型则负责生成最终的输出。关键在于视觉编码器部分,它采用了动态分辨率机制,能够根据输入图像的分辨率生成不同数量的视觉tokens。此外,模型还集成了多模态旋转位置编码(M-RoPE),以更好地融合文本、图像和视频的位置信息。
关键创新:Qwen2-VL最重要的技术创新点是朴素动态分辨率机制。与传统的固定分辨率方法相比,该机制能够根据输入图像的分辨率自适应地调整视觉特征的提取方式,从而提高模型的效率和准确性。此外,M-RoPE的引入也增强了模型对多模态信息的处理能力。
关键设计:在动态分辨率机制中,模型首先根据输入图像的分辨率确定视觉tokens的数量。然后,视觉编码器将图像分割成相应数量的patches,并提取每个patch的特征。这些特征被转换为视觉tokens,并输入到多模态连接器中。M-RoPE则通过旋转位置编码的方式,将位置信息融入到文本、图像和视频的特征表示中,从而更好地融合多模态信息。具体的参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
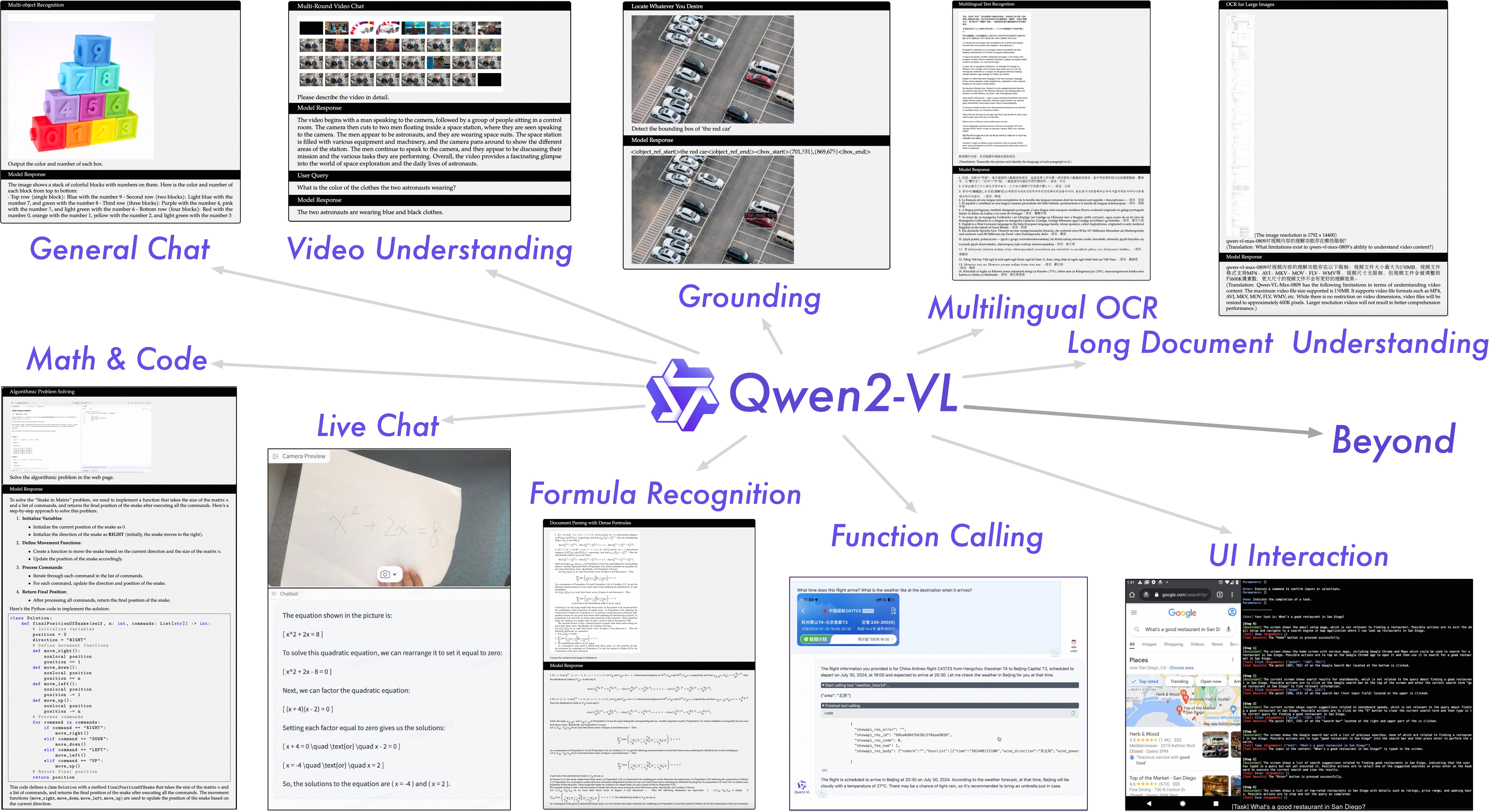

📊 实验亮点
Qwen2-VL系列模型在多个多模态基准测试中取得了显著成果。特别是Qwen2-VL-72B模型,其性能与GPT-4o和Claude3.5-Sonnet等领先模型相当,并在某些任务上超越了其他通用模型。这表明Qwen2-VL在视觉语言理解方面具有强大的能力,为构建更强大的多模态AI系统奠定了基础。
🎯 应用场景
Qwen2-VL的应用场景广泛,包括智能问答、图像描述、视觉推理、视频理解等。该模型可用于开发更智能的聊天机器人、图像搜索引擎和视频分析工具。其动态分辨率处理能力使其在处理各种分辨率的图像和视频时更具优势,有望在医疗影像分析、遥感图像处理等领域发挥重要作用。
📄 摘要(原文)
We present the Qwen2-VL Series, an advanced upgrade of the previous Qwen-VL models that redefines the conventional predetermined-resolution approach in visual processing. Qwen2-VL introduces the Naive Dynamic Resolution mechanism, which enables the model to dynamically process images of varying resolutions into different numbers of visual tokens. This approach allows the model to generate more efficient and accurate visual representations, closely aligning with human perceptual processes. The model also integrates Multimodal Rotary Position Embedding (M-RoPE), facilitating the effective fusion of positional information across text, images, and videos. We employ a unified paradigm for processing both images and videos, enhancing the model's visual perception capabilities. To explore the potential of large multimodal models, Qwen2-VL investigates the scaling laws for large vision-language models (LVLMs). By scaling both the model size-with versions at 2B, 8B, and 72B parameters-and the amount of training data, the Qwen2-VL Series achieves highly competitive performance. Notably, the Qwen2-VL-72B model achieves results comparable to leading models such as GPT-4o and Claude3.5-Sonnet across various multimodal benchmarks, outperforming other generalist models. Code is available at https://github.com/QwenLM/Qwen2-VL .