JEAN: Joint Expression and Audio-guided NeRF-based Talking Face Generation
作者: Sai Tanmay Reddy Chakkera, Aggelina Chatziagapi, Dimitris Samaras
分类: cs.CV
发布日期: 2024-09-18
备注: Accepted by BMVC 2024. Project Page: https://starc52.github.io/publications/2024-07-19-JEAN
💡 一句话要点
提出JEAN,一种基于NeRF的联合表情和音频引导的说话人脸生成方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 说话人脸生成 NeRF 表情迁移 唇部同步 解耦表示
📋 核心要点
- 现有说话人脸生成方法难以兼顾说话人身份保持和逼真表情生成,面临挑战。
- 提出基于NeRF的网络,通过解耦音频和表情表示,实现高质量的说话人脸合成。
- 通过对比学习和Transformer架构,有效解耦音频和表情特征,提升表情迁移和唇部同步效果。
📝 摘要(中文)
本文提出了一种新颖的联合表情和音频引导的说话人脸生成方法。现有方法要么难以保持说话人的身份,要么无法生成逼真的面部表情。为了解决这些挑战,我们提出了一种基于NeRF的网络。由于我们在没有任何ground truth的情况下,在单目视频上训练我们的网络,因此学习音频和表情的解耦表示至关重要。我们首先以自监督的方式学习音频特征,给定来自多个主体的语音。通过结合对比学习技术,我们确保学习到的音频特征与嘴唇运动对齐,并与面部其余部分的肌肉运动解耦。然后,我们设计了一种基于Transformer的架构,该架构学习表情特征,捕捉长程面部表情,并将它们与特定于语音的嘴部运动解耦。通过定量和定性评估,我们证明了我们的方法可以合成高保真的说话人脸视频,实现最先进的面部表情迁移以及与未见音频的唇部同步。
🔬 方法详解
问题定义:论文旨在解决说话人脸生成中,现有方法难以同时保持说话人身份和生成逼真面部表情的问题。现有方法在表情迁移和唇部同步方面存在不足,尤其是在处理未见过的音频时,容易出现身份信息丢失或表情不自然的情况。
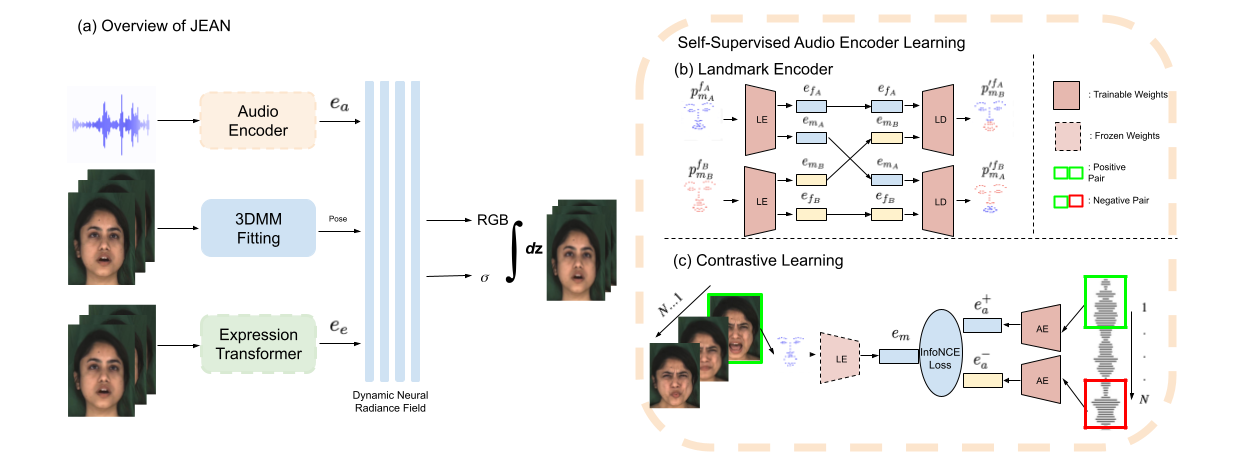
核心思路:论文的核心思路是利用NeRF(Neural Radiance Field)作为底层表示,并学习解耦的音频和表情特征。通过将音频特征与唇部运动对齐,并将表情特征与语音无关的面部运动解耦,从而实现更逼真的说话人脸生成。这种解耦允许更好地控制面部表情,并保持说话人的身份。
技术框架:整体框架包含以下几个主要模块:1) 自监督音频特征学习模块,利用对比学习将音频特征与唇部运动对齐;2) 基于Transformer的表情特征学习模块,捕捉长程面部表情并与语音相关的嘴部运动解耦;3) 基于NeRF的渲染模块,将学习到的音频和表情特征融合,生成最终的说话人脸视频。
关键创新:论文的关键创新在于:1) 提出了一种联合表情和音频引导的NeRF框架,能够同时控制面部表情和唇部同步;2) 利用对比学习和Transformer架构,实现了音频和表情特征的有效解耦,提高了表情迁移的质量和唇部同步的准确性;3) 在单目视频上进行训练,无需ground truth数据,降低了数据收集的成本。
关键设计:在音频特征学习中,使用了对比损失来确保音频特征与唇部运动对齐,并与面部其余部分的肌肉运动解耦。在表情特征学习中,使用了Transformer架构来捕捉长程面部表情,并使用特定的损失函数来鼓励表情特征与语音无关。NeRF渲染模块则将音频和表情特征作为输入,生成最终的说话人脸视频。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
论文通过定量和定性实验证明了所提出方法的有效性。实验结果表明,该方法在面部表情迁移和唇部同步方面均取得了state-of-the-art的性能。与现有方法相比,该方法能够生成更高质量、更逼真的说话人脸视频,并且能够更好地保持说话人的身份。具体的性能数据和对比结果在论文中有详细展示。
🎯 应用场景
该研究成果可应用于虚拟化身生成、视频会议、电影制作、游戏开发等领域。通过该技术,可以创建更逼真、更具表现力的虚拟角色,提升用户体验。此外,该技术还可以用于辅助语音障碍患者进行交流,或用于生成个性化的教育视频。未来,该技术有望在人机交互领域发挥更大的作用。
📄 摘要(原文)
We introduce a novel method for joint expression and audio-guided talking face generation. Recent approaches either struggle to preserve the speaker identity or fail to produce faithful facial expressions. To address these challenges, we propose a NeRF-based network. Since we train our network on monocular videos without any ground truth, it is essential to learn disentangled representations for audio and expression. We first learn audio features in a self-supervised manner, given utterances from multiple subjects. By incorporating a contrastive learning technique, we ensure that the learned audio features are aligned to the lip motion and disentangled from the muscle motion of the rest of the face. We then devise a transformer-based architecture that learns expression features, capturing long-range facial expressions and disentangling them from the speech-specific mouth movements. Through quantitative and qualitative evaluation, we demonstrate that our method can synthesize high-fidelity talking face videos, achieving state-of-the-art facial expression transfer along with lip synchronization to unseen audio.