StableMamba: Distillation-free Scaling of Large SSMs for Images and Videos
作者: Hamid Suleman, Syed Talal Wasim, Muzammal Naseer, Juergen Gall
分类: cs.CV
发布日期: 2024-09-18 (更新: 2025-03-27)
💡 一句话要点
提出StableMamba,一种无需蒸馏即可扩展大规模SSM用于图像和视频任务的架构
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 Mamba Attention机制 图像分类 视频识别 可扩展性 鲁棒性 深度学习
📋 核心要点
- Mamba模型在长序列建模上表现出色,但其架构在视觉任务中扩展性受限,难以处理大规模参数。
- 论文提出Mamba-Attention交错架构,结合两者的优势,提升模型的可扩展性、鲁棒性和性能。
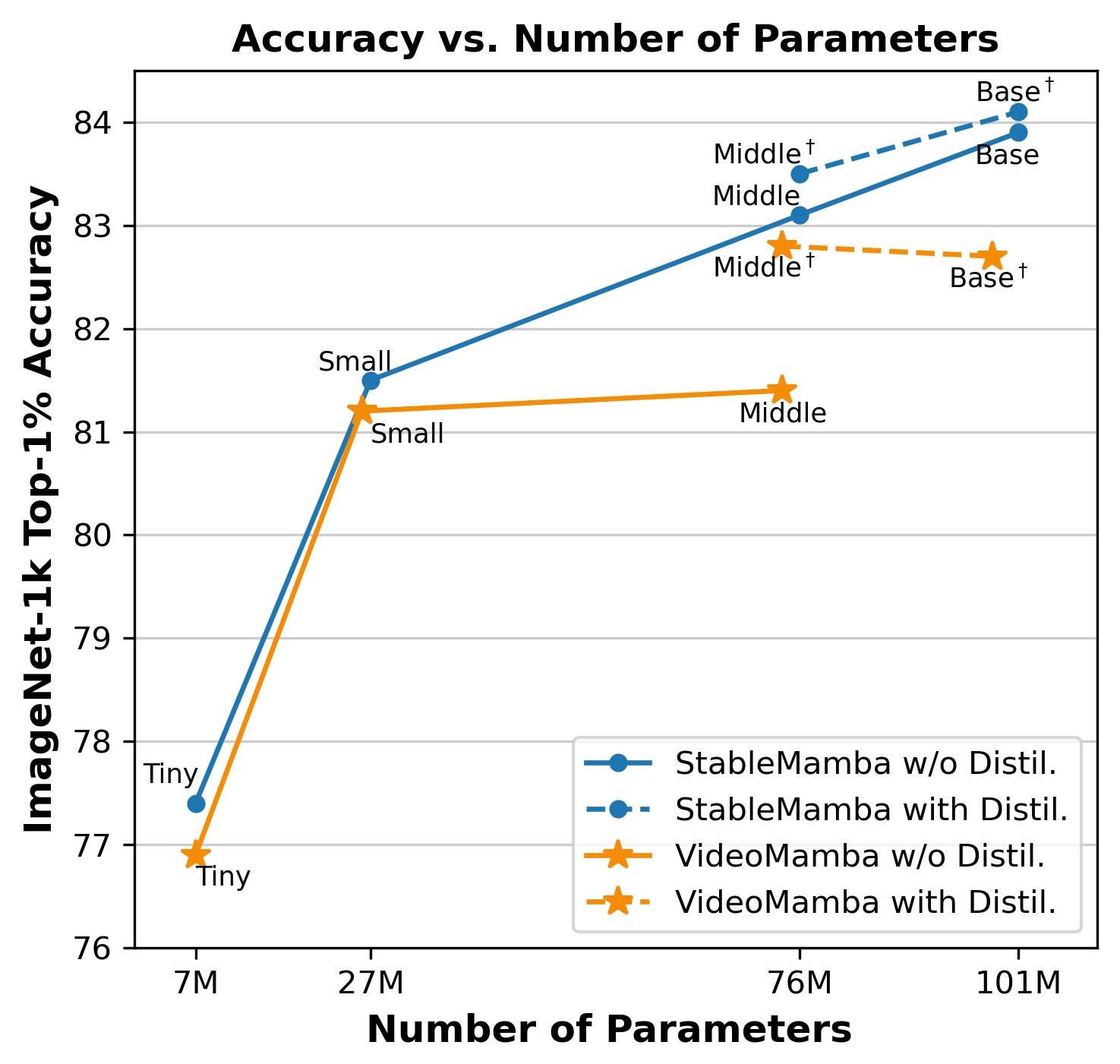
- 实验表明,该方法在图像和视频识别任务上,显著提升了现有Mamba架构的准确率,最高达+1.7%。
📝 摘要(中文)
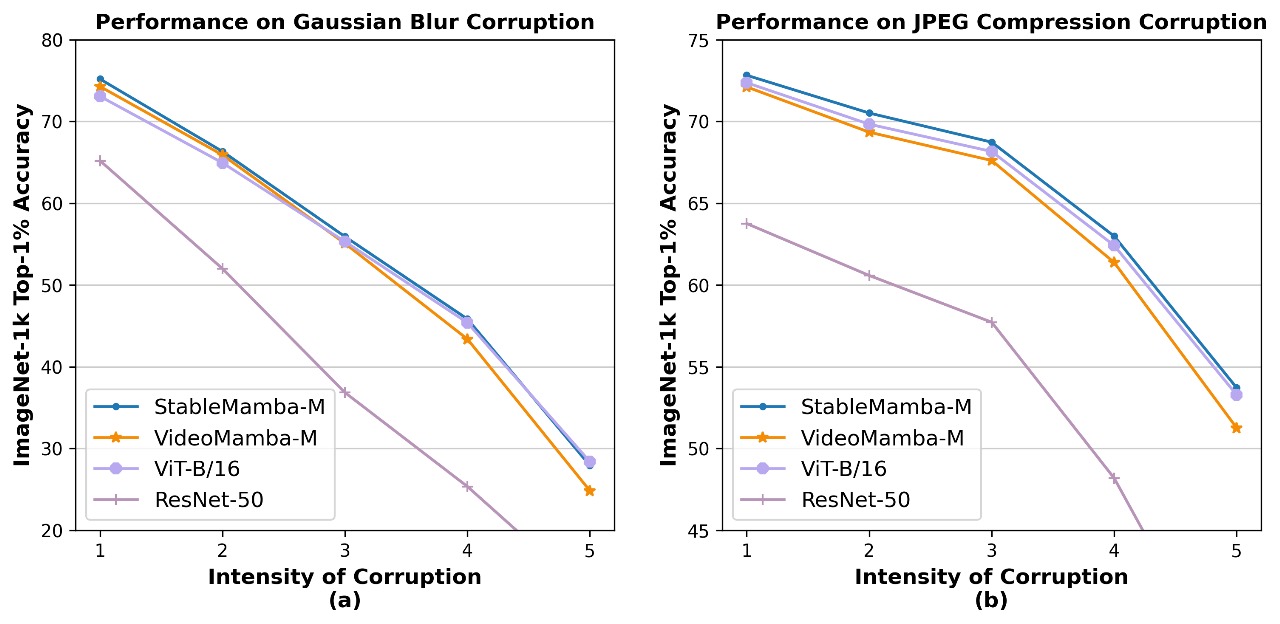
状态空间模型(SSMs),以S4为代表,通过将状态空间技术集成到深度学习中,引入了一种新颖的上下文建模方法。然而,由于其数据无关的矩阵,它们在全球上下文建模方面存在困难。Mamba模型通过S6选择性扫描算法,利用数据相关的变体解决了这个问题,增强了上下文建模,尤其是在长序列方面。然而,基于Mamba的架构在参数数量方面难以扩展,这是视觉应用的一个主要限制。本文解决了大规模SSM在图像分类和动作识别中的可扩展性问题,而不需要像知识蒸馏这样的额外技术。我们分析了基于Mamba和基于Attention的模型的独特特征,提出了一种Mamba-Attention交错架构,该架构增强了可扩展性、鲁棒性和性能。我们证明了这种稳定高效的交错架构解决了基于Mamba的架构在图像和视频方面的可扩展性问题,并提高了对常见伪像(如JPEG压缩)的鲁棒性。我们在ImageNet-1K、Kinetics-400和Something-Something-v2基准上的全面评估表明,我们的方法将最先进的基于Mamba的架构的准确性提高了高达+1.7。
🔬 方法详解
问题定义:Mamba模型在处理长序列数据时表现出色,但在视觉任务中,尤其是在需要大规模参数的情况下,其可扩展性成为一个瓶颈。现有的Mamba架构难以有效扩展到更大的模型尺寸,限制了其在图像和视频领域的应用潜力。
核心思路:论文的核心思路是结合Mamba模型和Attention机制的优势,设计一种交错的架构。Mamba擅长序列建模和捕捉局部上下文,而Attention机制擅长捕捉全局依赖关系。通过将两者交错使用,可以克服Mamba模型在全局上下文建模方面的不足,同时提高整体架构的可扩展性。
技术框架:StableMamba架构采用Mamba模块和Attention模块交替堆叠的方式。输入图像或视频首先经过一个初始的特征提取层,然后进入一系列交错的Mamba和Attention模块。每个Mamba模块负责处理序列数据并捕捉局部上下文,每个Attention模块负责捕捉全局依赖关系。最终,模型的输出经过一个分类器,得到最终的预测结果。
关键创新:该论文的关键创新在于Mamba-Attention交错架构的设计。这种设计有效地结合了Mamba和Attention机制的优点,克服了Mamba模型在全局上下文建模方面的不足,并提高了整体架构的可扩展性。此外,该架构在提高模型对常见图像伪像(如JPEG压缩)的鲁棒性方面也表现出色。
关键设计:Mamba模块采用S6选择性扫描算法,Attention模块采用标准的多头自注意力机制。Mamba和Attention模块的堆叠顺序和数量是超参数,需要根据具体任务进行调整。论文中没有明确提及损失函数的具体形式,推测使用了交叉熵损失函数进行分类任务的训练。具体的参数设置细节需要在论文原文中查找。
🖼️ 关键图片

📊 实验亮点
实验结果表明,StableMamba在ImageNet-1K图像分类、Kinetics-400和Something-Something-v2动作识别等基准测试中取得了显著的性能提升。与现有的Mamba架构相比,StableMamba的准确率提高了高达+1.7%。此外,该架构还表现出对JPEG压缩等常见图像伪像的更强鲁棒性,证明了其在实际应用中的价值。
🎯 应用场景
StableMamba架构具有广泛的应用前景,包括图像分类、目标检测、视频理解、动作识别等。其高效的可扩展性使其能够处理高分辨率图像和长视频序列,适用于智能监控、自动驾驶、医疗影像分析等领域。未来,该架构有望进一步扩展到其他模态的数据处理,例如语音识别和自然语言处理。
📄 摘要(原文)
State-space models (SSMs), exemplified by S4, have introduced a novel context modeling method by integrating state-space techniques into deep learning. However, they struggle with global context modeling due to their data-independent matrices. The Mamba model addressed this with data-dependent variants via the S6 selective-scan algorithm, enhancing context modeling, especially for long sequences. However, Mamba-based architectures are difficult to scale with respect to the number of parameters, which is a major limitation for vision applications. This paper addresses the scalability issue of large SSMs for image classification and action recognition without requiring additional techniques like knowledge distillation. We analyze the distinct characteristics of Mamba-based and Attention-based models, proposing a Mamba-Attention interleaved architecture that enhances scalability, robustness, and performance. We demonstrate that the stable and efficient interleaved architecture resolves the scalability issue of Mamba-based architectures for images and videos and increases robustness to common artifacts like JPEG compression. Our thorough evaluation on the ImageNet-1K, Kinetics-400 and Something-Something-v2 benchmarks demonstrates that our approach improves the accuracy of state-of-the-art Mamba-based architectures by up to $+1.7$.