DETECLAP: Enhancing Audio-Visual Representation Learning with Object Information
作者: Shota Nakada, Taichi Nishimura, Hokuto Munakata, Masayoshi Kondo, Tatsuya Komatsu
分类: cs.MM, cs.CV, cs.SD, eess.AS
发布日期: 2024-09-18
备注: under review
💡 一句话要点
DETECLAP:利用对象信息增强音视频表征学习,提升细粒度识别能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 音视频表征学习 多模态学习 对比学习 对象检测 自监督学习 细粒度识别 音视频检索
📋 核心要点
- 现有音视频表征学习缺乏细粒度对象识别能力,限制了其在复杂场景中的应用。
- DETECLAP通过引入音视频标签预测损失,增强模型对细粒度对象信息的感知能力。
- 实验表明,DETECLAP在音视频检索和分类任务上均取得了显著的性能提升。
📝 摘要(中文)
现有的音视频表征学习能够捕捉粗略的对象类别(例如,“动物”和“乐器”),但缺乏识别细粒度细节的能力,例如动物中的“狗”和乐器中的“长笛”。为了解决这个问题,我们提出了DETECLAP,一种利用对象信息增强音视频表征学习的方法。我们的核心思想是将音视频标签预测损失引入到现有的对比音视频掩码自编码器中,以增强其对象感知能力。为了避免昂贵的手动标注,我们使用最先进的语言-音频模型和对象检测器从音频和视觉输入中准备对象标签。我们使用VGGSound和AudioSet20K数据集评估了该方法在音视频检索和分类方面的性能。我们的方法在音频到视觉和视觉到音频检索的recall@10上分别实现了+1.5%和+1.2%的提升,并在音视频分类的准确率上实现了+0.6%的提升。
🔬 方法详解
问题定义:现有音视频表征学习方法虽然可以识别粗略的对象类别,但对于细粒度的对象识别能力不足。例如,模型可以识别出“乐器”,但难以区分“钢琴”和“吉他”。这种不足限制了模型在需要精细理解场景的任务中的应用。现有方法依赖于人工标注数据,成本高昂,难以扩展到大规模数据集。
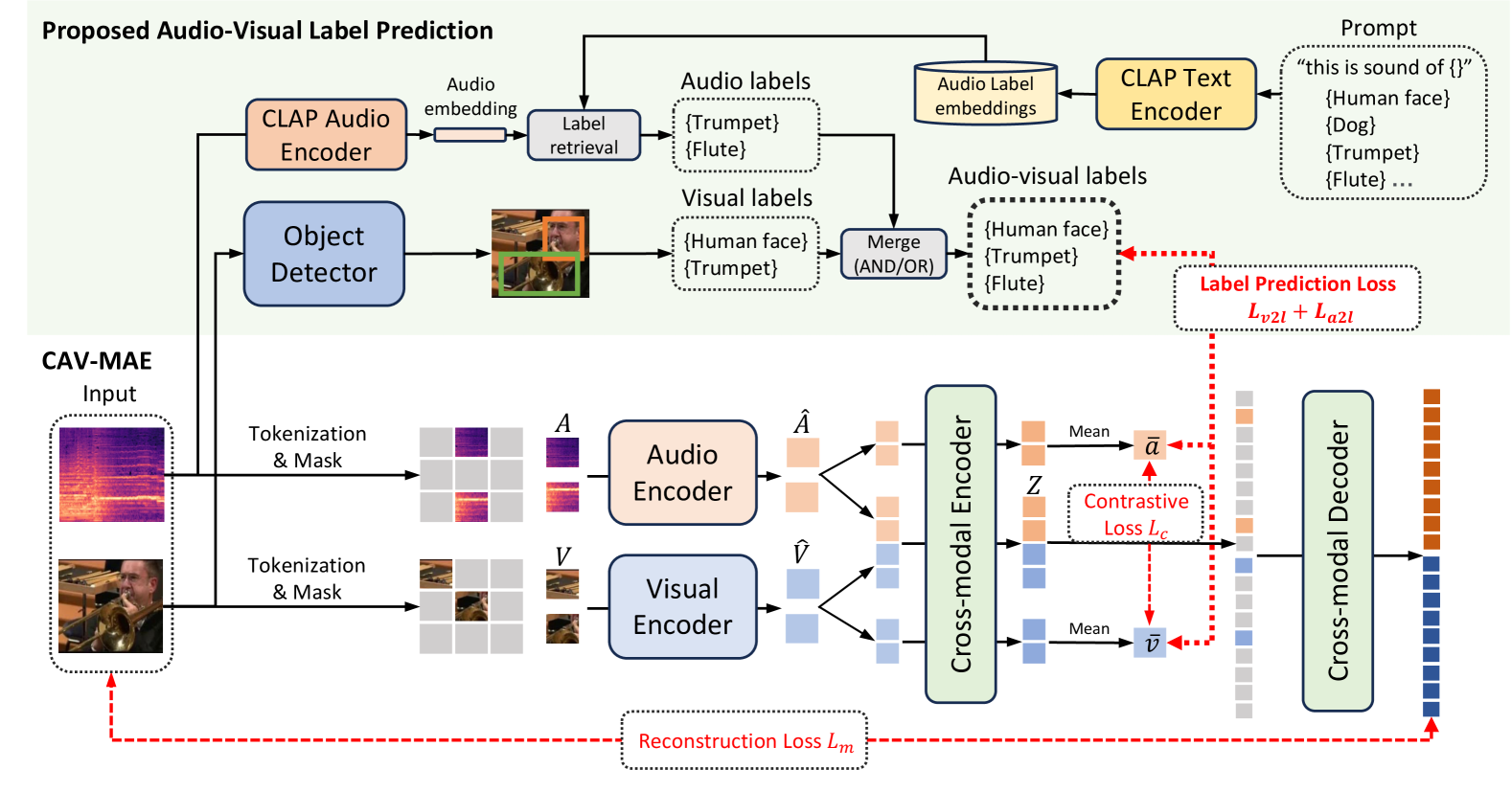
核心思路:DETECLAP的核心思路是利用对象信息增强音视频表征学习。具体来说,通过引入一个音视频标签预测损失,迫使模型学习区分不同细粒度对象的能力。为了避免人工标注,该方法利用现有的语言-音频模型和对象检测器自动生成标签。这样,模型就可以在自监督学习的过程中,学习到更丰富的对象信息。
技术框架:DETECLAP建立在Contrastive Audio-Visual Masked AutoEncoder (CAV-MAE) 的基础上。整体框架包括以下几个主要模块:1) 音频编码器和视觉编码器,用于提取音视频特征;2) 对象标签生成模块,利用语言-音频模型和对象检测器自动生成对象标签;3) 音视频标签预测模块,预测输入音视频对应的对象标签;4) 对比学习模块,利用对比学习损失学习音视频之间的关联性。
关键创新:DETECLAP的关键创新在于引入了音视频标签预测损失,并利用自动生成标签的方式避免了人工标注。与传统的对比学习方法相比,DETECLAP能够学习到更丰富的对象信息,从而提升了细粒度对象识别能力。此外,该方法利用现有的语言-音频模型和对象检测器,降低了数据标注的成本。
关键设计:DETECLAP的关键设计包括:1) 使用预训练的语言-音频模型(如CLAP)生成音频标签;2) 使用预训练的对象检测器(如DETR)生成视觉标签;3) 使用交叉熵损失作为音视频标签预测损失;4) 将音视频标签预测损失与CAV-MAE原有的对比学习损失相结合,共同优化模型。
🖼️ 关键图片
📊 实验亮点
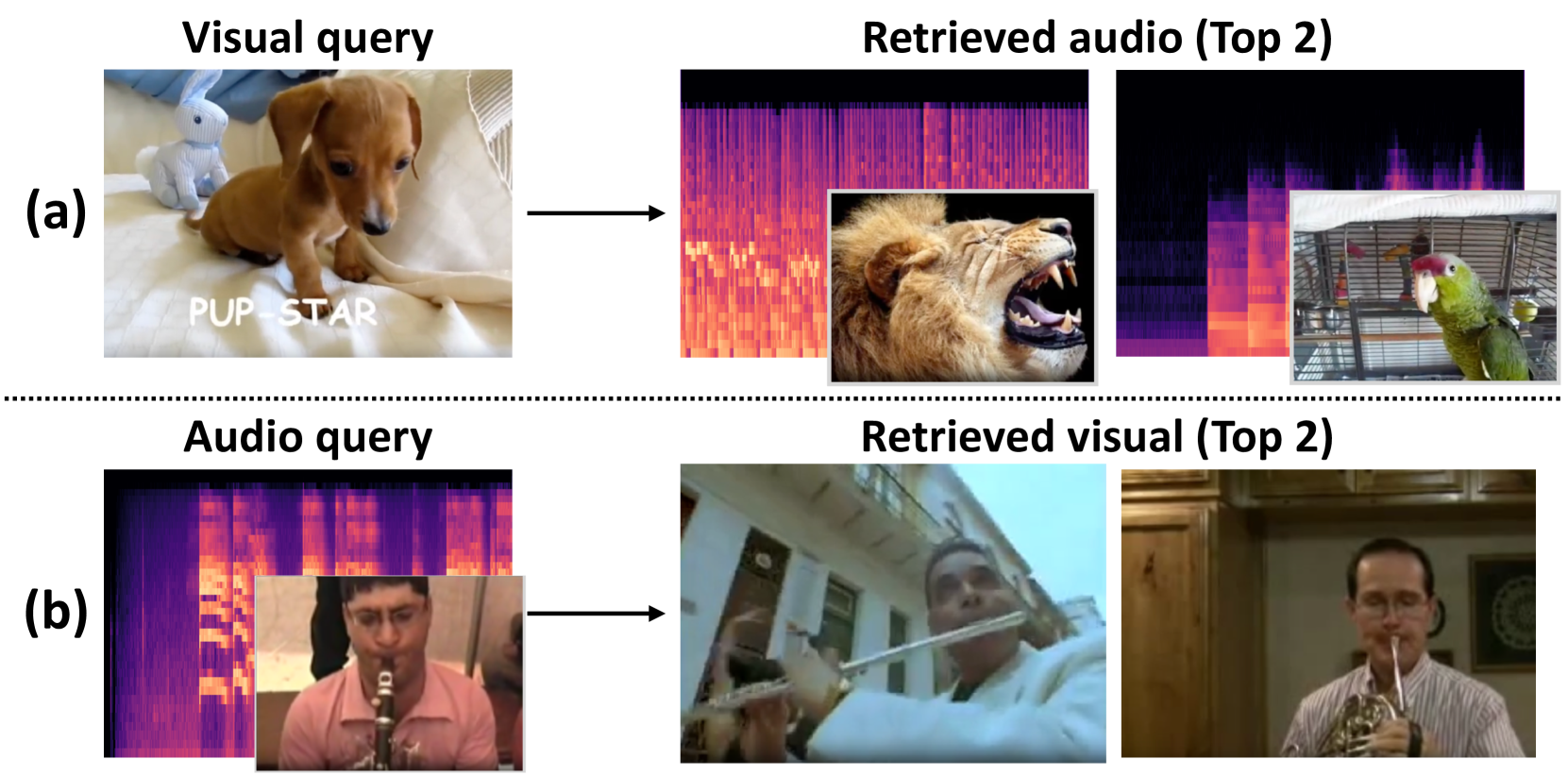
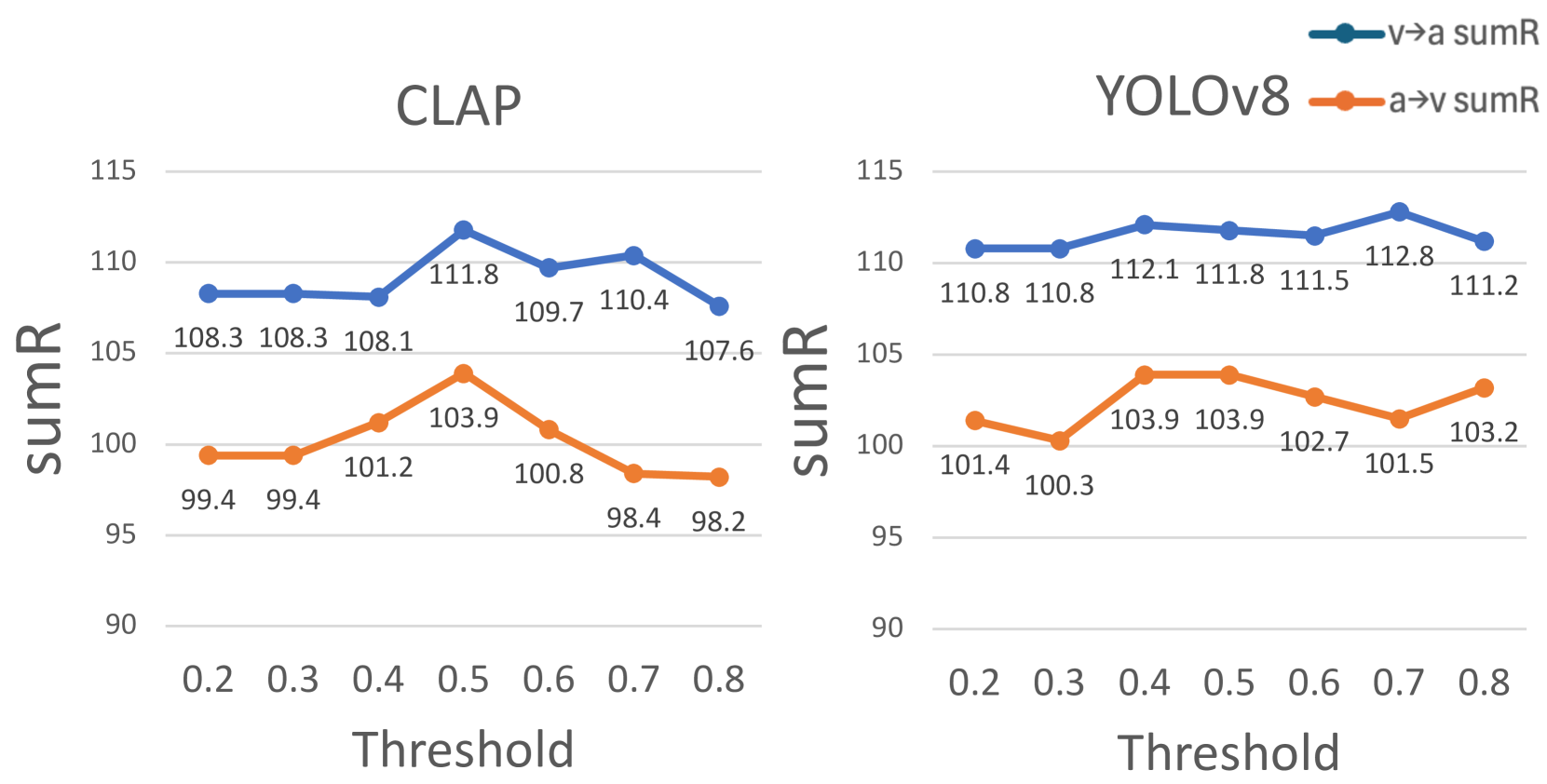
DETECLAP在VGGSound和AudioSet20K数据集上进行了评估。在音频到视觉检索任务中,recall@10提升了1.5%;在视觉到音频检索任务中,recall@10提升了1.2%;在音视频分类任务中,准确率提升了0.6%。实验结果表明,DETECLAP能够有效提升音视频表征学习的性能,尤其是在细粒度对象识别方面。
🎯 应用场景
DETECLAP可应用于智能监控、音视频内容分析、机器人感知等领域。例如,在智能监控中,可以利用DETECLAP识别异常声音和行为,提高安全预警能力。在音视频内容分析中,可以自动识别视频中的对象和声音,实现智能标签和搜索。在机器人感知中,可以帮助机器人理解周围环境,实现更智能的交互。
📄 摘要(原文)
Current audio-visual representation learning can capture rough object categories (e.g.,
animals'' andinstruments''), but it lacks the ability to recognize fine-grained details, such as specific categories likedogs'' andflutes'' within animals and instruments. To address this issue, we introduce DETECLAP, a method to enhance audio-visual representation learning with object information. Our key idea is to introduce an audio-visual label prediction loss to the existing Contrastive Audio-Visual Masked AutoEncoder to enhance its object awareness. To avoid costly manual annotations, we prepare object labels from both audio and visual inputs using state-of-the-art language-audio models and object detectors. We evaluate the method of audio-visual retrieval and classification using the VGGSound and AudioSet20K datasets. Our method achieves improvements in recall@10 of +1.5% and +1.2% for audio-to-visual and visual-to-audio retrieval, respectively, and an improvement in accuracy of +0.6% for audio-visual classification.