Playground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models
作者: Bingchen Liu, Ehsan Akhgari, Alexander Visheratin, Aleks Kamko, Linmiao Xu, Shivam Shrirao, Chase Lambert, Joao Souza, Suhail Doshi, Daiqing Li
分类: cs.CV, cs.AI, cs.GR
发布日期: 2024-09-16 (更新: 2024-10-21)
备注: Project page: https://playground.com/pg-v3
💡 一句话要点
Playground v3:利用深度融合大语言模型提升文本到图像对齐效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 大型语言模型 深度融合 图像字幕 图形设计
📋 核心要点
- 现有文本到图像模型依赖预训练语言模型,文本理解能力受限,难以生成高质量图像。
- PGv3通过深度融合大型语言模型,直接利用LLM的文本条件,提升文本理解和图像生成能力。
- PGv3在多个基准测试中达到SoTA,并在图形设计、文本渲染和多语言理解方面表现出色。
📝 摘要(中文)
本文介绍了Playground v3 (PGv3),一种最新的文本到图像模型,在多个测试基准上实现了最先进(SoTA)的性能,擅长图形设计能力,并引入了新的功能。与依赖于T5或CLIP文本编码器等预训练语言模型的传统文本到图像生成模型不同,我们的方法完全集成了大型语言模型(LLM),采用了一种新颖的结构,该结构仅利用来自仅解码器LLM的文本条件。此外,为了提高图像字幕质量,我们开发了一种内部字幕生成器,能够生成具有不同详细程度的字幕,丰富了文本结构的多样性。我们还引入了一个新的基准CapsBench来评估详细的图像字幕性能。实验结果表明,PGv3在文本提示遵循、复杂推理和准确的文本渲染方面表现出色。用户偏好研究表明,我们的模型在常见的图形设计应用(如贴纸、海报和logo设计)中具有超人的图形设计能力。此外,PGv3还引入了新的功能,包括精确的RGB颜色控制和强大的多语言理解。
🔬 方法详解
问题定义:现有的文本到图像生成模型通常依赖于预训练的语言模型,如CLIP或T5,作为文本编码器。这些模型在理解复杂文本提示、进行推理以及准确渲染文本方面存在局限性,导致生成的图像在细节和语义一致性上表现不佳。此外,生成高质量、详细的图像描述也面临挑战。
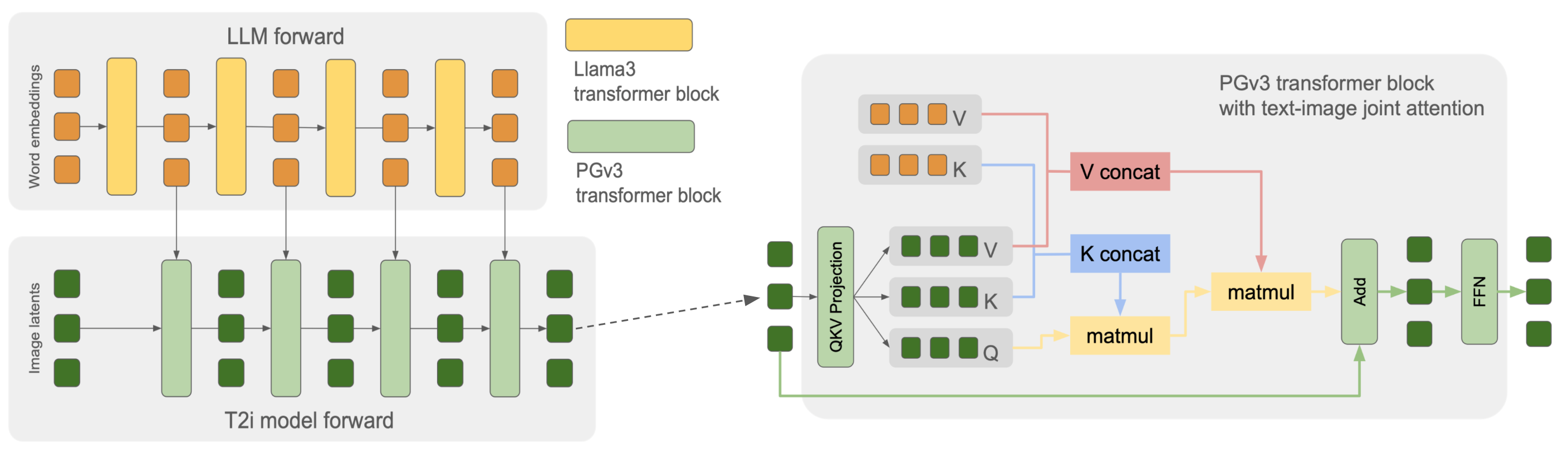
核心思路:PGv3的核心思路是将大型语言模型(LLM)深度集成到文本到图像生成流程中,直接利用LLM强大的文本理解和生成能力。通过这种方式,模型可以更好地理解复杂的文本提示,并生成更符合用户意图的图像。同时,开发高质量的图像字幕生成器,以提供更丰富和多样化的训练数据。
技术框架:PGv3的整体框架包含一个深度融合的LLM作为文本编码器,以及一个图像生成器。LLM负责处理文本提示,提取语义信息,并将其传递给图像生成器。图像生成器根据接收到的语义信息生成图像。此外,还包含一个内部开发的图像字幕生成器,用于生成高质量的图像描述,以增强训练数据的多样性。
关键创新:PGv3的关键创新在于深度融合LLM的文本编码器。与传统的文本到图像模型不同,PGv3完全依赖于LLM来处理文本信息,避免了使用预训练的文本编码器可能带来的信息损失和偏差。此外,高质量的图像字幕生成器也是一个重要的创新点,它能够生成更详细和多样化的图像描述,从而提高模型的生成能力。
关键设计:PGv3的关键设计包括LLM的选择和训练策略,图像生成器的架构,以及图像字幕生成器的设计。具体细节包括:选择合适的LLM架构(decoder-only),设计有效的融合机制将LLM的输出融入图像生成器,以及设计能够生成不同详细程度字幕的图像字幕生成器。损失函数的设计也至关重要,需要平衡文本对齐、图像质量和多样性。
🖼️ 关键图片


📊 实验亮点
PGv3在多个文本到图像生成基准测试中取得了最先进的性能。用户偏好研究表明,PGv3在图形设计任务中表现出超人的能力,尤其是在生成贴纸、海报和logo设计方面。此外,PGv3还引入了精确的RGB颜色控制和强大的多语言理解能力,进一步提升了其应用价值。
🎯 应用场景
PGv3具有广泛的应用前景,包括图形设计、广告创意、内容创作、游戏开发等领域。它可以用于生成各种视觉内容,如海报、logo、贴纸、插图等。其强大的文本理解能力和图像生成能力可以帮助用户快速创建高质量的视觉内容,提高工作效率和创作质量。此外,PGv3的多语言支持使其能够应用于全球市场。
📄 摘要(原文)
We introduce Playground v3 (PGv3), our latest text-to-image model that achieves state-of-the-art (SoTA) performance across multiple testing benchmarks, excels in graphic design abilities and introduces new capabilities. Unlike traditional text-to-image generative models that rely on pre-trained language models like T5 or CLIP text encoders, our approach fully integrates Large Language Models (LLMs) with a novel structure that leverages text conditions exclusively from a decoder-only LLM. Additionally, to enhance image captioning quality-we developed an in-house captioner, capable of generating captions with varying levels of detail, enriching the diversity of text structures. We also introduce a new benchmark CapsBench to evaluate detailed image captioning performance. Experimental results demonstrate that PGv3 excels in text prompt adherence, complex reasoning, and accurate text rendering. User preference studies indicate the super-human graphic design ability of our model for common design applications, such as stickers, posters, and logo designs. Furthermore, PGv3 introduces new capabilities, including precise RGB color control and robust multilingual understanding.