Fit and Prune: Fast and Training-free Visual Token Pruning for Multi-modal Large Language Models
作者: Weihao Ye, Qiong Wu, Wenhao Lin, Yiyi Zhou
分类: cs.CV, cs.CL, cs.MM
发布日期: 2024-09-16 (更新: 2024-12-25)
🔗 代码/项目: GITHUB
💡 一句话要点
FitPrune:一种快速且免训练的多模态大语言模型视觉Token剪枝方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉Token剪枝 免训练 注意力机制 模型加速
📋 核心要点
- MLLM使用大量视觉tokens导致计算冗余,现有token剪枝方法缺乏有效的免训练方案。
- FitPrune将token剪枝视为统计问题,通过最小化剪枝前后注意力分布的差异来确定最佳剪枝方案。
- 实验表明,FitPrune能显著降低计算复杂度,同时保持高性能,且剪枝方案生成速度快。
📝 摘要(中文)
多模态大语言模型(MLLMs)为了弥补视觉能力的不足,通常使用大量的图像tokens,这不仅存在明显的冗余,而且极大地加剧了已经很高的计算负担。Token剪枝是加速MLLMs的有效解决方案,但何时以及如何删除tokens仍然是一个挑战。本文提出了一种新颖的、免训练的方法FitPrune,用于MLLMs的有效视觉token剪枝,它可以根据预定义的预算快速生成MLLMs的完整剪枝方案。具体来说,FitPrune将token剪枝视为MLLM的统计问题,其目标是找到一种最优的剪枝方案,以最小化剪枝前后注意力分布的差异。在实践中,FitPrune可以基于少量推理数据的注意力统计快速完成,避免了MLLMs的昂贵试验。根据剪枝方案,MLLM可以直接删除推理过程中不同示例的冗余视觉tokens。为了验证FitPrune,我们将其应用于一系列最新的MLLMs,包括LLaVA-1.5、LLaVA-HR和LLaVA-NEXT,并在多个基准数据集上进行了广泛的实验。实验结果表明,我们的FitPrune不仅可以大幅降低计算复杂度,同时保持高性能,例如,LLaVA-NEXT的FLOPs降低了54.9%,而精度仅下降了0.5%。值得注意的是,剪枝方案可以在大约5分钟内获得。代码已开源。
🔬 方法详解
问题定义:多模态大语言模型(MLLMs)为了提升视觉理解能力,通常会使用大量的视觉tokens。然而,这些tokens中存在大量的冗余信息,导致计算资源的浪费。现有的token剪枝方法通常需要大量的训练或微调,计算成本高昂,且难以快速适应不同的模型和任务。因此,如何高效且免训练地进行视觉token剪枝是本文要解决的核心问题。
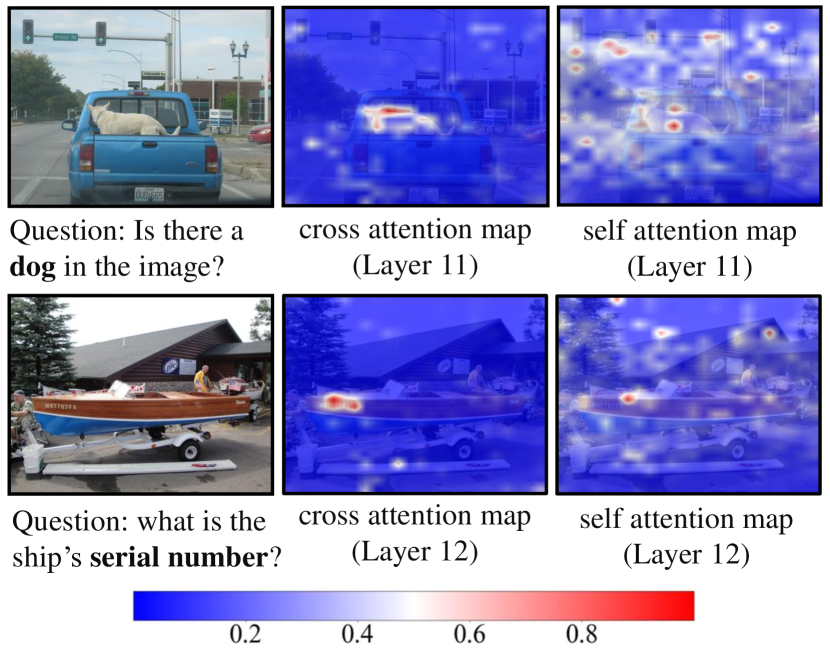
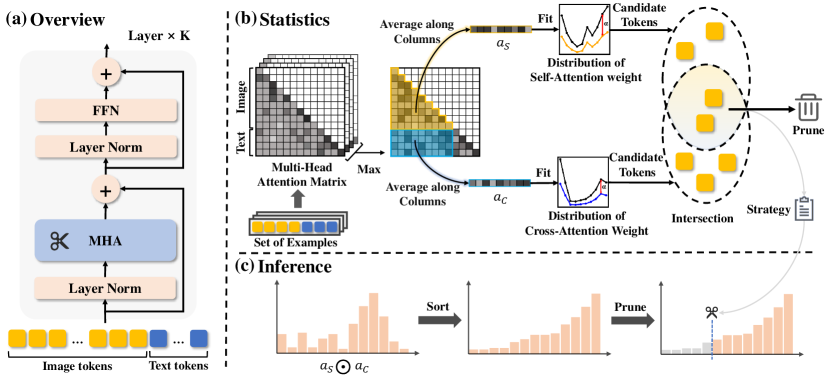
核心思路:FitPrune的核心思路是将token剪枝问题转化为一个统计优化问题。其基本假设是:重要的视觉tokens应该对模型的注意力分布产生显著影响,而冗余的tokens则影响较小。因此,通过最小化剪枝前后注意力分布的差异,可以找到一组最优的tokens子集,从而实现高效的剪枝。这种方法避免了昂贵的训练过程,并且能够快速适应不同的模型和任务。
技术框架:FitPrune的技术框架主要包括以下几个步骤:1) 注意力统计:使用少量推理数据,统计MLLM中每个视觉token的注意力分布。2) 差异度量:定义一种度量方式来衡量剪枝前后注意力分布的差异,例如KL散度。3) 优化求解:根据预定义的计算预算,通过优化算法(例如贪心算法)找到一组tokens子集,使得剪枝后的注意力分布与原始分布的差异最小。4) 剪枝实施:根据优化结果,直接移除冗余的视觉tokens。
关键创新:FitPrune最重要的技术创新点在于其免训练的特性。与传统的token剪枝方法相比,FitPrune不需要任何训练或微调过程,而是直接基于注意力统计进行剪枝。这大大降低了计算成本,并且使得该方法能够快速应用于不同的MLLMs。此外,FitPrune将token剪枝问题转化为一个统计优化问题,为token剪枝提供了一个新的视角。
关键设计:FitPrune的关键设计包括:1) 注意力统计方法:如何有效地统计视觉tokens的注意力分布,例如使用平均注意力权重或最大注意力权重。2) 差异度量函数:如何选择合适的差异度量函数来衡量剪枝前后注意力分布的差异,例如KL散度、JS散度等。3) 优化算法:如何选择合适的优化算法来找到最优的tokens子集,例如贪心算法、动态规划等。4) 计算预算:如何根据实际需求设置合理的计算预算,例如FLOPs减少比例、tokens数量减少比例等。
🖼️ 关键图片
📊 实验亮点
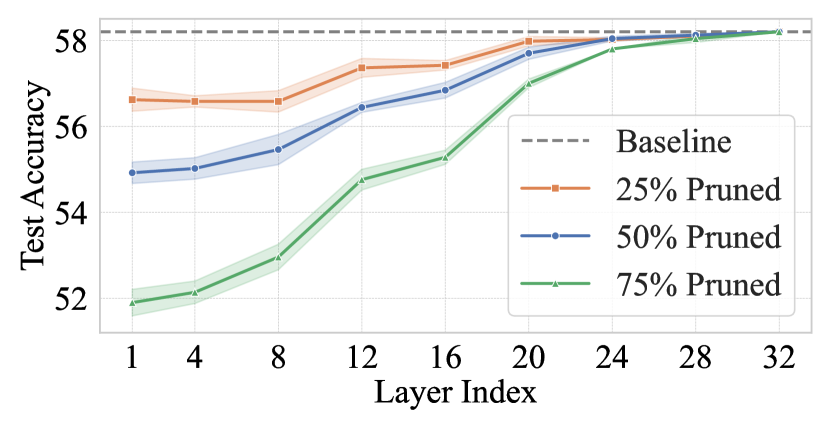
FitPrune在LLaVA-NEXT上实现了显著的性能提升,FLOPs降低了54.9%,而精度仅下降了0.5%。在LLaVA-1.5和LLaVA-HR等模型上也取得了类似的效果。值得注意的是,FitPrune的剪枝方案可以在大约5分钟内获得,大大缩短了模型部署的时间。这些实验结果表明,FitPrune是一种高效且实用的视觉token剪枝方法。
🎯 应用场景
FitPrune可广泛应用于各种多模态大语言模型,尤其是在资源受限的场景下,如移动设备或边缘计算平台。通过降低计算复杂度,FitPrune能够加速模型推理,提高用户体验。此外,该方法还可以用于模型压缩和知识蒸馏,为多模态大语言模型的发展提供新的思路。
📄 摘要(原文)
Recent progress in Multimodal Large Language Models(MLLMs) often use large image tokens to compensate the visual shortcoming of MLLMs, which not only exhibits obvious redundancy but also greatly exacerbates the already high computation. Token pruning is an effective solution for speeding up MLLMs, but when and how to drop tokens still remains a challenge. In this paper, we propose a novel and training-free approach for the effective visual token pruning of MLLMs, termed FitPrune, which can quickly produce a complete pruning recipe for MLLMs according to a pre-defined budget. Specifically, FitPrune considers token pruning as a statistical problem of MLLM and its objective is to find out an optimal pruning scheme that can minimize the divergence of the attention distributions before and after pruning. In practice, FitPrune can be quickly accomplished based on the attention statistics from a small batch of inference data, avoiding the expensive trials of MLLMs. According to the pruning recipe, an MLLM can directly remove the redundant visual tokens of different examples during inference. To validate FitPrune, we apply it to a set of recent MLLMs, including LLaVA-1.5, LLaVA-HR and LLaVA-NEXT, and conduct extensive experiments on a set of benchmarks. The experimental results show that our FitPrune can not only reduce the computational complexity to a large extent, while retaining high performance, e.g., -54.9% FLOPs for LLaVA-NEXT with only 0.5% accuracy drop. Notably, the pruning recipe can be obtained in about 5 minutes. Our code is available at https://github.com/ywh187/FitPrune.