PrimeDepth: Efficient Monocular Depth Estimation with a Stable Diffusion Preimage
作者: Denis Zavadski, Damjan Kalšan, Carsten Rother
分类: cs.CV
发布日期: 2024-09-13
💡 一句话要点
PrimeDepth:利用稳定扩散预图像实现高效单目深度估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单目深度估计 零样本学习 稳定扩散 预图像 深度图细化
📋 核心要点
- 现有基于扩散模型的单目深度估计方法,虽然效果好,但由于迭代去噪过程,测试效率极低。
- PrimeDepth通过从Stable Diffusion中提取单步去噪后的预图像特征,并使用细化网络,显著提升了效率。
- 实验表明,PrimeDepth比Marigold快两个数量级,且在精度上略有提升,与Depth Anything互补。
📝 摘要(中文)
本文致力于解决零样本单目深度估计问题。最近的研究表明,利用文本到图像的预训练模型(如Stable Diffusion)是一个有效的方法。这些模型提供了丰富的通用图像表示,因此只需少量训练数据即可将其转化为深度估计模型,从而预测出高度精细的深度图并具有良好的泛化能力。然而,现有方法由于其迭代去噪过程,在测试时效率非常低。本文提出了一种不同的实现方式,即PrimeDepth,该方法在保持甚至增强基于扩散方法优点的同时,显著提高了测试效率。我们的核心思想是从Stable Diffusion中提取丰富的图像表示(称为预图像),只需运行单个去噪步骤即可获得。然后,将此预图像输入到具有架构归纳偏置的细化网络中,再进行下游任务。实验结果表明,PrimeDepth比领先的基于扩散的方法Marigold快两个数量级,同时在具有挑战性的场景中更稳健,并且在定量上略胜一筹。因此,我们缩小了与当前领先的数据驱动方法Depth Anything之间的差距,后者在定量上仍然更优越,但预测的深度图细节较少,并且需要20倍以上的标注数据。由于我们方法的互补性,即使简单地平均PrimeDepth和Depth Anything的预测结果,也可以改进这两种方法,并在零样本单目深度估计中达到新的state-of-the-art。未来,数据驱动的方法也可能受益于集成我们的预图像。
🔬 方法详解
问题定义:论文旨在解决零样本单目深度估计问题。现有基于扩散模型的方法,如Marigold,虽然能够生成高质量的深度图,但由于其依赖于迭代的去噪过程,计算成本高昂,推理速度慢,难以实际应用。
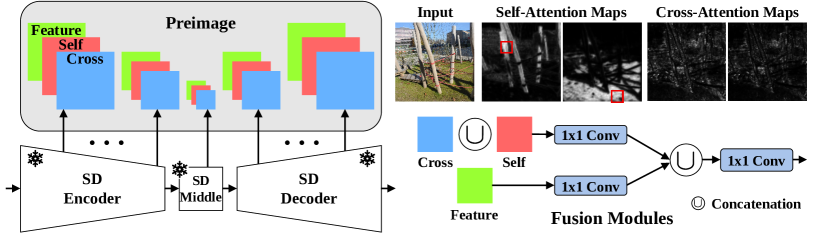
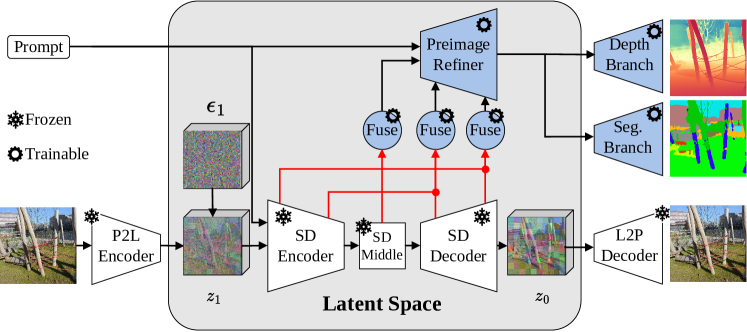
核心思路:PrimeDepth的核心思路是利用Stable Diffusion模型强大的图像表示能力,但避免其耗时的迭代去噪过程。通过提取Stable Diffusion模型单步去噪后的“预图像”(preimage)特征,作为输入图像的丰富表示,然后使用一个轻量级的细化网络来预测最终的深度图。
技术框架:PrimeDepth的整体框架包括两个主要阶段:1) 预图像提取阶段:输入图像首先被送入预训练的Stable Diffusion模型,仅执行一次去噪步骤,提取出预图像特征。2) 深度图细化阶段:提取的预图像特征被输入到一个细化网络中,该网络具有特定的架构归纳偏置,用于预测最终的深度图。
关键创新:PrimeDepth的关键创新在于利用Stable Diffusion模型的单步去噪结果作为图像的表示,避免了完整的迭代去噪过程,从而显著提高了推理速度。与现有方法相比,PrimeDepth在保持甚至提升深度图质量的同时,实现了数量级的速度提升。
关键设计:细化网络的设计是PrimeDepth的关键组成部分。论文中可能采用了特定的网络结构,例如U-Net或Transformer-based的架构,以有效地利用预图像特征并预测高质量的深度图。损失函数的设计也至关重要,可能包括深度图的L1损失、梯度损失等,以保证深度图的准确性和细节。
🖼️ 关键图片

📊 实验亮点
PrimeDepth在零样本单目深度估计任务中取得了显著的成果。实验表明,PrimeDepth比Marigold快两个数量级,同时在精度上略有提升。与Depth Anything相比,PrimeDepth在速度上更具优势,并且生成的深度图细节更丰富。简单地平均PrimeDepth和Depth Anything的预测结果,可以进一步提升性能,达到新的state-of-the-art。
🎯 应用场景
PrimeDepth在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。它可以为这些应用提供高效、准确的单目深度估计,无需大量的训练数据。该方法还可以作为其他数据驱动方法的补充,进一步提升深度估计的性能。
📄 摘要(原文)
This work addresses the task of zero-shot monocular depth estimation. A recent advance in this field has been the idea of utilising Text-to-Image foundation models, such as Stable Diffusion. Foundation models provide a rich and generic image representation, and therefore, little training data is required to reformulate them as a depth estimation model that predicts highly-detailed depth maps and has good generalisation capabilities. However, the realisation of this idea has so far led to approaches which are, unfortunately, highly inefficient at test-time due to the underlying iterative denoising process. In this work, we propose a different realisation of this idea and present PrimeDepth, a method that is highly efficient at test time while keeping, or even enhancing, the positive aspects of diffusion-based approaches. Our key idea is to extract from Stable Diffusion a rich, but frozen, image representation by running a single denoising step. This representation, we term preimage, is then fed into a refiner network with an architectural inductive bias, before entering the downstream task. We validate experimentally that PrimeDepth is two orders of magnitude faster than the leading diffusion-based method, Marigold, while being more robust for challenging scenarios and quantitatively marginally superior. Thereby, we reduce the gap to the currently leading data-driven approach, Depth Anything, which is still quantitatively superior, but predicts less detailed depth maps and requires 20 times more labelled data. Due to the complementary nature of our approach, even a simple averaging between PrimeDepth and Depth Anything predictions can improve upon both methods and sets a new state-of-the-art in zero-shot monocular depth estimation. In future, data-driven approaches may also benefit from integrating our preimage.