Causal Transformer for Fusion and Pose Estimation in Deep Visual Inertial Odometry
作者: Yunus Bilge Kurt, Ahmet Akman, A. Aydın Alatan
分类: cs.CV
发布日期: 2024-09-13
备注: Accepted to ECCV 2024 2nd Workshop on Vision-Centric Autonomous Driving (VCAD)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于因果Transformer的视觉惯性融合方法VIFT,提升单目视觉惯性里程计的位姿估计精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉惯性里程计 Transformer 位姿估计 深度学习 传感器融合
📋 核心要点
- 现有基于RNN的视觉惯性里程计方法在利用历史信息方面存在局限性,影响了位姿估计的准确性。
- 提出一种因果视觉惯性融合Transformer (VIFT),利用Transformer的注意力机制,更好地融合视觉和惯性信息,提升位姿估计精度。
- 实验结果表明,VIFT在KITTI数据集上取得了state-of-the-art的性能,验证了该方法在单目视觉惯性里程计中的有效性。
📝 摘要(中文)
本文提出了一种用于深度视觉惯性里程计中位姿估计的因果视觉惯性融合Transformer (VIFT)。该研究旨在利用Transformer中的注意力机制来提高位姿估计的准确性,与基于循环神经网络(RNN)的现有方法相比,Transformer能更好地利用历史数据。为了解决Transformer通常需要大规模数据进行训练的问题,本文利用了深度VIO网络的归纳偏置。由于潜在的视觉惯性特征向量包含了位姿估计的关键信息,因此本文采用Transformer通过时序更新潜在向量来优化位姿估计。此外,本文还研究了在视觉惯性里程计的监督端到端学习中,数据不平衡和旋转学习方法的影响,通过在SE(3)群元素的反向传播中使用专门的梯度。所提出的方法是端到端可训练的,并且在推理过程中只需要一个单目相机和IMU。实验结果表明,VIFT提高了单目VIO网络的精度,与KITTI数据集上的先前方法相比,实现了最先进的结果。代码将在https://github.com/ybkurt/VIFT上提供。
🔬 方法详解
问题定义:现有的基于RNN的视觉惯性里程计方法在处理长序列数据时,由于RNN的固有缺陷,难以充分利用历史信息,导致位姿估计精度受限。此外,Transformer通常需要大量数据进行训练,这对于视觉惯性里程计任务来说是一个挑战。
核心思路:本文的核心思路是利用Transformer的注意力机制来更好地融合视觉和惯性信息,从而提高位姿估计的准确性。通过将视觉和惯性特征向量作为Transformer的输入,并利用注意力机制来学习它们之间的时序依赖关系,可以更有效地利用历史信息,从而提高位姿估计的精度。同时,利用归纳偏置来减少Transformer对大量数据的需求。
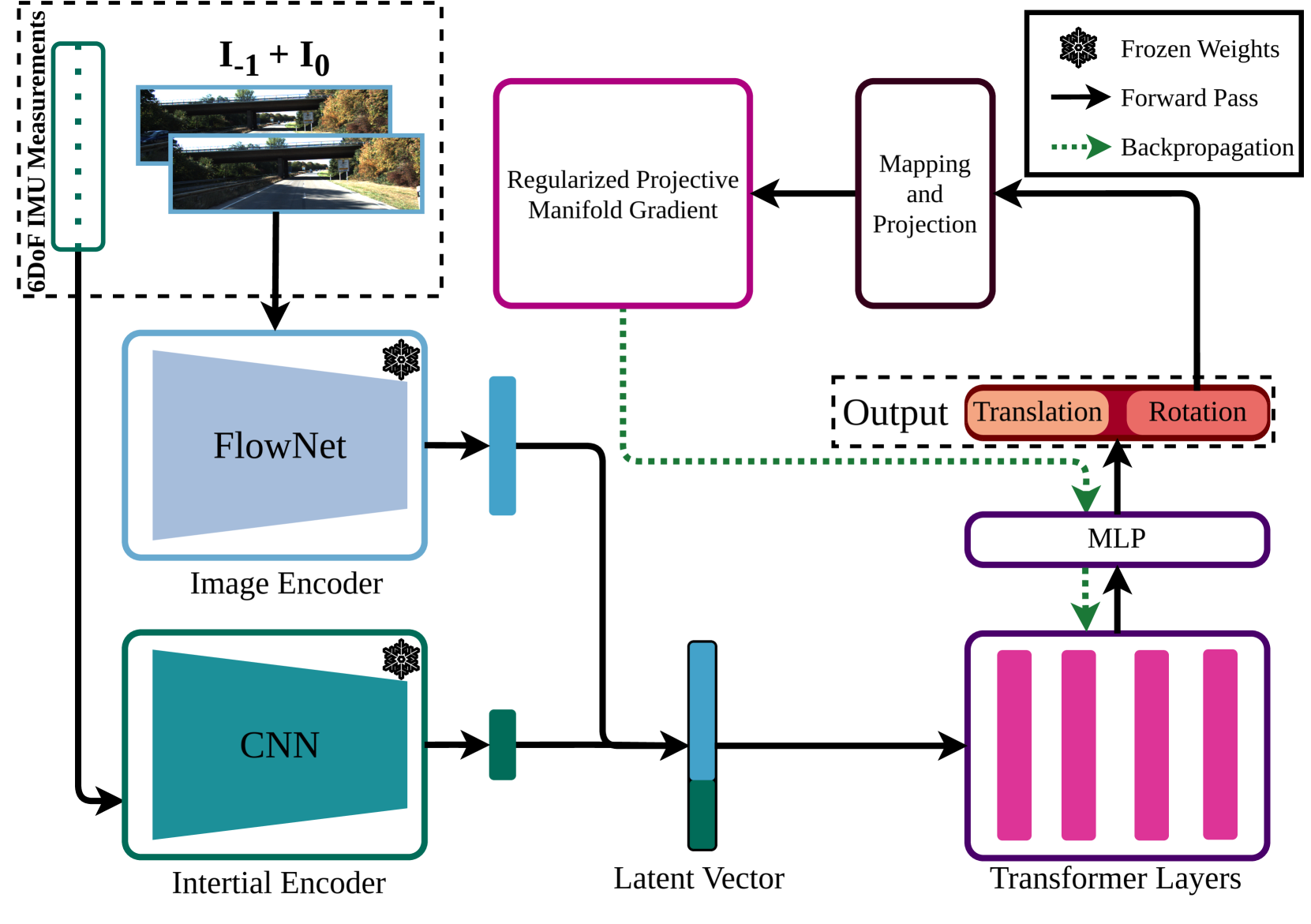
技术框架:VIFT的整体架构包括以下几个主要模块:1) 视觉特征提取模块:用于从单目图像中提取视觉特征。2) 惯性特征提取模块:用于从IMU数据中提取惯性特征。3) 视觉惯性融合模块:将视觉和惯性特征进行融合,得到融合后的特征向量。4) Transformer模块:利用Transformer的注意力机制来学习融合后的特征向量的时序依赖关系。5) 位姿估计模块:根据Transformer的输出,估计相机的位姿。
关键创新:本文最重要的技术创新点在于将Transformer引入到视觉惯性里程计任务中,并设计了一种因果Transformer结构,使其能够更好地处理时序数据。与传统的RNN方法相比,Transformer能够更好地捕捉长距离依赖关系,从而提高位姿估计的精度。此外,本文还利用了归纳偏置来减少Transformer对大量数据的需求。
关键设计:在网络结构方面,采用了因果Transformer,保证了信息流的因果性,避免了使用未来信息。在损失函数方面,针对SE(3)群的特殊性,使用了专门的梯度来优化旋转部分的学习,并考虑了数据不平衡问题。具体参数设置在论文中有详细描述,例如Transformer的层数、注意力头的数量等。
🖼️ 关键图片

📊 实验亮点
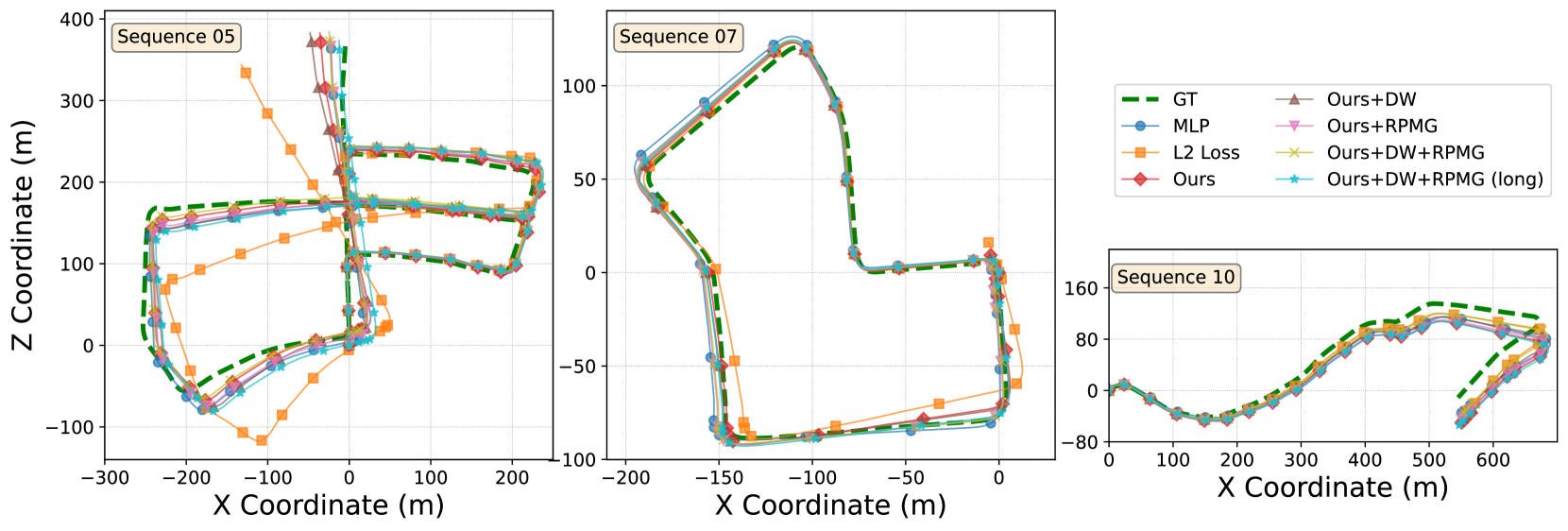
实验结果表明,VIFT在KITTI数据集上取得了state-of-the-art的性能,显著提高了单目视觉惯性里程计的位姿估计精度。与之前的最佳方法相比,VIFT在多个指标上都取得了明显的提升,验证了该方法在单目视觉惯性里程计中的有效性。具体性能数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于机器人导航、增强现实、无人机等领域。通过提高视觉惯性里程计的精度,可以提升机器人在复杂环境中的定位和导航能力,为相关应用提供更可靠的基础。未来,该方法有望扩展到其他多传感器融合场景,例如激光雷达和视觉的融合。
📄 摘要(原文)
In recent years, transformer-based architectures become the de facto standard for sequence modeling in deep learning frameworks. Inspired by the successful examples, we propose a causal visual-inertial fusion transformer (VIFT) for pose estimation in deep visual-inertial odometry. This study aims to improve pose estimation accuracy by leveraging the attention mechanisms in transformers, which better utilize historical data compared to the recurrent neural network (RNN) based methods seen in recent methods. Transformers typically require large-scale data for training. To address this issue, we utilize inductive biases for deep VIO networks. Since latent visual-inertial feature vectors encompass essential information for pose estimation, we employ transformers to refine pose estimates by updating latent vectors temporally. Our study also examines the impact of data imbalance and rotation learning methods in supervised end-to-end learning of visual inertial odometry by utilizing specialized gradients in backpropagation for the elements of SE$(3)$ group. The proposed method is end-to-end trainable and requires only a monocular camera and IMU during inference. Experimental results demonstrate that VIFT increases the accuracy of monocular VIO networks, achieving state-of-the-art results when compared to previous methods on the KITTI dataset. The code will be made available at https://github.com/ybkurt/VIFT.