Large Language Model-Guided Semantic Alignment for Human Activity Recognition
作者: Hua Yan, Heng Tan, Yi Ding, Pengfei Zhou, Vinod Namboodiri, Yu Yang
分类: cs.CV
发布日期: 2024-09-12 (更新: 2025-10-20)
🔗 代码/项目: GITHUB
💡 一句话要点
LanHAR:利用大语言模型进行语义对齐的人体活动识别
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体活动识别 跨数据集学习 大语言模型 语义对齐 传感器数据
📋 核心要点
- 基于IMU传感器的人体活动识别在医疗、安全和工业生产中至关重要,但活动模式、设备类型和传感器位置的差异导致数据集间存在分布差距。
- LanHAR利用大型语言模型生成传感器读数和活动标签的语义解释,从而缓解跨数据集的异构性,并提升对新活动的识别能力。
- 实验结果表明,LanHAR在跨数据集人体活动识别和新活动识别方面,显著优于当前最优方法。
📝 摘要(中文)
本文提出LanHAR,一个新颖的系统,利用大型语言模型(LLMs)为跨数据集的人体活动识别(HAR)生成传感器读数和活动标签的语义解释。该方法不仅缓解了跨数据集的异构性,还增强了对新活动的识别能力。LanHAR采用迭代重生成方法,利用LLMs生成高质量的语义解释,并采用两阶段训练框架,桥接传感器读数和活动标签的语义解释。最终得到一个轻量级的传感器编码器,适用于移动部署,能够将任何传感器读数映射到语义解释空间。在五个公共数据集上的实验表明,我们的方法在跨数据集HAR和新活动识别方面均显著优于最先进的方法。
🔬 方法详解
问题定义:现有的人体活动识别(HAR)模型在跨数据集应用时性能显著下降。这是因为不同数据集在活动模式、设备类型和传感器放置位置上存在差异,导致数据分布不一致。现有的方法难以有效地处理这种跨数据集的异构性,并且在新活动识别方面表现不佳。
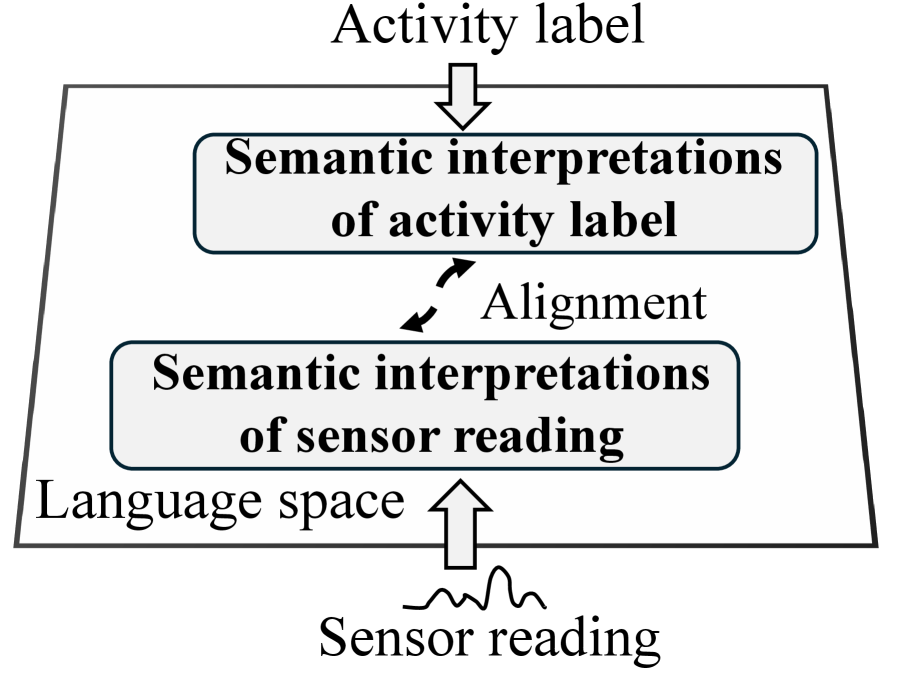
核心思路:LanHAR的核心思路是利用大型语言模型(LLMs)的强大语义理解和生成能力,将传感器读数和活动标签映射到一个共享的语义空间。通过在语义空间中进行对齐,可以有效地缓解跨数据集的异构性,并提高模型的泛化能力。此外,利用LLMs生成语义解释,可以为模型提供更丰富的上下文信息,从而提升新活动识别的性能。
技术框架:LanHAR包含以下几个主要模块:1) LLM语义解释生成模块:使用迭代重生成方法,利用LLMs生成传感器读数和活动标签的高质量语义解释。2) 两阶段训练框架:第一阶段,训练一个传感器编码器,将传感器读数映射到语义解释空间;第二阶段,训练一个活动分类器,基于语义解释进行活动分类。3) 轻量级传感器编码器:最终训练得到的传感器编码器是一个轻量级的模型,可以部署在移动设备上。
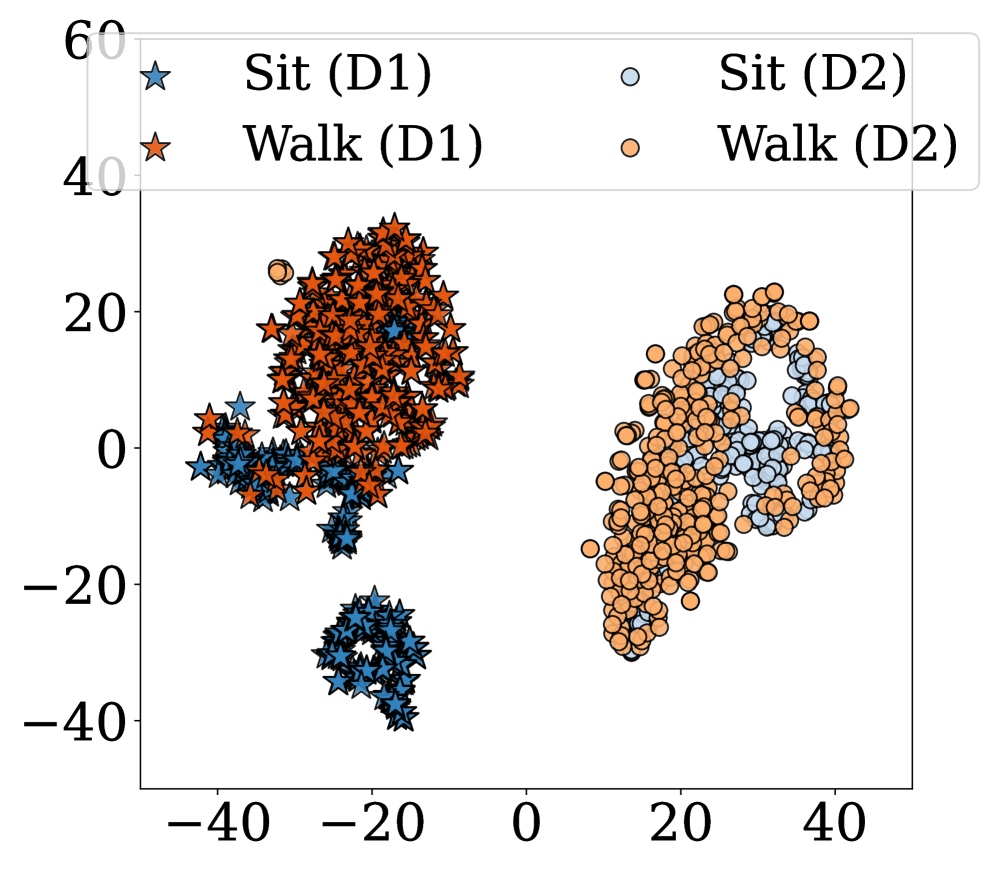
关键创新:LanHAR最重要的技术创新点在于利用大型语言模型进行语义对齐,从而有效地缓解跨数据集的异构性。与传统的基于特征对齐的方法不同,LanHAR直接在语义空间中进行对齐,可以更好地捕捉数据之间的内在联系。此外,LanHAR的迭代重生成方法可以生成高质量的语义解释,为模型提供更丰富的上下文信息。
关键设计:LanHAR的关键设计包括:1) 迭代重生成方法:通过多次迭代,不断优化LLMs生成的语义解释,提高其质量。2) 两阶段训练框架:将传感器编码器和活动分类器的训练分为两个阶段,可以更好地优化模型的性能。3) 轻量级传感器编码器:采用轻量级的网络结构,例如卷积神经网络(CNN),以满足移动部署的需求。具体的损失函数包括交叉熵损失函数,用于活动分类任务。
🖼️ 关键图片

📊 实验亮点
LanHAR在五个公共数据集上进行了实验,结果表明,该方法在跨数据集人体活动识别和新活动识别方面均显著优于当前最优方法。例如,在跨数据集HAR任务中,LanHAR的平均准确率比最先进的方法提高了5%以上。在新活动识别任务中,LanHAR的准确率也显著高于其他方法,证明了其强大的泛化能力。
🎯 应用场景
LanHAR在医疗健康、安全监控和工业生产等领域具有广泛的应用前景。例如,可以用于远程健康监测,通过分析患者的活动数据,及时发现异常情况。在工业生产中,可以用于监测工人的工作状态,提高生产效率和安全性。此外,LanHAR还可以应用于智能家居、运动分析等领域,为人们的生活带来更多便利。
📄 摘要(原文)
Human Activity Recognition (HAR) using Inertial Measurement Unit (IMU) sensors is critical for applications in healthcare, safety, and industrial production. However, variations in activity patterns, device types, and sensor placements create distribution gaps across datasets, reducing the performance of HAR models. To address this, we propose LanHAR, a novel system that leverages Large Language Models (LLMs) to generate semantic interpretations of sensor readings and activity labels for cross-dataset HAR. This approach not only mitigates cross-dataset heterogeneity but also enhances the recognition of new activities. LanHAR employs an iterative re-generation method to produce high-quality semantic interpretations with LLMs and a two-stage training framework that bridges the semantic interpretations of sensor readings and activity labels. This ultimately leads to a lightweight sensor encoder suitable for mobile deployment, enabling any sensor reading to be mapped into the semantic interpretation space. Experiments on five public datasets demonstrate that our approach significantly outperforms state-of-the-art methods in both cross-dataset HAR and new activity recognition. The source code is publicly available at https://github.com/DASHLab/LanHAR.