Real-time Multi-view Omnidirectional Depth Estimation for Real Scenarios based on Teacher-Student Learning with Unlabeled Data
作者: Ming Li, Xiong Yang, Chaofan Wu, Jiaheng Li, Pinzhi Wang, Xuejiao Hu, Sidan Du, Yang Li
分类: cs.CV, cs.RO
发布日期: 2024-09-12 (更新: 2025-11-09)
💡 一句话要点
提出Rt-OmniMVS,一种基于教师-学生学习的实时多视角全景深度估计方法,适用于真实场景。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 全景深度估计 多视角立体视觉 教师-学生学习 边缘计算 实时性 无监督学习 数据增强 鱼眼相机
📋 核心要点
- 现有全景深度估计方法难以在边缘设备上实现实时性,且在真实场景中泛化能力不足。
- 采用教师-学生学习策略,利用高精度立体匹配模型生成伪标签,并结合数据增强提升模型性能。
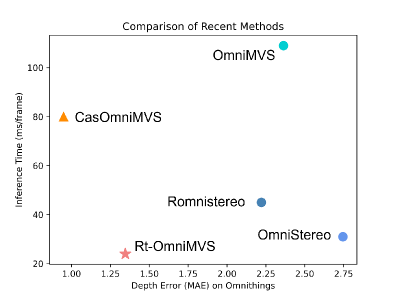
- 提出的Rt-OmniMVS在边缘计算平台上实现了15FPS的推理速度,并在真实场景中表现出高精度。
📝 摘要(中文)
全景深度估计能够实现360度范围内的有效三维感知。然而,在自动驾驶和机器人等实际应用中,现有算法在实现实时性能和鲁棒的跨场景泛化方面仍然面临重大挑战。本文提出了一种名为Rt-OmniMVS的实时全景深度估计方法,用于边缘计算平台。该方法引入了组合球面扫描方法,并实现了轻量级网络结构,以在边缘计算平台上实现实时性能。为了在真实环境中实现高精度、鲁棒性和泛化能力,我们引入了一种教师-学生学习策略。我们利用高精度立体匹配方法作为教师模型,为未标记的真实世界数据预测伪标签,并利用数据和模型增强技术进行训练,以提高学生模型Rt-OmniMVS的性能。我们还提出了HexaMODE,一种基于多视角鱼眼相机和边缘计算设备的全景深度感知系统。收集了一个包含未标记的真实世界数据和合成数据的大规模混合数据集用于模型训练。在公共数据集上的实验表明,所提出的方法在消耗显著更少资源的同时,实现了与最先进方法相当的结果。所提出的系统和算法还在各种复杂的室内和室外真实场景中表现出高精度,在边缘计算平台上实现了15帧/秒的推理速度。
🔬 方法详解
问题定义:论文旨在解决在真实场景下,全景深度估计的实时性和泛化性问题。现有方法通常计算复杂度高,难以在边缘设备上实时运行,并且在面对未见过的真实场景时,精度会显著下降。
核心思路:论文的核心思路是利用教师-学生学习框架,结合轻量级网络结构和数据增强,在保证实时性的前提下,提升模型在真实场景中的精度和泛化能力。教师模型负责生成高质量的伪标签,学生模型则学习这些伪标签,从而在无监督的情况下提升性能。
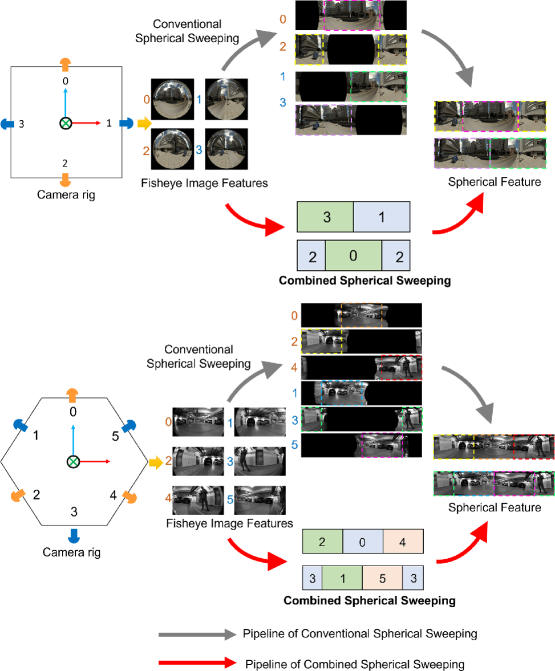
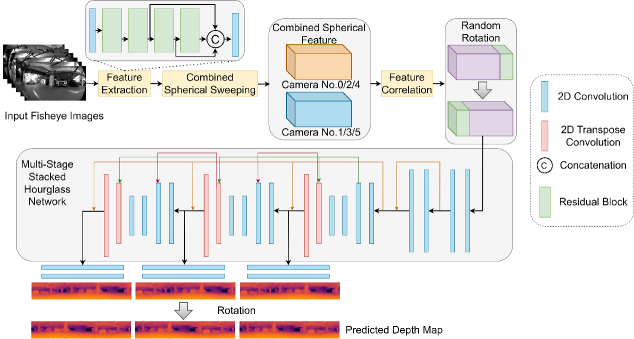
技术框架:整体框架包含以下几个主要模块:1) HexaMODE全景深度感知系统:一个基于多视角鱼眼相机的硬件系统,用于采集真实场景数据。2) 教师模型:使用高精度立体匹配算法,为未标记的真实数据生成伪标签。3) 学生模型Rt-OmniMVS:一个轻量级的全景深度估计网络,在伪标签和合成数据上进行训练。4) 数据增强模块:采用多种数据增强技术,提升模型的鲁棒性和泛化能力。
关键创新:论文的关键创新点在于:1) 组合球面扫描方法:用于加速深度估计过程,提高实时性。2) 教师-学生学习策略:利用无标签真实数据提升模型在真实场景中的泛化能力。3) 轻量级网络结构Rt-OmniMVS:专为边缘计算平台设计,保证实时推理速度。
关键设计:1) Rt-OmniMVS网络结构:具体网络结构未知,但强调了轻量化设计,以适应边缘计算平台的资源限制。2) 损失函数:使用教师模型生成的伪标签作为监督信号,训练学生模型。具体损失函数形式未知。3) 数据增强策略:采用多种数据增强方法,如旋转、缩放、颜色抖动等,以提高模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的Rt-OmniMVS方法在公共数据集上取得了与SOTA方法相当的性能,同时显著降低了计算资源消耗。在HexaMODE系统上,该方法能够在边缘计算平台上实现15FPS的实时推理速度,并在各种复杂的室内和室外真实场景中表现出高精度,验证了其在实际应用中的有效性。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、虚拟现实等领域。在自动驾驶中,全景深度估计可以帮助车辆更好地理解周围环境,提高安全性。在机器人导航中,可以帮助机器人进行自主定位和路径规划。在虚拟现实中,可以提供更逼真的三维场景体验。未来,该技术有望进一步推动这些领域的发展。
📄 摘要(原文)
Omnidirectional depth estimation enables efficient 3D perception over a full 360-degree range. However, in real-world applications such as autonomous driving and robotics, achieving real-time performance and robust cross-scene generalization remains a significant challenge for existing algorithms. In this paper, we propose a real-time omnidirectional depth estimation method for edge computing platforms named Rt-OmniMVS, which introduces the Combined Spherical Sweeping method and implements the lightweight network structure to achieve real-time performance on edge computing platforms. To achieve high accuracy, robustness, and generalization in real-world environments, we introduce a teacher-student learning strategy. We leverage the high-precision stereo matching method as the teacher model to predict pseudo labels for unlabeled real-world data, and utilize data and model augmentation techniques for training to enhance performance of the student model Rt-OmniMVS. We also propose HexaMODE, an omnidirectional depth sensing system based on multi-view fisheye cameras and edge computation device. A large-scale hybrid dataset contains both unlabeled real-world data and synthetic data is collected for model training. Experiments on public datasets demonstrate that proposed method achieves results comparable to state-of-the-art approaches while consuming significantly less resource. The proposed system and algorithm also demonstrate high accuracy in various complex real-world scenarios, both indoors and outdoors, achieving an inference speed of 15 frames per second on edge computing platforms.