Self-Evolving Depth-Supervised 3D Gaussian Splatting from Rendered Stereo Pairs
作者: Sadra Safadoust, Fabio Tosi, Fatma Güney, Matteo Poggi
分类: cs.CV
发布日期: 2024-09-11
备注: BMVC 2024. Project page: https://kuis-ai.github.io/StereoGS/
💡 一句话要点
提出自进化深度监督3D高斯溅射,利用渲染立体图像对提升深度精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 深度监督 立体视觉 自进化学习 场景重建
📋 核心要点
- 3D高斯溅射在深度图渲染中存在几何结构不准确和伪影问题。
- 提出一种自进化深度监督方法,利用立体网络提供的深度信息进行优化。
- 实验表明,该方法能有效提高3D高斯溅射的深度精度,并在多个数据集上验证。
📝 摘要(中文)
3D高斯溅射(GS)在精确表示底层3D场景几何结构方面存在显著困难,导致渲染深度图时出现不准确和漂浮伪影。本文旨在解决这一局限性,全面分析了在GS基元优化过程中集成深度先验的方法,并为此提出了一种新颖的策略。该策略动态地利用来自现成的立体网络的深度线索,处理由GS模型自身在训练期间渲染的虚拟立体图像对,从而实现场景表示的一致性自我改进。在三个流行数据集上的实验结果,首次评估了这些模型的深度精度,验证了我们的发现。
🔬 方法详解
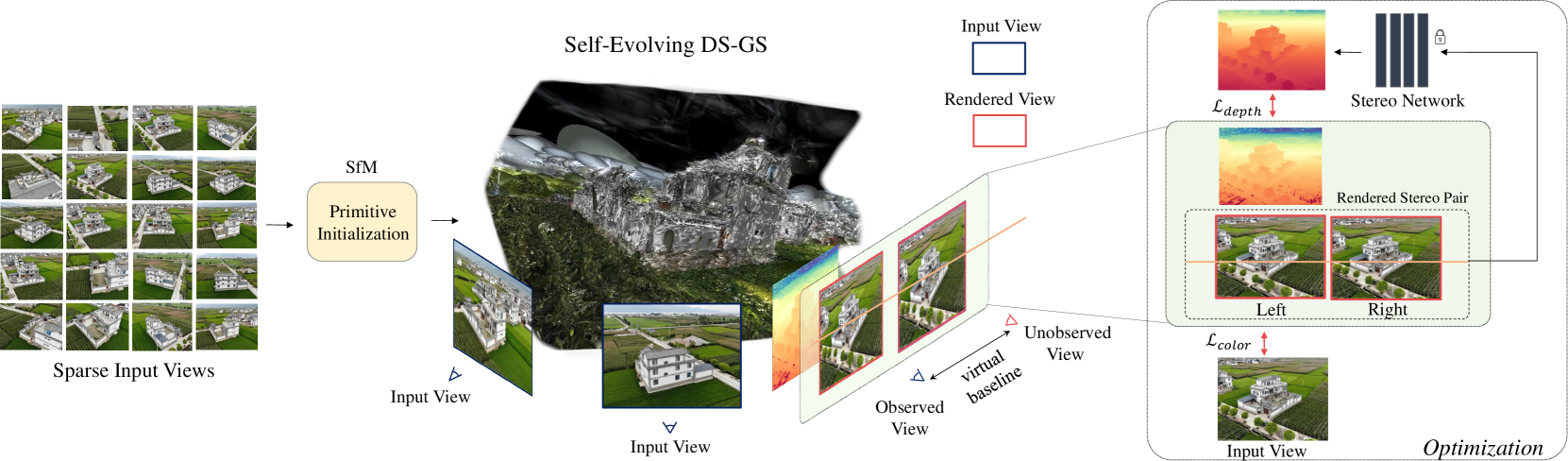
问题定义:3D高斯溅射(GS)在场景表示时,尤其是在深度信息的准确性方面存在不足。现有的GS方法在渲染深度图时,容易出现几何结构不准确和漂浮伪影,这限制了其在需要精确深度信息的应用中的使用。
核心思路:本文的核心思路是利用立体视觉提供的深度信息来监督和优化3D高斯溅射的训练过程。通过让GS模型渲染虚拟的立体图像对,并利用现成的立体匹配网络估计深度图,然后将估计的深度图作为先验知识,反过来指导GS模型的优化,从而实现场景表示的自进化改进。
技术框架:该方法的主要流程包括:1) 使用GS模型渲染虚拟立体图像对;2) 利用预训练的立体匹配网络对渲染的图像对进行深度估计;3) 将估计的深度图与GS模型预测的深度图进行比较,计算深度损失;4) 利用深度损失和其他损失函数(如渲染损失)共同优化GS模型的参数,包括高斯基元的位置、形状和颜色等。通过迭代执行这些步骤,GS模型可以逐步提高场景表示的深度精度。
关键创新:该方法最重要的创新点在于其自进化的深度监督机制。与传统的直接使用真实深度图监督GS模型不同,该方法利用GS模型自身渲染的图像对生成深度信息,并用这些信息反过来指导模型的优化。这种自监督的方式可以避免对大量真实深度数据的依赖,并且能够更好地适应不同的场景和数据集。
关键设计:关键设计包括:1) 使用高质量的立体匹配网络进行深度估计,以提供可靠的深度先验;2) 设计合适的深度损失函数,例如L1损失或L2损失,以衡量GS模型预测深度与估计深度之间的差异;3) 平衡深度损失和其他损失函数(如渲染损失)的权重,以避免过度拟合深度信息而影响渲染质量;4) 采用合适的优化算法,例如Adam,来更新GS模型的参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在三个流行数据集上显著提高了3D高斯溅射的深度精度。作为首个评估此类模型深度精度的研究,该方法为后续研究提供了基准。具体性能提升数据未知,但摘要强调了该方法在深度精度上的有效性。
🎯 应用场景
该研究成果可应用于增强现实、虚拟现实、机器人导航、三维重建等领域。通过提高场景深度信息的准确性,可以改善AR/VR应用的沉浸感和交互性,提升机器人对环境的感知能力,并为三维重建提供更精确的几何信息。未来,该方法有望扩展到动态场景和更大规模的场景重建。
📄 摘要(原文)
3D Gaussian Splatting (GS) significantly struggles to accurately represent the underlying 3D scene geometry, resulting in inaccuracies and floating artifacts when rendering depth maps. In this paper, we address this limitation, undertaking a comprehensive analysis of the integration of depth priors throughout the optimization process of Gaussian primitives, and present a novel strategy for this purpose. This latter dynamically exploits depth cues from a readily available stereo network, processing virtual stereo pairs rendered by the GS model itself during training and achieving consistent self-improvement of the scene representation. Experimental results on three popular datasets, breaking ground as the first to assess depth accuracy for these models, validate our findings.