LIME: Less Is More for MLLM Evaluation
作者: King Zhu, Qianbo Zang, Shian Jia, Siwei Wu, Feiteng Fang, Yizhi Li, Shawn Gavin, Tuney Zheng, Jiawei Guo, Bo Li, Haoning Wu, Xingwei Qu, Jian Yang, Zachary Liu, Xiang Yue, J. H. Liu, Chenghua Lin, Min Yang, Shiwen Ni, Wenhao Huang, Ge Zhang
分类: cs.CV, cs.AI
发布日期: 2024-09-10 (更新: 2024-10-13)
🔗 代码/项目: GITHUB
💡 一句话要点
LIME:精简多模态大语言模型评估基准,提升效率与区分度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 评估基准 模型评估 图像理解 半自动化流程
📋 核心要点
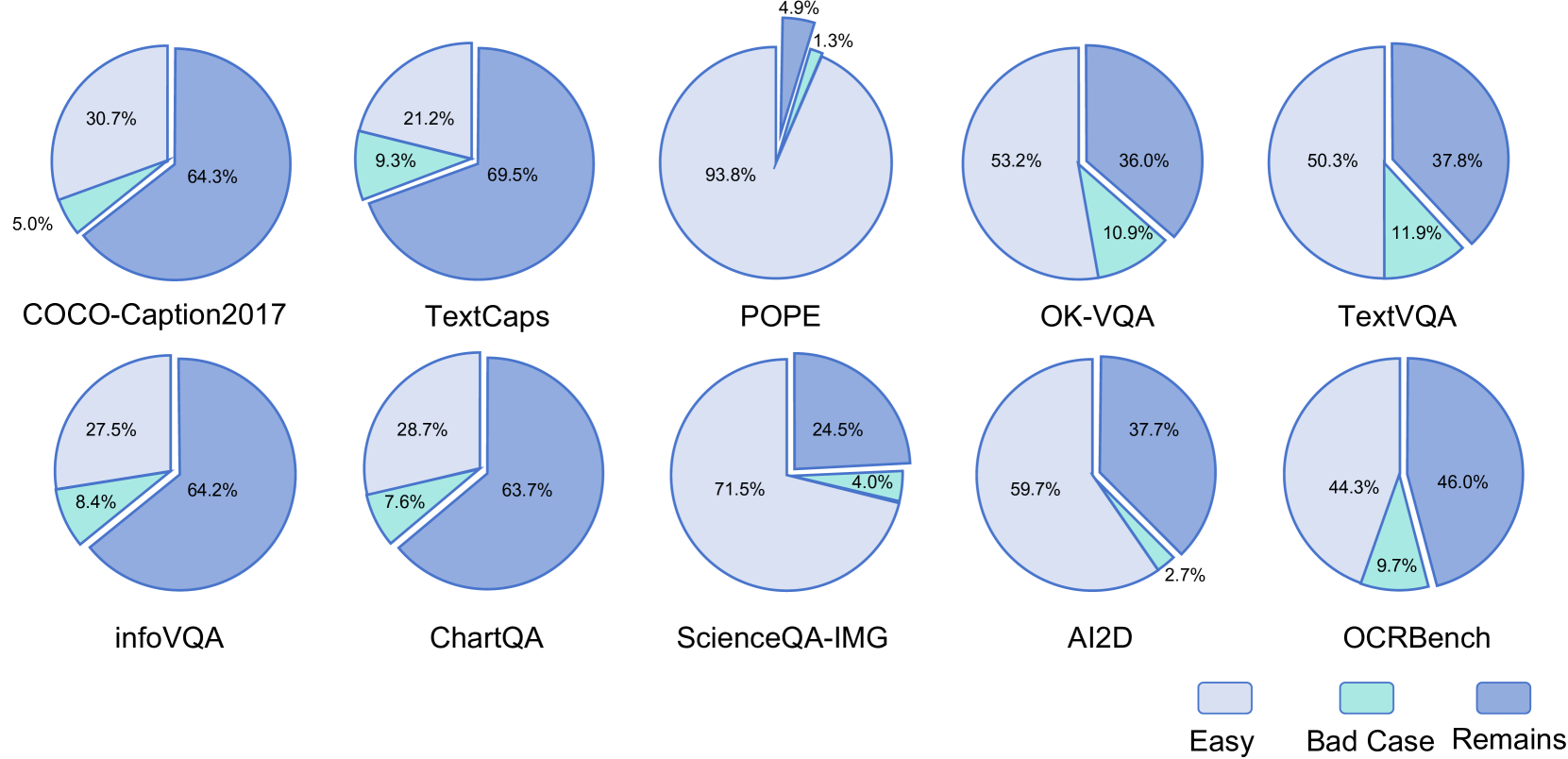
- 现有MLLM评估基准包含大量简单或无信息样本,难以有效区分模型性能,且评估成本高昂。
- LIME通过半自动化流程,过滤无信息样本,消除答案泄露,构建更精简高效的评估基准。
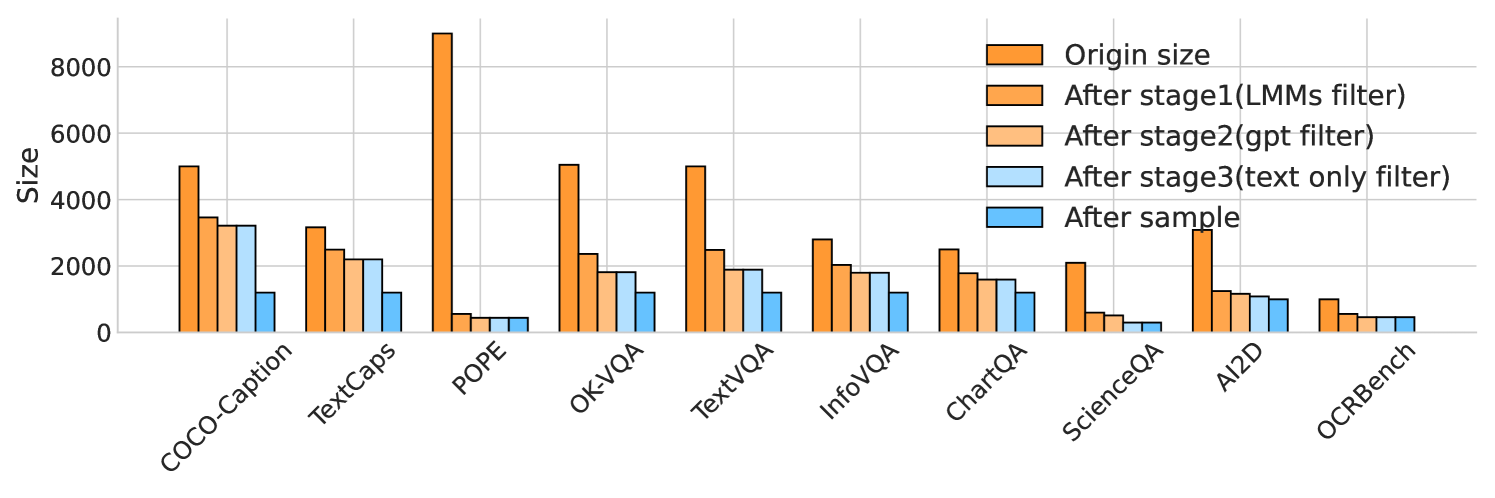
- 实验表明,LIME显著减少样本数量和评估时间,同时提高了模型性能区分度,并发现传统指标的局限性。
📝 摘要(中文)
多模态大语言模型(MLLM)在图像描述、视觉问答和推理等多种基准上进行评估。然而,许多基准包含过于简单或无信息的样本,使得有效区分不同MLLM的性能变得困难。此外,跨多个基准评估模型会带来巨大的计算负担。为了解决这些问题,我们提出了LIME(Less Is More for MLLM Evaluation),这是一个通过半自动化流程精简和高效的基准。该流程通过关注需要基于图像理解的任务来过滤掉无信息的样本并消除答案泄露。实验表明,LIME减少了76%的样本数量和77%的评估时间,同时更有效地区分了不同模型的能力。值得注意的是,我们发现传统的自动指标(如CIDEr)不足以评估MLLM的图像描述性能;排除描述任务分数可以更准确地反映整体模型性能。所有代码和数据均可在https://github.com/kangreen0210/LIME获取。
🔬 方法详解
问题定义:现有MLLM的评估基准存在冗余和信息量不足的问题,导致评估效率低下,且难以准确区分不同模型的性能。此外,部分基准存在答案泄露,使得评估结果不准确。传统的评估指标,如CIDEr,在评估MLLM的图像描述能力时存在局限性。
核心思路:LIME的核心思路是通过精简评估数据集,去除无信息量的样本,从而提高评估效率和准确性。通过关注需要图像理解的任务,可以消除答案泄露,确保评估的公平性。同时,论文还发现传统的评估指标在MLLM评估中存在不足,并建议排除caption任务分数以获得更准确的整体模型性能评估。
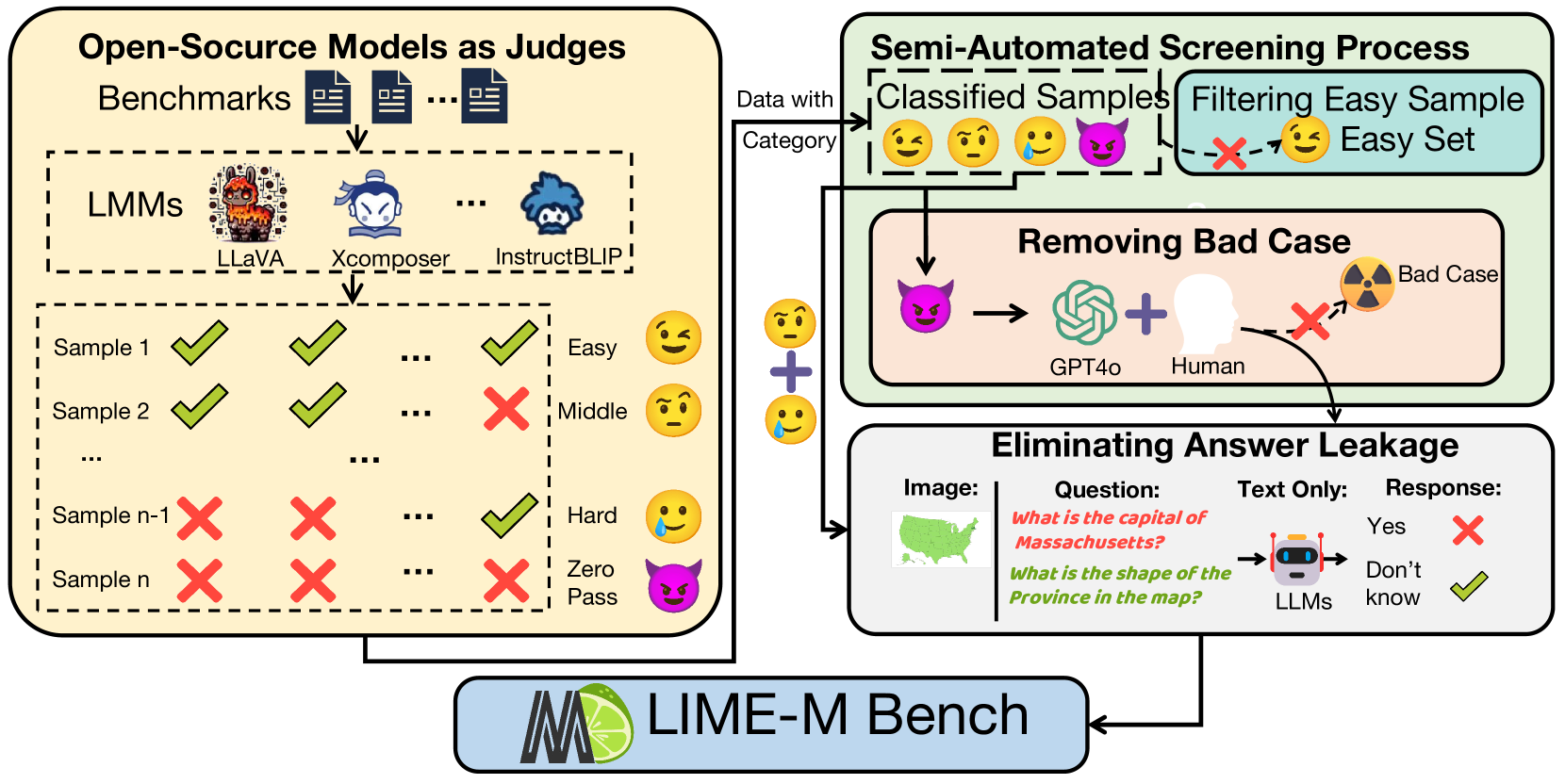
技术框架:LIME采用半自动化的流程来构建精简的评估基准。该流程主要包括以下几个阶段:1) 样本分析:分析现有基准中的样本,识别无信息量或存在答案泄露的样本。2) 样本过滤:根据分析结果,过滤掉不合格的样本。3) 基准构建:构建精简后的评估基准,包含更具挑战性和信息量的样本。4) 评估指标选择:选择合适的评估指标,或对现有指标进行改进,以更准确地评估MLLM的性能。
关键创新:LIME的关键创新在于提出了一个半自动化的流程来构建更精简、高效和准确的MLLM评估基准。与传统的评估方法相比,LIME能够显著减少评估时间和计算成本,同时提高模型性能的区分度。此外,LIME还指出了传统评估指标在MLLM评估中的局限性,并提出了改进建议。
关键设计:LIME流程的关键设计包括:1) 无信息样本的定义和识别方法;2) 答案泄露的检测和消除策略;3) 精简基准的构建原则和方法;4) 评估指标的选择和改进方案。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细描述,可能依赖于具体的MLLM和评估任务。
🖼️ 关键图片
📊 实验亮点
LIME在实验中将样本数量减少了76%,评估时间减少了77%,同时提高了不同模型性能的区分度。研究还发现,传统的自动指标(如CIDEr)不足以评估MLLM的图像描述性能,排除描述任务分数可以更准确地反映整体模型性能。这些结果表明LIME是一个更有效和可靠的MLLM评估基准。
🎯 应用场景
LIME可应用于多模态大语言模型的开发和评估,帮助研究人员更高效地评估模型性能,发现模型缺陷,并指导模型改进。该基准的精简特性使其更易于使用和维护,降低了评估成本,促进了MLLM技术的快速发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) are evaluated on various benchmarks, such as image captioning, visual question answering, and reasoning. However, many of these benchmarks include overly simple or uninformative samples, complicating the effective distinction of different MLLMs' performance. Furthermore, evaluating models across numerous benchmarks incurs a significant computational burden. To address these issues, we propose LIME (Less Is More for MLLM Evaluation), a refined and efficient benchmark curated through a semi-automated pipeline. This pipeline filters out uninformative samples and eliminates answer leakage by focusing on tasks that necessitate image-based understanding. Our experiments indicate that LIME reduces the number of samples by 76% and evaluation time by 77%, while also providing a more effective means of distinguishing the capabilities of different models. Notably, we find that traditional automatic metrics, such as CIDEr, are inadequate for assessing MLLMs' captioning performance; excluding the caption task score yields a more accurate reflection of overall model performance. All code and data are available at https://github.com/kangreen0210/LIME.