LEIA: Latent View-invariant Embeddings for Implicit 3D Articulation
作者: Archana Swaminathan, Anubhav Gupta, Kamal Gupta, Shishira R. Maiya, Vatsal Agarwal, Abhinav Shrivastava
分类: cs.CV
发布日期: 2024-09-10
备注: Accepted to ECCV 2024. Project Website at https://archana1998.github.io/leia/
💡 一句话要点
LEIA:提出一种隐式3D铰接的潜在视角不变嵌入方法,无需运动信息。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经辐射场 动态场景重建 物体铰接 视角不变性 潜在空间插值
📋 核心要点
- 现有动态NeRF方法依赖于部件级重建和运动估计,受限于对运动部件数量或物体类别的先验知识。
- LEIA通过观察物体在不同状态下的表现,利用超网络参数化NeRF,学习视角不变的潜在表示。
- 实验表明,LEIA能够生成新的铰接配置,且性能优于依赖运动信息的方法,实现了视角和关节配置的解耦。
📝 摘要(中文)
神经辐射场(NeRFs)彻底改变了静态场景和物体的3D重建,提供了前所未有的质量。然而,将NeRFs扩展到动态物体或物体铰接建模仍然是一个具有挑战性的问题。先前的工作主要集中在物体部件级别的重建和运动估计,但它们通常依赖于关于运动部件数量或物体类别的启发式方法,这限制了它们的实际应用。本文介绍了一种用于表示动态3D物体的新方法LEIA。我们的方法包括观察物体在不同的时间步长或“状态”,并使用当前状态来调节一个超网络,以此参数化我们的NeRF。这种方法允许我们为每个状态学习一个视角不变的潜在表示。我们进一步证明,通过在这些状态之间进行插值,我们可以在3D空间中生成先前未见过的新的铰接配置。实验结果表明,我们的方法在铰接物体方面非常有效,并且与视角和关节配置无关。值得注意的是,我们的方法优于先前依赖于运动信息进行铰接配准的方法。
🔬 方法详解
问题定义:现有动态NeRF方法在处理物体铰接问题时,通常需要依赖于物体部件级别的重建和运动估计。这些方法往往需要预先知道物体由多少个运动部件组成,或者物体的类别信息,这限制了它们在实际应用中的泛化能力。当物体结构复杂或者类别未知时,这些方法的效果会显著下降。
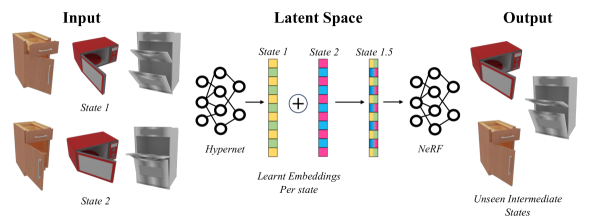
核心思路:LEIA的核心思路是学习一种视角不变的潜在表示,用于描述物体在不同状态下的形态。通过观察物体在不同时间步长或“状态”下的表现,LEIA能够捕捉到物体铰接过程中的关键信息,而无需显式地进行运动估计或部件分割。这种潜在表示可以被用于参数化NeRF,从而实现对动态物体的3D重建和铰接控制。
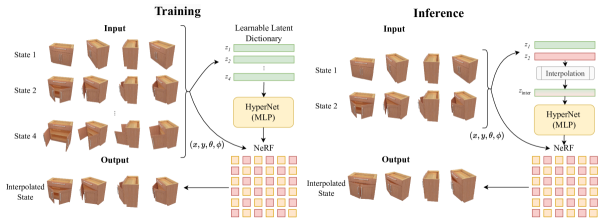
技术框架:LEIA的整体框架包括以下几个主要模块:1) 状态编码器:用于将物体在不同状态下的观测信息编码成潜在向量。2) 超网络:一个以状态编码为输入的神经网络,用于生成NeRF的参数。3) NeRF:利用超网络生成的参数,将3D空间中的点映射到颜色和密度值。整个流程是,首先输入不同状态下的图像,通过状态编码器得到潜在向量,然后将潜在向量输入超网络,超网络输出NeRF的参数,最后使用NeRF进行渲染。
关键创新:LEIA最重要的创新点在于它能够学习到视角不变的潜在表示,从而实现与视角和关节配置无关的铰接控制。与现有方法相比,LEIA不需要显式地进行运动估计或部件分割,而是通过隐式地学习物体在不同状态下的形态变化来实现铰接。这种方法更加灵活和通用,可以应用于各种复杂的动态物体。
关键设计:LEIA的关键设计包括:1) 使用超网络来参数化NeRF,从而实现对不同状态下的NeRF参数的动态调整。2) 设计合适的损失函数,鼓励学习到的潜在表示具有视角不变性。3) 通过在潜在空间中进行插值,生成新的铰接配置。具体的损失函数包括重建损失和正则化损失,网络结构的选择也需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
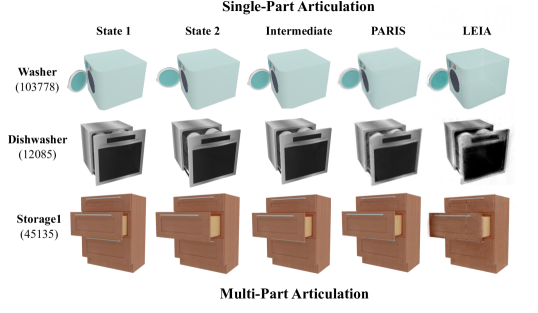
LEIA在铰接物体建模任务上取得了显著的成果,超越了依赖运动信息的传统方法。实验结果表明,LEIA能够生成高质量的3D重建结果,并且能够实现对物体铰接的精确控制。在定量指标上,LEIA在重建精度和铰接控制精度方面均优于现有方法。
🎯 应用场景
LEIA在机器人控制、动画制作、虚拟现实等领域具有广泛的应用前景。例如,可以用于控制机器人的关节运动,生成逼真的动画角色,或者创建沉浸式的虚拟现实体验。此外,LEIA还可以用于对医学图像进行分析,帮助医生诊断疾病。
📄 摘要(原文)
Neural Radiance Fields (NeRFs) have revolutionized the reconstruction of static scenes and objects in 3D, offering unprecedented quality. However, extending NeRFs to model dynamic objects or object articulations remains a challenging problem. Previous works have tackled this issue by focusing on part-level reconstruction and motion estimation for objects, but they often rely on heuristics regarding the number of moving parts or object categories, which can limit their practical use. In this work, we introduce LEIA, a novel approach for representing dynamic 3D objects. Our method involves observing the object at distinct time steps or "states" and conditioning a hypernetwork on the current state, using this to parameterize our NeRF. This approach allows us to learn a view-invariant latent representation for each state. We further demonstrate that by interpolating between these states, we can generate novel articulation configurations in 3D space that were previously unseen. Our experimental results highlight the effectiveness of our method in articulating objects in a manner that is independent of the viewing angle and joint configuration. Notably, our approach outperforms previous methods that rely on motion information for articulation registration.