From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
作者: Tessa Pulli, Stefan Thalhammer, Simon Schwaiger, Markus Vincze
分类: cs.CV, cs.RO
发布日期: 2024-09-09
💡 一句话要点
提出一种基于视觉语言模型的零样本物体姿态估计方法,提升机器人对新物体的抓取能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 零样本学习 物体姿态估计 视觉语言模型 机器人抓取 NeRF 点云配准 语言提示
📋 核心要点
- 现有方法在检测和抓取新物体时缺乏先验知识,零样本姿态估计器旨在解决这一问题,但仍面临挑战。
- 该论文提出利用视觉语言模型(VLM)理解语言输入和图像输入之间的关系,从而实现基于语言提示的零样本6D物体姿态估计。
- 论文分析了LERF在开放集物体姿态估计中的适用性,并考察了超参数对性能的影响,为实际应用提供了参考。
📝 摘要(中文)
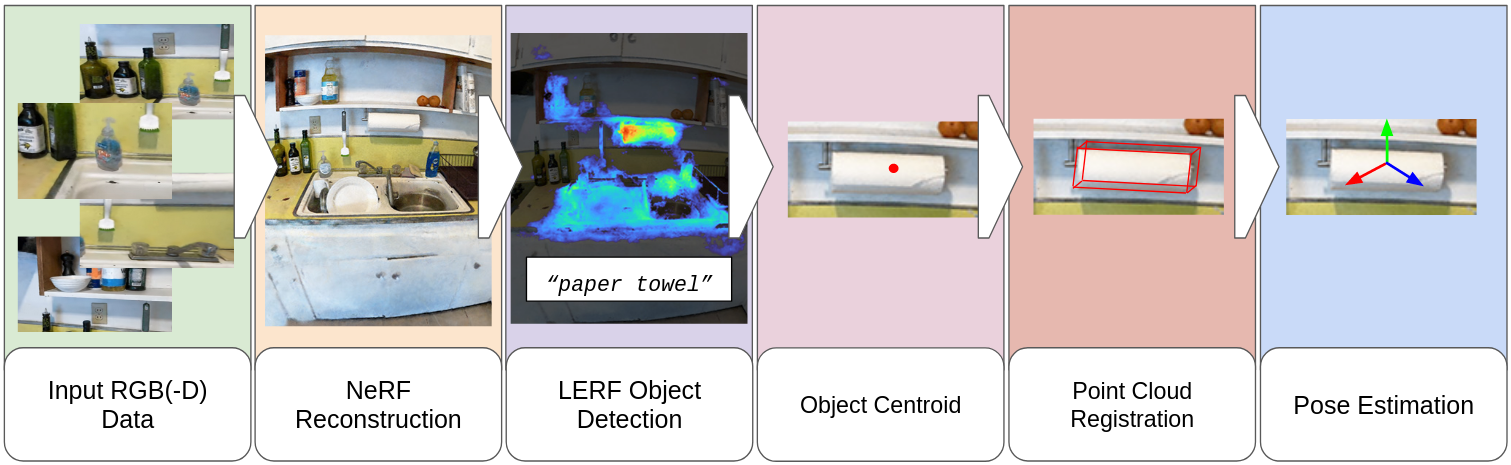
本文提出了一种利用视觉语言模型(VLM)进行可提示的零样本6D物体姿态估计的新框架。该方法旨在利用VLM的零样本能力,将其迁移到6D物体姿态估计任务中。核心思想是:首先,基于语言嵌入的NeRF重建的相关性图,推导出物体的大致位置;然后,使用点云配准方法计算姿态估计。此外,本文还分析了LERF在开放集物体姿态估计中的适用性,考察了相关性图激活阈值等超参数,并研究了实例和类别层面的零样本能力。最后,计划在真实环境中进行机器人抓取实验。
🔬 方法详解
问题定义:论文旨在解决机器人需要在真实场景中与新物体交互的问题,即在没有先验知识的情况下,如何准确估计新物体的6D姿态,以便进行抓取等操作。现有方法在处理新物体时泛化能力不足,需要大量标注数据进行训练。
核心思路:论文的核心思路是利用视觉语言模型(VLM)的零样本学习能力,将语言描述与视觉信息关联起来,从而实现对新物体的姿态估计。通过语言提示,引导VLM定位物体,并利用NeRF重建和点云配准技术精确估计姿态。
技术框架:整体框架包含以下几个主要阶段:1) 使用语言嵌入的NeRF(LERF)重建场景,并生成相关性图,该图指示了场景中与给定语言描述相关的区域;2) 基于相关性图,确定物体的大致位置;3) 使用点云配准方法,将观测到的点云与NeRF重建的点云进行对齐,从而计算出物体的6D姿态。
关键创新:最重要的创新点在于将视觉语言模型应用于零样本6D物体姿态估计。与传统方法相比,该方法无需针对每个新物体进行训练,而是通过语言提示实现泛化。此外,利用LERF生成相关性图,为姿态估计提供了有效的先验信息。
关键设计:关键设计包括:1) 使用CLIP等VLM模型提取图像和文本的特征,并计算它们之间的相似度,生成相关性图;2) 设计合适的激活阈值,用于过滤相关性图中的噪声,提高物体定位的准确性;3) 选择合适的点云配准算法,例如ICP或其变体,以实现精确的姿态估计。具体的损失函数和网络结构取决于所使用的VLM和点云配准算法。
🖼️ 关键图片

📊 实验亮点
论文分析了LERF在开放集物体姿态估计中的适用性,考察了相关性图激活阈值等超参数对性能的影响,并在实例和类别层面上验证了零样本能力。虽然摘要中没有给出具体的性能数据,但强调了对超参数的细致分析,以及在真实机器人抓取实验的计划,表明了该方法具有实际应用潜力。
🎯 应用场景
该研究成果可应用于机器人自动化、智能制造、家庭服务等领域。例如,机器人可以根据用户的语音指令,识别并抓取指定的物体,从而实现更智能、更灵活的人机交互。此外,该方法还可以用于增强现实(AR)和虚拟现实(VR)应用,实现虚拟物体与真实场景的无缝融合。
📄 摘要(原文)
Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.