SDformerFlow: Spatiotemporal swin spikeformer for event-based optical flow estimation
作者: Yi Tian, Juan Andrade-Cetto
分类: cs.CV, cs.AI
发布日期: 2024-09-06
备注: Under Review
💡 一句话要点
提出基于时空Swin Spikeformer的SDformerFlow,用于事件相机光流估计。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 事件相机 光流估计 脉冲神经网络 Swin Transformer Spikeformer 时空建模 低功耗
📋 核心要点
- 传统光流估计方法在高速运动和复杂光照下表现不佳,事件相机能有效应对这些挑战,但缺乏高效的SNN处理方案。
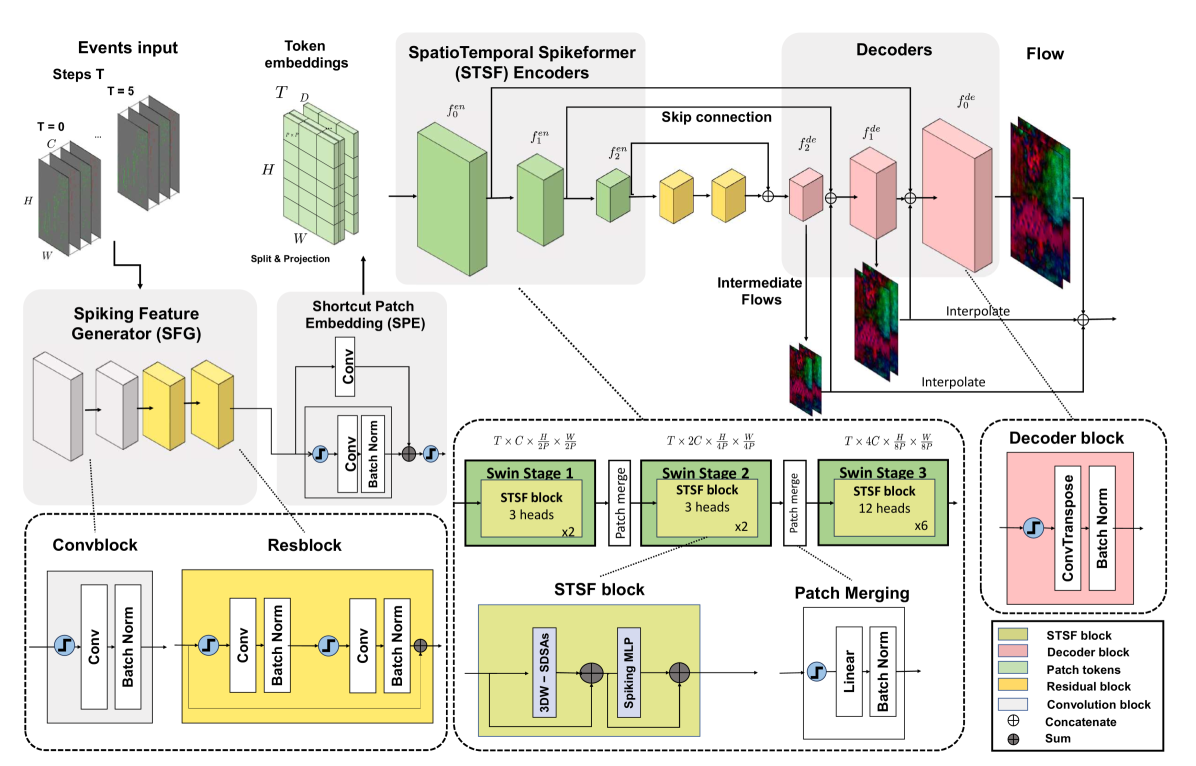
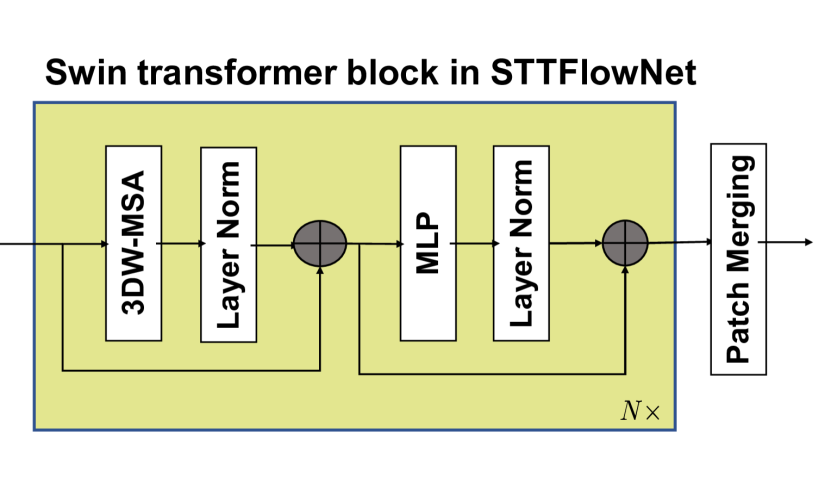
- 利用Transformer和Spikeformer的优势,设计了STTFlowNet和SDformerFlow两种网络,前者是ANN,后者是全脉冲版本。
- 实验结果表明,提出的SDformerFlow在DSEC和MVSEC数据集上达到了SOTA性能,并显著降低了功耗。
📝 摘要(中文)
事件相机生成异步且稀疏的事件流,捕捉光强变化。相比传统相机,事件相机具有更高的动态范围和极快的数据速率,使其在快速运动或复杂光照条件下特别有用。脉冲神经网络(SNN)具有类似的异步和稀疏特性,非常适合处理事件相机的数据。受Transformer和spike-driven Transformer (Spikeformer)在其他计算机视觉任务中的潜力启发,我们提出了两种用于事件相机快速鲁棒光流估计的解决方案:STTFlowNet和SDformerFlow。STTFlowNet采用U型人工神经网络(ANN)架构,具有时空移位窗口自注意力(Swin) Transformer编码器,而SDformerFlow则提出了其完全脉冲对应物,结合了Swin Spikeformer编码器。此外,我们还提出了具有不同神经元模型的脉冲版本的两种变体。我们的工作是首次使用Spikeformer进行密集光流估计。我们对所有模型进行端到端监督学习训练。我们的结果在DSEC和MVSEC数据集上,在基于SNN的事件光流方法中产生了最先进的性能,并且与等效的ANN相比,功耗显着降低。
🔬 方法详解
问题定义:论文旨在解决事件相机在高速运动和复杂光照条件下进行光流估计的问题。现有方法,特别是基于传统帧的算法,难以有效处理事件相机产生的高动态范围、异步和稀疏的事件流数据。此外,虽然SNN在处理事件数据方面具有天然优势,但缺乏利用Transformer架构进行光流估计的有效SNN模型。
核心思路:论文的核心思路是将Transformer架构,特别是Swin Transformer,与SNN相结合,利用Swin Transformer强大的时空建模能力和SNN的低功耗特性,设计出高效的光流估计模型。通过将Swin Transformer转化为Spikeformer,实现了完全脉冲化的光流估计网络。
技术框架:论文提出了两种网络架构:STTFlowNet和SDformerFlow。STTFlowNet是基于ANN的U型网络,使用Swin Transformer编码器提取特征。SDformerFlow是完全脉冲化的版本,使用Swin Spikeformer编码器。两个网络都采用端到端监督学习进行训练。SDformerFlow还提出了两种不同的神经元模型变体。
关键创新:论文的关键创新点在于首次将Spikeformer应用于密集光流估计,并提出了完全脉冲化的光流估计网络SDformerFlow。通过将Swin Transformer转化为Spikeformer,实现了在SNN中利用Transformer架构进行光流估计。
关键设计:SDformerFlow的关键设计包括:1) 使用Swin Spikeformer编码器进行特征提取;2) 采用U型网络结构进行光流估计;3) 提出了两种不同的神经元模型变体;4) 使用监督学习进行端到端训练;5) 损失函数的设计,可能包括光流估计的误差项和正则化项等(具体细节论文中未明确说明,属于未知)。
🖼️ 关键图片

📊 实验亮点
SDformerFlow在DSEC和MVSEC数据集上取得了SOTA性能,超过了现有的SNN光流估计方法。此外,SDformerFlow相比于等效的ANN (STTFlowNet) 显著降低了功耗,验证了SNN在事件数据处理方面的优势。具体的性能提升幅度需要参考论文中的实验数据,此处未知。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、无人机等领域,尤其是在高速运动和复杂光照条件下。利用事件相机和SNN的优势,可以实现低功耗、高效率的光流估计,从而提高系统的鲁棒性和实时性。未来,该技术有望在智能监控、虚拟现实等领域发挥重要作用。
📄 摘要(原文)
Event cameras generate asynchronous and sparse event streams capturing changes in light intensity. They offer significant advantages over conventional frame-based cameras, such as a higher dynamic range and an extremely faster data rate, making them particularly useful in scenarios involving fast motion or challenging lighting conditions. Spiking neural networks (SNNs) share similar asynchronous and sparse characteristics and are well-suited for processing data from event cameras. Inspired by the potential of transformers and spike-driven transformers (spikeformers) in other computer vision tasks, we propose two solutions for fast and robust optical flow estimation for event cameras: STTFlowNet and SDformerFlow. STTFlowNet adopts a U-shaped artificial neural network (ANN) architecture with spatiotemporal shifted window self-attention (swin) transformer encoders, while SDformerFlow presents its fully spiking counterpart, incorporating swin spikeformer encoders. Furthermore, we present two variants of the spiking version with different neuron models. Our work is the first to make use of spikeformers for dense optical flow estimation. We conduct end-to-end training for all models using supervised learning. Our results yield state-of-the-art performance among SNN-based event optical flow methods on both the DSEC and MVSEC datasets, and show significant reduction in power consumption compared to the equivalent ANNs.