Collaborative Learning for Enhanced Unsupervised Domain Adaptation
作者: Minhee Cho, Hyesong Choi, Hayeon Jo, Dongbo Min
分类: cs.CV
发布日期: 2024-09-04 (更新: 2025-04-16)
💡 一句话要点
提出CLDA协同学习框架,提升轻量级模型在无监督领域自适应任务中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无监督领域自适应 知识蒸馏 协同学习 轻量级模型 语义分割
📋 核心要点
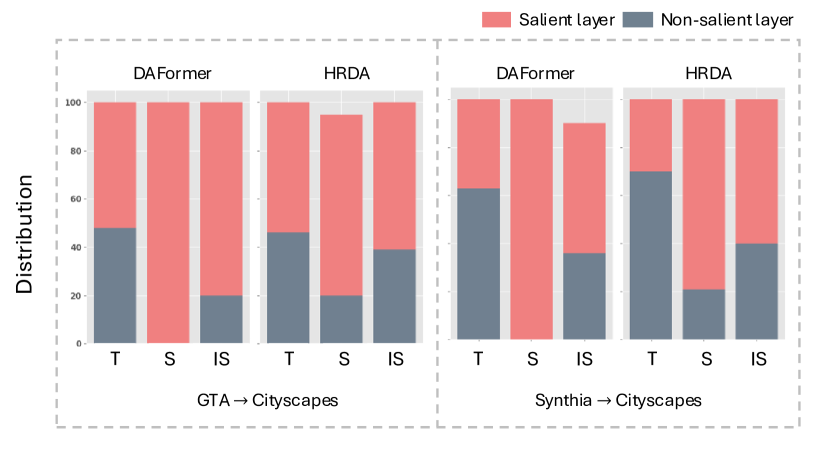
- 现有UDA方法计算资源需求大,轻量级模型性能提升有限,且领域偏移导致教师模型泛化能力下降。
- 提出CLDA协同学习框架,利用学生模型更新教师模型的非显著参数,反过来提升学生模型的UDA性能。
- 实验结果表明,CLDA在语义分割任务中,教师和学生模型的mIoU均得到显著提升,验证了方法的有效性。
📝 摘要(中文)
无监督领域自适应(UDA)旨在弥合在有标签源域上训练的模型与在无标签目标域上的部署之间的差距。然而,当前高性能模型需要大量资源,使得部署成本过高,因此需要紧凑而有效的模型。对于轻量级模型的UDA,利用教师-学生框架的知识蒸馏(KD)可能是一种常见方法,但我们发现UDA中的领域转移会导致教师模型中非显著参数显著增加,从而降低模型的泛化能力,并将误导性信息传递给学生模型。有趣的是,我们观察到学生模型中这种现象的发生程度要小得多。受此启发,我们引入了用于UDA的协同学习(CLDA),这是一种使用学生模型更新教师模型的非显著参数,同时利用更新后的教师模型来提高学生模型的UDA性能的方法。实验表明,学生和教师模型的性能都得到了持续的提高。例如,在语义分割中,与GTA到Cityscapes数据集中的基线模型相比,CLDA使教师模型的mIoU提高了+0.7%,学生模型的mIoU提高了+1.4%。在Synthia到Cityscapes数据集中,教师模型和学生模型分别实现了+0.8% mIoU和+2.0% mIoU的提升。
🔬 方法详解
问题定义:论文旨在解决无监督领域自适应(UDA)中,轻量级模型在领域偏移下性能下降的问题。现有基于知识蒸馏的UDA方法,在领域偏移较大时,教师模型会学习到大量非显著参数,这些参数会误导学生模型的学习,降低其泛化能力。
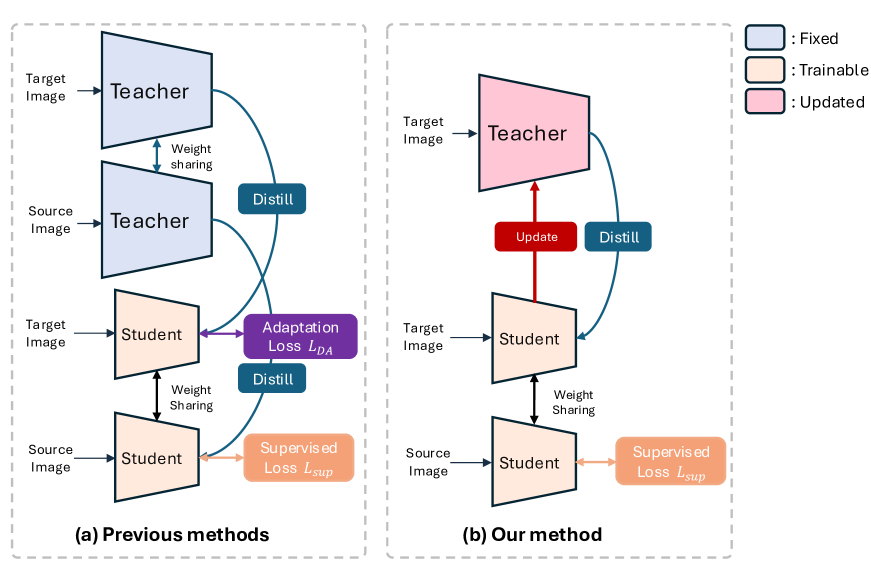
核心思路:论文的核心思路是利用学生模型来修正教师模型中受领域偏移影响的非显著参数。作者观察到,学生模型受领域偏移的影响较小,因此可以作为教师模型的“校正器”,从而提升教师模型的质量,进而提升学生模型的UDA性能。
技术框架:CLDA框架包含一个教师模型和一个学生模型。训练过程中,首先使用源域数据训练教师模型。然后,利用学生模型预测目标域数据,并使用学生模型的预测结果来更新教师模型的非显著参数。同时,使用更新后的教师模型来指导学生模型的学习,从而提升学生模型的UDA性能。这个过程迭代进行,直到模型收敛。
关键创新:该方法最重要的创新点在于利用学生模型来更新教师模型,从而缓解领域偏移对教师模型的影响。这种协同学习的方式,使得教师模型和学生模型能够相互促进,共同提升UDA性能。与传统的知识蒸馏方法不同,CLDA不仅仅是单向的知识传递,而是双向的协同学习。
关键设计:论文的关键设计包括:1) 如何定义和选择教师模型的非显著参数;2) 如何利用学生模型的预测结果来更新教师模型的非显著参数;3) 如何平衡教师模型和学生模型之间的学习,避免学生模型过度拟合目标域数据。具体来说,可以使用L1正则化来识别非显著参数,并使用学生模型的预测结果和教师模型的预测结果之间的差异来更新这些参数。损失函数可以包括知识蒸馏损失、领域对抗损失和正则化损失。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CLDA方法在GTA-to-Cityscapes和Synthia-to-Cityscapes两个语义分割数据集上均取得了显著的性能提升。在GTA-to-Cityscapes数据集上,教师模型的mIoU提升了0.7%,学生模型的mIoU提升了1.4%。在Synthia-to-Cityscapes数据集上,教师模型的mIoU提升了0.8%,学生模型的mIoU提升了2.0%。这些结果表明,CLDA方法能够有效地提升轻量级模型在UDA任务中的性能。
🎯 应用场景
该研究成果可应用于自动驾驶、医学图像分析、机器人等领域,在这些领域中,模型需要在不同场景和环境下进行部署,而标注数据的获取成本很高。CLDA方法可以有效地利用已有的标注数据,提升模型在未标注目标域上的性能,降低数据标注成本,加速模型部署。
📄 摘要(原文)
Unsupervised Domain Adaptation (UDA) endeavors to bridge the gap between a model trained on a labeled source domain and its deployment in an unlabeled target domain. However, current high-performance models demand significant resources, making deployment costs prohibitive and highlighting the need for compact, yet effective models. For UDA of lightweight models, Knowledge Distillation (KD) leveraging a Teacher-Student framework could be a common approach, but we found that domain shift in UDA leads to a significant increase in non-salient parameters in the teacher model, degrading model's generalization ability and transferring misleading information to the student model. Interestingly, we observed that this phenomenon occurs considerably less in the student model. Driven by this insight, we introduce Collaborative Learning for UDA (CLDA), a method that updates the teacher's non-salient parameters using the student model and at the same time utilizes the updated teacher model to improve UDA performance of the student model. Experiments show consistent performance improvements for both student and teacher models. For example, in semantic segmentation, CLDA achieves an improvement of +0.7% mIoU for the teacher model and +1.4% mIoU for the student model compared to the baseline model in the GTA-to-Cityscapes datasets. In the Synthia-to-Cityscapes dataset, it achieves an improvement of +0.8% mIoU and +2.0% mIoU for the teacher and student models, respectively.