PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation
作者: Jun Ling, Yiwen Wang, Han Xue, Rong Xie, Li Song
分类: cs.CV, cs.AI, cs.MM
发布日期: 2024-09-04
备注: 7+5 pages, 15 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
PoseTalk:提出基于文本和音频的姿态控制和运动细化的一镜式说话人头部生成方法
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 说话人头部生成 姿态控制 唇音同步 文本驱动 音频驱动
📋 核心要点
- 现有音频驱动的说话人头部生成方法在头部姿态生成和唇部同步方面存在不足,难以实现精确的音频匹配和姿态编辑。
- PoseTalk通过头部姿态连接视觉、语言和音频信号,利用姿态潜在扩散模型从文本和音频生成姿态,并采用细化学习策略优化唇部运动。
- 实验结果表明,PoseTalk在姿态多样性、真实感和唇音同步方面均优于现有方法,能够生成具有自然头部运动的说话人视频。
📝 摘要(中文)
本文提出PoseTalk,一个可以自由生成唇音同步的说话人头部视频的系统,该系统可以根据文本提示和音频自由控制头部姿态。该方法的核心思想是使用头部姿态来连接视觉、语言和音频信号。首先,我们提出从音频和文本提示生成姿态,其中音频提供头部运动的短期变化和节奏对应关系,文本提示描述头部运动的长期语义。为了实现这个目标,我们设计了一个姿态潜在扩散(PLD)模型,以在姿态潜在空间中从文本提示和音频线索生成运动潜在表示。其次,我们观察到一个损失不平衡问题:唇部区域的损失贡献小于由姿态和唇部引起的总重建损失的4%,这使得优化倾向于头部运动而不是唇部形状。为了解决这个问题,我们提出了一种基于细化的学习策略,使用两个级联网络(即CoarseNet和RefineNet)来合成自然的说话视频。CoarseNet估计粗略的运动以产生新姿态的动画图像,而RefineNet通过从低到高的分辨率逐步估计唇部运动来专注于学习更精细的唇部运动,从而提高唇音同步性能。实验表明,与仅文本或仅音频相比,我们的姿态预测策略实现了更好的姿态多样性和真实感,并且我们的视频生成器模型在合成具有自然头部运动的说话视频方面优于最先进的方法。
🔬 方法详解
问题定义:现有音频驱动的说话人头部生成方法通常难以保证生成的头部姿态和唇部运动与输入音频精确同步,并且缺乏对头部姿态的灵活编辑能力。现有的方法要么只依赖音频信息,要么只依赖文本信息,无法充分利用多模态信息进行姿态控制。此外,在训练过程中,唇部区域的损失贡献较小,导致模型优化偏向于头部运动,而忽略了唇部细节。
核心思路:PoseTalk的核心思路是利用头部姿态作为连接视觉、语言和音频信号的桥梁。通过结合文本提供的长期语义信息和音频提供的短期节奏信息,生成更自然和可控的头部姿态。同时,采用细化学习策略,专门优化唇部运动,以提高唇音同步的准确性。
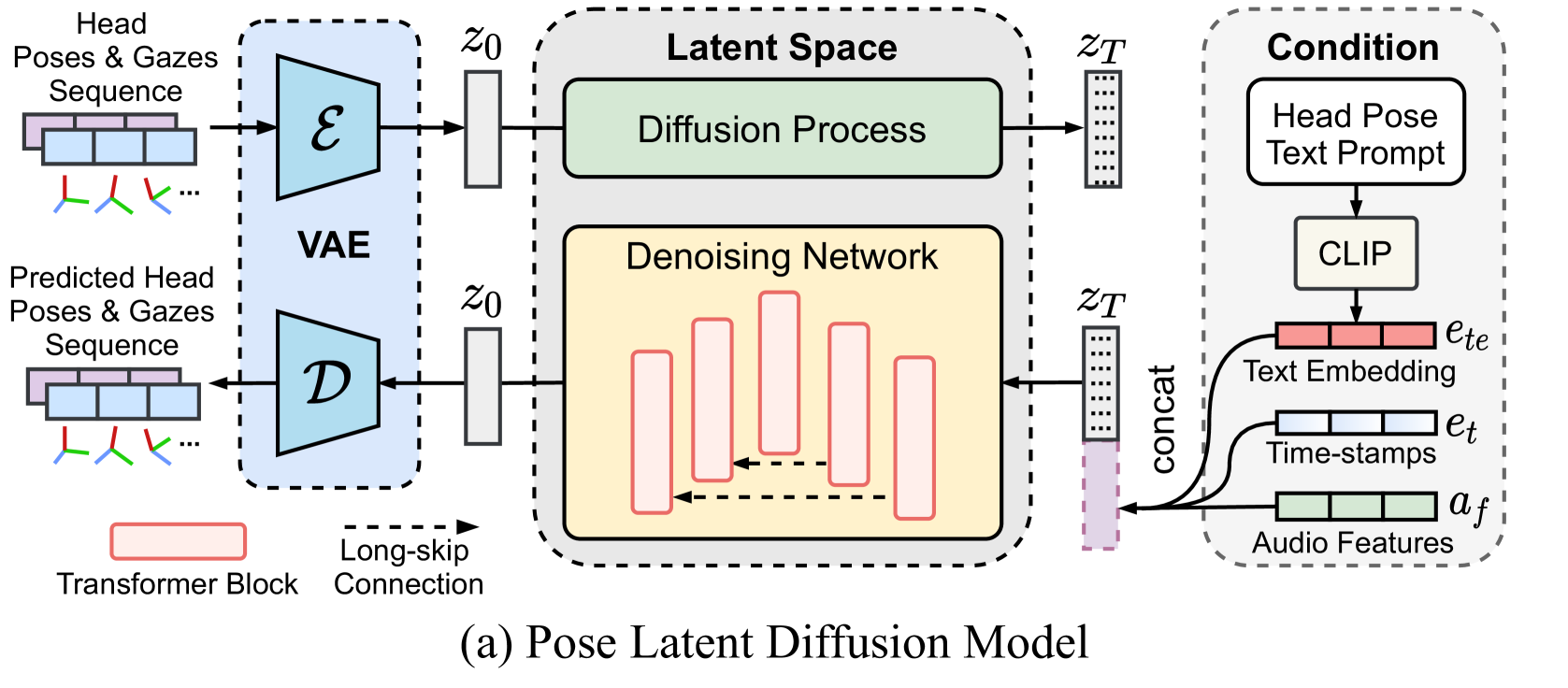
技术框架:PoseTalk系统包含两个主要模块:姿态潜在扩散(PLD)模型和视频生成器。PLD模型负责从文本和音频生成头部姿态的潜在表示。视频生成器由CoarseNet和RefineNet两个级联网络组成。CoarseNet生成粗略的头部运动和图像,RefineNet则专注于优化唇部运动,生成高分辨率的唇部细节。
关键创新:PoseTalk的关键创新在于:1) 提出了一种结合文本和音频信息的姿态生成方法,能够生成更具多样性和真实感的头部姿态。2) 引入了细化学习策略,通过级联网络专门优化唇部运动,解决了损失不平衡问题,显著提高了唇音同步的准确性。3) 使用姿态潜在扩散模型,实现了对姿态的潜在空间操作,从而可以灵活控制头部运动。
关键设计:PLD模型使用扩散模型学习姿态的潜在空间表示,并使用文本编码器和音频编码器提取文本和音频特征,然后将这些特征融合到扩散模型的采样过程中。CoarseNet和RefineNet都采用U-Net结构,RefineNet在不同分辨率上逐步估计唇部运动,并使用对抗损失和重建损失进行训练。损失函数的设计侧重于平衡头部运动和唇部运动的优化,特别强调了唇部区域的损失权重。
🖼️ 关键图片
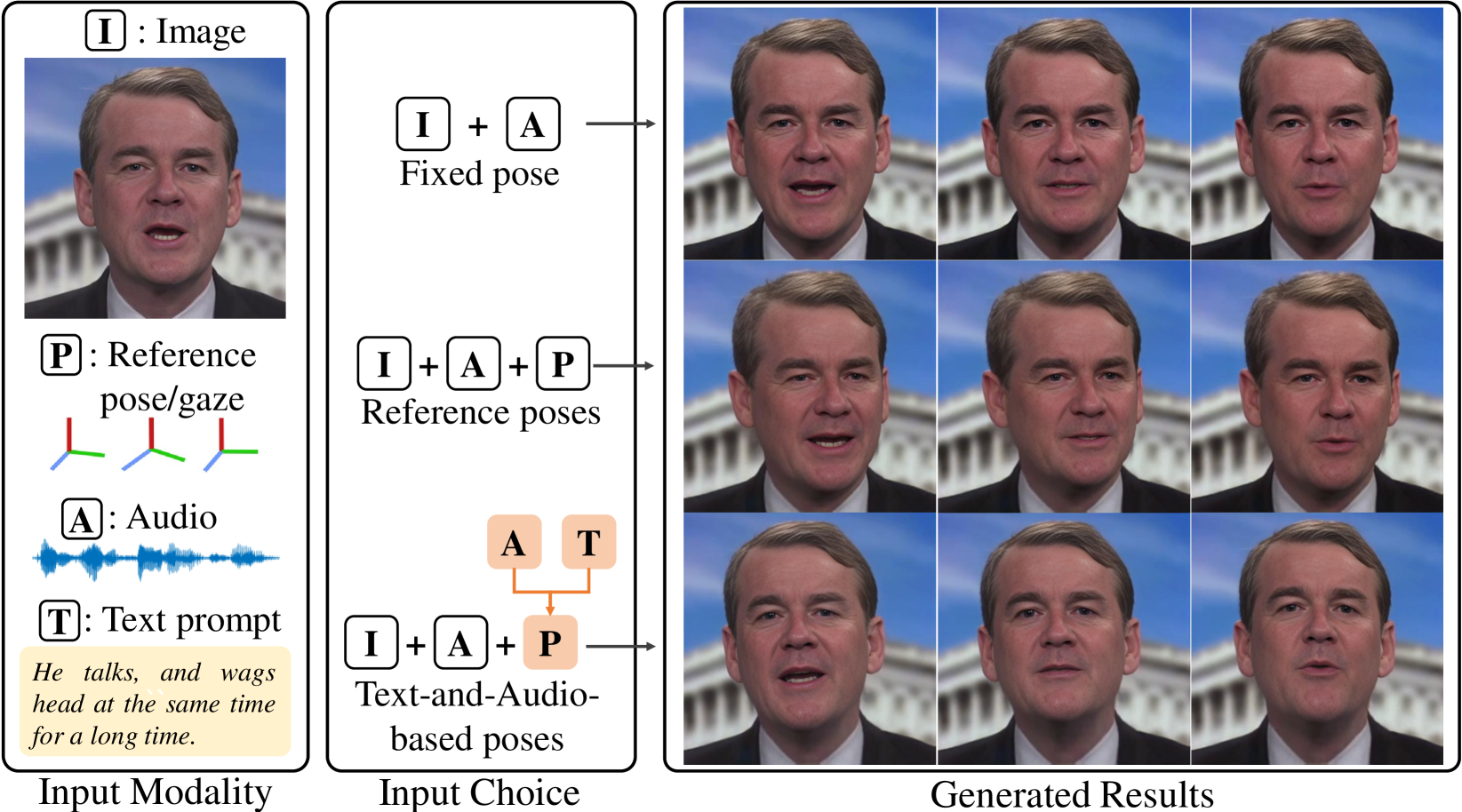
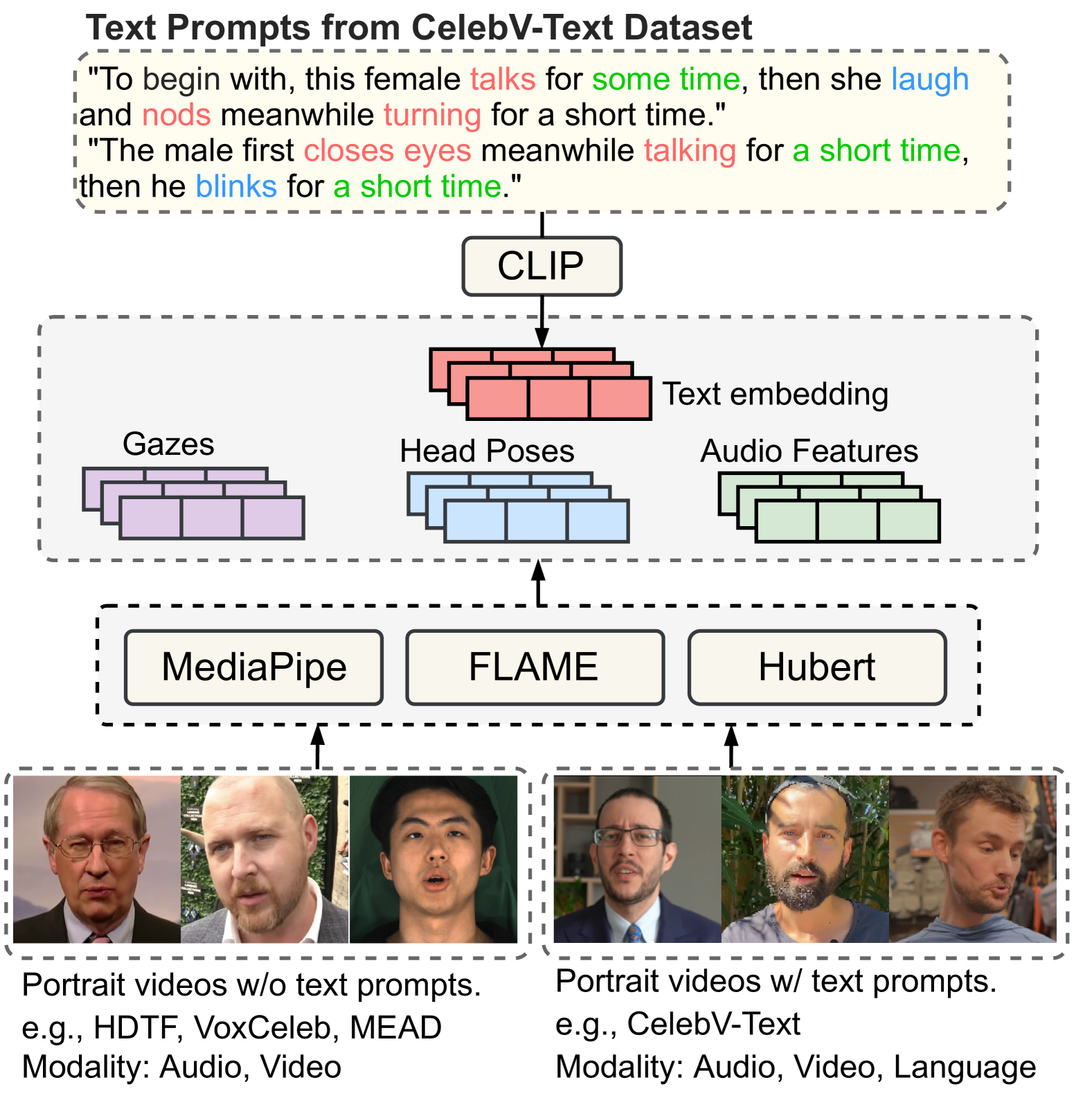
📊 实验亮点
实验结果表明,PoseTalk在姿态多样性和真实感方面优于仅使用文本或音频的方法。在唇音同步方面,PoseTalk显著优于现有方法,能够生成更自然和逼真的说话人视频。通过消融实验验证了细化学习策略和姿态潜在扩散模型的有效性。
🎯 应用场景
PoseTalk具有广泛的应用前景,包括虚拟主播、个性化视频生成、在线教育、电影制作和游戏开发等领域。该技术可以用于创建更逼真、更具表现力的虚拟角色,并为用户提供更个性化的视频内容生成体验。未来,PoseTalk有望成为人机交互和数字内容创作的重要工具。
📄 摘要(原文)
While previous audio-driven talking head generation (THG) methods generate head poses from driving audio, the generated poses or lips cannot match the audio well or are not editable. In this study, we propose \textbf{PoseTalk}, a THG system that can freely generate lip-synchronized talking head videos with free head poses conditioned on text prompts and audio. The core insight of our method is using head pose to connect visual, linguistic, and audio signals. First, we propose to generate poses from both audio and text prompts, where the audio offers short-term variations and rhythm correspondence of the head movements and the text prompts describe the long-term semantics of head motions. To achieve this goal, we devise a Pose Latent Diffusion (PLD) model to generate motion latent from text prompts and audio cues in a pose latent space. Second, we observe a loss-imbalance problem: the loss for the lip region contributes less than 4\% of the total reconstruction loss caused by both pose and lip, making optimization lean towards head movements rather than lip shapes. To address this issue, we propose a refinement-based learning strategy to synthesize natural talking videos using two cascaded networks, i.e., CoarseNet, and RefineNet. The CoarseNet estimates coarse motions to produce animated images in novel poses and the RefineNet focuses on learning finer lip motions by progressively estimating lip motions from low-to-high resolutions, yielding improved lip-synchronization performance. Experiments demonstrate our pose prediction strategy achieves better pose diversity and realness compared to text-only or audio-only, and our video generator model outperforms state-of-the-art methods in synthesizing talking videos with natural head motions. Project: https://junleen.github.io/projects/posetalk.