Convolutional Networks as Extremely Small Foundation Models: Visual Prompting and Theoretical Perspective
作者: Jianqiao Wangni
分类: cs.CV
发布日期: 2024-09-03
💡 一句话要点
提出基于卷积网络的极小基础模型,通过视觉提示实现视频目标分割的快速迁移。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频对象分割 视觉提示 半参数模型 深度森林 迁移学习 泛化能力 卷积神经网络
📋 核心要点
- 现有深度网络在特定任务上训练,泛化能力受限,且训练成本高昂,难以适应新任务。
- 论文提出一种视觉提示模块,利用预训练的通用深度网络,结合非参数方法,实现快速迁移和泛化。
- 实验表明,该方法在视频对象分割任务上取得了与深度学习方法相当的性能,且计算成本极低,无需训练。
📝 摘要(中文)
本文提出了一种视觉提示模块,旨在将通用深度网络快速适应到新任务中,受益于大规模数据集上训练的基础网络、更简单的网络结构和更易于训练的技术。受到学习理论的驱动,我们推导出尽可能简单的提示模块,因为在相同的训练误差下,它们具有更好的泛化能力。我们以视频对象分割为例进行了实验。我们给出了一个具体的提示模块,即半参数深度森林(SDForest),它将相关滤波器、随机森林、图像引导滤波器等非参数方法与为ImageNet分类任务训练的深度网络相结合。从学习理论的角度来看,所有这些模型的VC维或复杂度都显著降低,因此往往具有更好的泛化能力,只要经验研究表明,这种简单集成的训练误差可以达到与端到端训练的深度网络相当的结果。我们还提出了一种新的视频对象分割泛化分析方法,以使边界更紧。在实践中,SDForest的计算成本极低,甚至可以在CPU上实现实时性。我们在视频对象分割任务上进行了测试,并在DAVIS2016和DAVIS2017上取得了与纯深度学习方法具有竞争力的性能,而无需任何训练或微调。
🔬 方法详解
问题定义:视频对象分割任务需要精确地分割视频中的目标对象。现有方法通常依赖于端到端训练的深度网络,这些网络需要大量的标注数据和计算资源,并且泛化能力有限,难以适应新的视频场景。
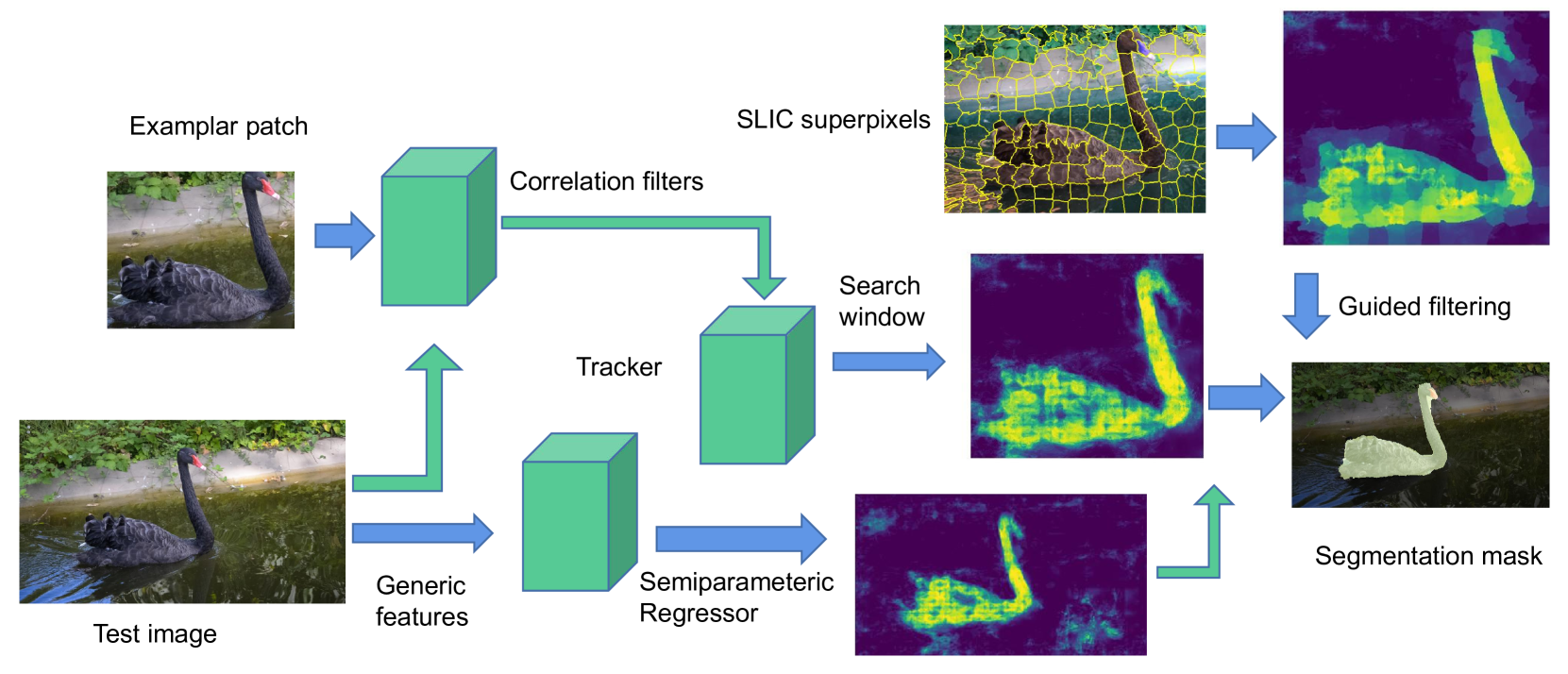
核心思路:论文的核心思路是将预训练的通用深度网络作为特征提取器,然后利用轻量级的非参数方法(如相关滤波器、随机森林、图像引导滤波器)构建一个提示模块,从而实现快速适应和泛化。这种方法避免了从头开始训练深度网络,降低了计算成本,并提高了泛化能力。
技术框架:整体框架包括两个主要部分:1) 预训练的深度网络,用于提取图像特征;2) 半参数深度森林(SDForest)提示模块,用于结合深度特征和非参数方法进行目标分割。SDForest包含相关滤波器用于目标跟踪,随机森林用于像素分类,图像引导滤波器用于平滑分割结果。
关键创新:最重要的创新点在于将深度学习的特征提取能力与非参数方法的快速适应能力相结合,构建了一个轻量级的提示模块。这种方法避免了端到端训练深度网络的需要,降低了计算成本,并提高了泛化能力。此外,论文还提出了一种新的视频对象分割泛化分析方法,以获得更紧的泛化边界。
关键设计:SDForest的关键设计包括:1) 使用预训练的ImageNet分类网络作为特征提取器;2) 使用相关滤波器跟踪目标对象;3) 使用随机森林对像素进行分类,区分前景和背景;4) 使用图像引导滤波器平滑分割结果,减少噪声。这些组件的参数设置和集成方式经过精心设计,以实现最佳的性能和效率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SDForest在DAVIS2016和DAVIS2017视频对象分割数据集上取得了与纯深度学习方法具有竞争力的性能,而无需任何训练或微调。该方法在CPU上也能实现实时处理,计算成本极低。这些结果验证了该方法在实际应用中的可行性和有效性。
🎯 应用场景
该研究成果可应用于视频监控、自动驾驶、机器人视觉等领域,实现快速、低成本的目标分割和跟踪。通过利用预训练模型和轻量级提示模块,可以显著降低计算资源需求,并提高在不同场景下的适应能力。未来可扩展到其他视觉任务,如图像编辑、视频分析等。
📄 摘要(原文)
Comparing to deep neural networks trained for specific tasks, those foundational deep networks trained on generic datasets such as ImageNet classification, benefits from larger-scale datasets, simpler network structure and easier training techniques. In this paper, we design a prompting module which performs few-shot adaptation of generic deep networks to new tasks. Driven by learning theory, we derive prompting modules that are as simple as possible, as they generalize better under the same training error. We use a case study on video object segmentation to experiment. We give a concrete prompting module, the Semi-parametric Deep Forest (SDForest) that combines several nonparametric methods such as correlation filter, random forest, image-guided filter, with a deep network trained for ImageNet classification task. From a learning-theoretical point of view, all these models are of significantly smaller VC dimension or complexity so tend to generalize better, as long as the empirical studies show that the training error of this simple ensemble can achieve comparable results from a end-to-end trained deep network. We also propose a novel methods of analyzing the generalization under the setting of video object segmentation to make the bound tighter. In practice, SDForest has extremely low computation cost and achieves real-time even on CPU. We test on video object segmentation tasks and achieve competitive performance at DAVIS2016 and DAVIS2017 with purely deep learning approaches, without any training or fine-tuning.