AstroMAE: Redshift Prediction Using a Masked Autoencoder with a Novel Fine-Tuning Architecture
作者: Amirreza Dolatpour Fathkouhi, Geoffrey Charles Fox
分类: cs.CV, astro-ph.GA, astro-ph.IM, cs.CE, cs.LG
发布日期: 2024-09-03
备注: This paper has been accepted to 2024 IEEE 20th International Conference on e-Science
💡 一句话要点
AstroMAE:提出一种基于掩码自编码器和新型微调架构的红移预测方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 红移预测 掩码自编码器 视觉Transformer 自监督学习 天文图像处理
📋 核心要点
- 传统红移预测方法依赖大量标注数据和人工特征提取,泛化能力受限。
- AstroMAE利用掩码自编码器预训练视觉Transformer,无需标签即可学习图像全局特征。
- 实验表明,AstroMAE优于其他视觉Transformer和CNN模型,提升了红移预测精度。
📝 摘要(中文)
红移预测是天文学中的一项基本任务,对于理解宇宙的膨胀和确定天文物体的距离至关重要。精确的红移预测在推进我们对宇宙的认知方面起着关键作用。机器学习(ML)方法以其精度和速度而闻名,为这项复杂的任务提供了有希望的解决方案。然而,传统的ML算法严重依赖于带标签的数据和特定于任务的特征提取。为了克服这些限制,我们引入了AstroMAE,这是一种创新的方法,它使用掩码自编码器方法在斯隆数字巡天(SDSS)图像上预训练视觉Transformer编码器。这项技术使编码器能够在不依赖标签的情况下捕获数据中的全局模式。据我们所知,AstroMAE代表了掩码自编码器在天文数据中的首次应用。通过在预训练阶段忽略标签,编码器可以获得对数据的一般理解。预训练的编码器随后在专门为红移预测量身定制的架构中进行微调。我们针对各种视觉Transformer架构和基于CNN的模型评估了我们的模型,证明了AstroMAE预训练模型和微调架构的卓越性能。
🔬 方法详解
问题定义:论文旨在解决天文学中红移预测的问题。现有方法,特别是传统的机器学习算法,依赖于大量带标签的数据和人工设计的特征提取过程。这不仅耗时耗力,而且模型的泛化能力受到限制,难以适应不同类型的天文数据。因此,需要一种能够自动学习数据特征,并且对未标注数据具有鲁棒性的红移预测方法。
核心思路:AstroMAE的核心思路是利用自监督学习中的掩码自编码器(MAE)进行预训练。通过在大量未标注的SDSS图像上进行预训练,模型能够学习到图像的内在结构和全局特征,而无需依赖人工标注。预训练后的编码器可以作为特征提取器,然后在一个专门设计的微调架构中进行微调,以完成红移预测任务。
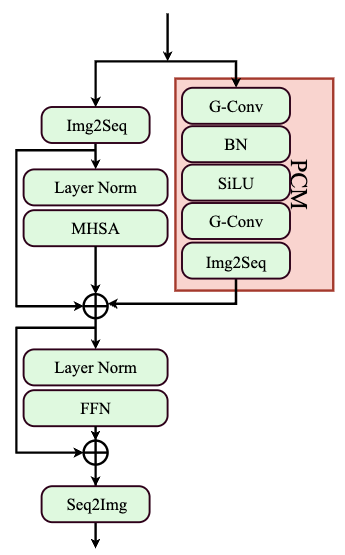
技术框架:AstroMAE的整体框架包括两个主要阶段:预训练阶段和微调阶段。在预训练阶段,使用掩码自编码器对视觉Transformer编码器进行训练。具体来说,随机掩盖输入图像的部分区域,然后让编码器学习重建被掩盖的区域。在微调阶段,将预训练的编码器与一个专门设计的红移预测模块连接起来,并在带标签的数据上进行微调。
关键创新:AstroMAE的关键创新在于将掩码自编码器应用于天文数据,并提出了一个针对红移预测的微调架构。这是首次尝试使用MAE进行天文图像的特征学习,并且通过预训练,模型能够学习到更鲁棒和泛化的特征表示。
关键设计:在预训练阶段,采用了标准的MAE架构,掩码比例是一个重要的超参数,需要根据具体数据集进行调整。在微调阶段,设计了一个专门的红移预测模块,该模块可以根据预训练编码器提取的特征进行红移预测。损失函数通常采用均方误差或交叉熵损失,具体选择取决于红移预测任务的性质(回归或分类)。
🖼️ 关键图片


📊 实验亮点
AstroMAE在红移预测任务上表现出色,优于传统的CNN和Transformer模型。通过在SDSS数据集上进行实验,证明了AstroMAE预训练模型和微调架构的有效性。具体性能数据(例如,预测精度、均方误差等)需要在论文中查找,但总体而言,AstroMAE在红移预测精度方面取得了显著提升。
🎯 应用场景
AstroMAE在天文学领域具有广泛的应用前景,可用于大规模星系巡天数据的红移预测,加速宇宙学研究。精确的红移信息对于研究宇宙的膨胀历史、暗物质分布以及星系的形成和演化至关重要。该方法还可以推广到其他天文图像分析任务,例如星系分类、天体探测等,具有重要的科研价值。
📄 摘要(原文)
Redshift prediction is a fundamental task in astronomy, essential for understanding the expansion of the universe and determining the distances of astronomical objects. Accurate redshift prediction plays a crucial role in advancing our knowledge of the cosmos. Machine learning (ML) methods, renowned for their precision and speed, offer promising solutions for this complex task. However, traditional ML algorithms heavily depend on labeled data and task-specific feature extraction. To overcome these limitations, we introduce AstroMAE, an innovative approach that pretrains a vision transformer encoder using a masked autoencoder method on Sloan Digital Sky Survey (SDSS) images. This technique enables the encoder to capture the global patterns within the data without relying on labels. To the best of our knowledge, AstroMAE represents the first application of a masked autoencoder to astronomical data. By ignoring labels during the pretraining phase, the encoder gathers a general understanding of the data. The pretrained encoder is subsequently fine-tuned within a specialized architecture tailored for redshift prediction. We evaluate our model against various vision transformer architectures and CNN-based models, demonstrating the superior performance of AstroMAEs pretrained model and fine-tuning architecture.