VideoLLaMB: Long Streaming Video Understanding with Recurrent Memory Bridges
作者: Yuxuan Wang, Yiqi Song, Cihang Xie, Yang Liu, Zilong Zheng
分类: cs.CV, cs.CL
发布日期: 2024-09-02 (更新: 2025-08-02)
备注: To appear at ICCV 2025
💡 一句话要点
VideoLLaMB:利用循环记忆桥实现长时流视频理解
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 长视频理解 视频语言模型 循环记忆桥 时间记忆令牌 视频问答 视频规划 帧检索
📋 核心要点
- 现有视频语言模型计算成本高昂,且缺乏足够的标注数据,限制了其在学术研究中的应用。
- VideoLLaMB通过循环记忆桥和时间记忆令牌,实现长视频的无缝编码和语义连续性保持。
- 实验表明,VideoLLaMB在多个视频理解任务上超越现有模型,并具有良好的可扩展性和成本效益。
📝 摘要(中文)
大规模视频语言模型在实时规划和精细交互方面展现出巨大潜力。然而,其高计算需求和标注数据集的稀缺性限制了学术研究的实用性。本文提出了VideoLLaMB,一种新颖高效的长视频理解框架,它利用循环记忆桥和时间记忆令牌,实现对整个视频序列的无缝编码,并保持语义连续性。该方法的核心是SceneTiling算法,它将视频分割成连贯的语义单元,从而在不需要额外训练的情况下,促进跨任务的鲁棒理解。VideoLLaMB取得了最先进的性能,在四个VideoQA基准测试中超过现有模型4.2个百分点,在以自我为中心的规划任务中超过2.06个百分点。值得注意的是,它在极端的视频长度缩放(高达8倍)下保持了强大的性能,并在我们提出的“视频大海捞针”(NIAVH)基准测试中擅长细粒度的帧检索。凭借线性GPU内存缩放,VideoLLaMB使用单个Nvidia A100 GPU处理多达320帧,尽管仅在16帧上进行训练,从而提供了前所未有的准确性、可扩展性和成本效益的平衡。这使其对于学术界来说非常容易访问和实用。
🔬 方法详解
问题定义:现有视频语言模型在处理长视频时,面临计算资源消耗大和难以保持语义连贯性的问题。传统的Transformer架构在处理长序列时,计算复杂度呈平方级增长,导致难以扩展到长视频。此外,缺乏有效的机制来维护视频帧之间的语义关系,导致模型难以进行长时序的推理和理解。
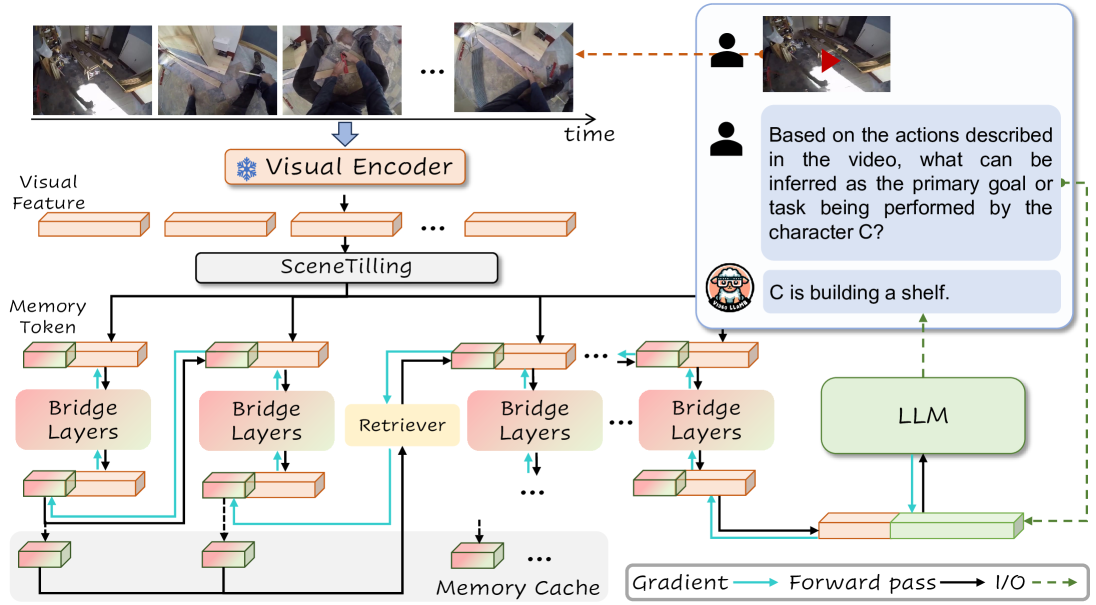
核心思路:VideoLLaMB的核心思路是利用循环记忆桥(Recurrent Memory Bridges)和时间记忆令牌(Temporal Memory Tokens)来解决长视频理解中的计算效率和语义连贯性问题。循环记忆桥允许模型在处理后续视频片段时,能够利用之前片段的信息,从而避免重复计算。时间记忆令牌则用于显式地编码视频帧之间的时序关系,帮助模型更好地理解视频的上下文。
技术框架:VideoLLaMB的整体框架包括以下几个主要模块:1) SceneTiling:将视频分割成语义连贯的单元。2) 视频编码器:使用预训练的视觉模型(例如CLIP)提取视频帧的特征。3) 循环记忆桥:将当前视频片段的特征与之前的记忆信息融合。4) 时间记忆令牌:编码视频帧之间的时序关系。5) 语言模型:使用大型语言模型(例如LLaMA)进行视频理解和推理。
关键创新:VideoLLaMB的关键创新在于循环记忆桥和时间记忆令牌的设计。循环记忆桥通过循环的方式传递信息,有效地降低了计算复杂度,并保持了语义的连贯性。时间记忆令牌则显式地编码了视频帧之间的时序关系,提高了模型对视频上下文的理解能力。此外,SceneTiling算法也能够将视频分割成语义连贯的单元,进一步提高了模型的性能。
关键设计:SceneTiling算法使用基于变化的分割方法,将视频分割成语义连贯的片段。循环记忆桥使用GRU(Gated Recurrent Unit)来融合当前片段的特征和之前的记忆信息。时间记忆令牌的数量是一个可调节的超参数,用于控制模型对时序信息的关注程度。损失函数包括视频问答损失、规划损失和帧检索损失。
🖼️ 关键图片
📊 实验亮点
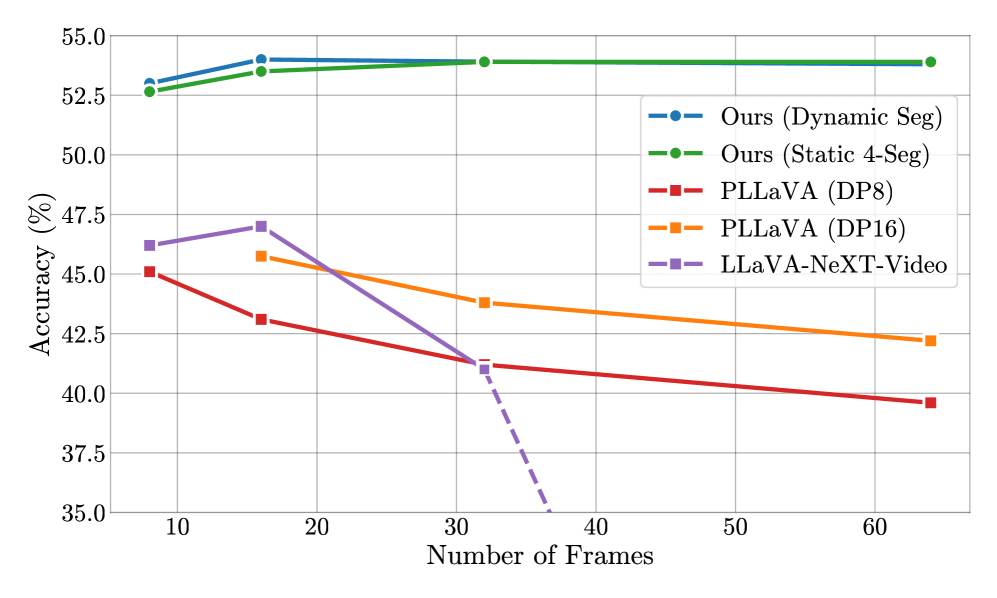
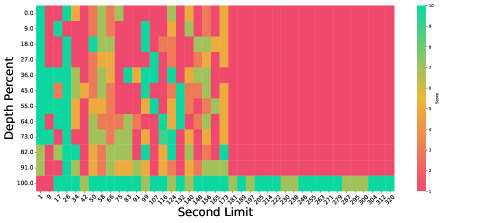
VideoLLaMB在四个VideoQA基准测试中,超越现有模型4.2个百分点,在以自我为中心的规划任务中,超越2.06个百分点。在极端的视频长度缩放(高达8倍)下,依然保持了强大的性能。在提出的NIAVH基准测试中,擅长细粒度的帧检索。使用单张A100 GPU,可以处理多达320帧,展示了良好的可扩展性和成本效益。
🎯 应用场景
VideoLLaMB在视频监控、自动驾驶、机器人导航、视频编辑和智能助手等领域具有广泛的应用前景。它可以用于实时分析监控视频中的异常事件,帮助自动驾驶车辆理解周围环境,辅助机器人进行复杂任务规划,提高视频编辑的效率,并为用户提供更智能的视频相关服务。该研究的成果将推动视频理解技术的发展,并为各行各业带来实际价值。
📄 摘要(原文)
Recent advancements in large-scale video-language models have shown significant potential for real-time planning and detailed interactions. However, their high computational demands and the scarcity of annotated datasets limit their practicality for academic researchers. In this work, we introduce VideoLLaMB, a novel and efficient framework for long video understanding that leverages recurrent memory bridges and temporal memory tokens to enable seamless encoding of entire video sequences with preserved semantic continuity. Central to our approach is a SceneTiling algorithm that segments videos into coherent semantic units, facilitating robust understanding across tasks without requiring additional training. VideoLLaMB achieves state-of-the-art performance, surpassing existing models by 4.2 points on four VideoQA benchmarks and by 2.06 points on egocentric planning tasks. Notably, it maintains strong performance under extreme video length scaling (up to 8 times) and excels at fine-grained frame retrieval on our proposed Needle in a Video Haystack (NIAVH) benchmark. With linear GPU memory scaling, VideoLLaMB processes up to 320 frames using a single Nvidia A100 GPU, despite being trained on only 16 frames-offering an unprecedented balance of accuracy, scalability, and cost-effectiveness. This makes it highly accessible and practical for the academic community.