Digit Recognition using Multimodal Spiking Neural Networks
作者: William Bjorndahl, Jack Easton, Austin Modoff, Eric C. Larson, Joseph Camp, Prasanna Rangarajan
分类: eess.AS, cs.CV, cs.MM, cs.SD
发布日期: 2024-08-31
备注: 4 pages, 2 figures, submitted to 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing
💡 一句话要点
提出一种多模态脉冲神经网络,用于融合视觉和听觉信息以提升数字识别精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脉冲神经网络 多模态融合 事件相机 数字识别 神经形态计算
📋 核心要点
- 现有数字识别方法难以有效融合来自不同模态(如视觉和听觉)的事件数据,限制了识别精度。
- 提出一种多模态脉冲神经网络,通过神经形态计算特性,有效融合视觉和听觉事件数据。
- 实验结果表明,该方法在N-MNIST和SHD数据集上取得了98.43%的准确率,优于单模态SNN。
📝 摘要(中文)
脉冲神经网络(SNNs)是第三代神经网络,其生物灵感来源于模拟大脑中的信号交换方式。在计算机视觉领域,SNNs因事件相机的发展而备受关注,事件相机能够响应场景亮度的变化,产生空间分辨的脉冲序列。SNNs常用于处理事件数据,因为它们具有神经形态特性。本研究探讨了在分类任务中融合多种感觉输入所带来的神经形态优势。具体而言,我们研究了SNN在数字分类中的性能,通过输入视觉模态分支(Neuromorphic-MNIST [N-MNIST])和听觉模态分支(Spiking Heidelberg Digits [SHD]),这些数据集均由事件相机生成的时间依赖事件序列构成。实验结果表明,多模态SNN优于单模态视觉和单模态听觉SNN。此外,感觉融合的过程对视觉和听觉分支的融合深度不敏感。该研究使用在较深层连接视觉和听觉分支的多模态SNN,在N-MNIST和SHD组合数据集上实现了98.43%的准确率。
🔬 方法详解
问题定义:论文旨在解决如何有效融合来自不同模态(视觉和听觉)的事件数据,以提高数字识别的准确率。现有方法在处理这种多模态事件数据时,往往无法充分利用SNN的神经形态计算优势,导致性能受限。
核心思路:论文的核心思路是利用脉冲神经网络(SNN)的神经形态特性,通过构建多模态SNN,直接处理来自事件相机的视觉和听觉事件数据。通过在SNN中融合不同模态的信息,模拟生物神经系统的信息处理方式,从而提高识别精度。
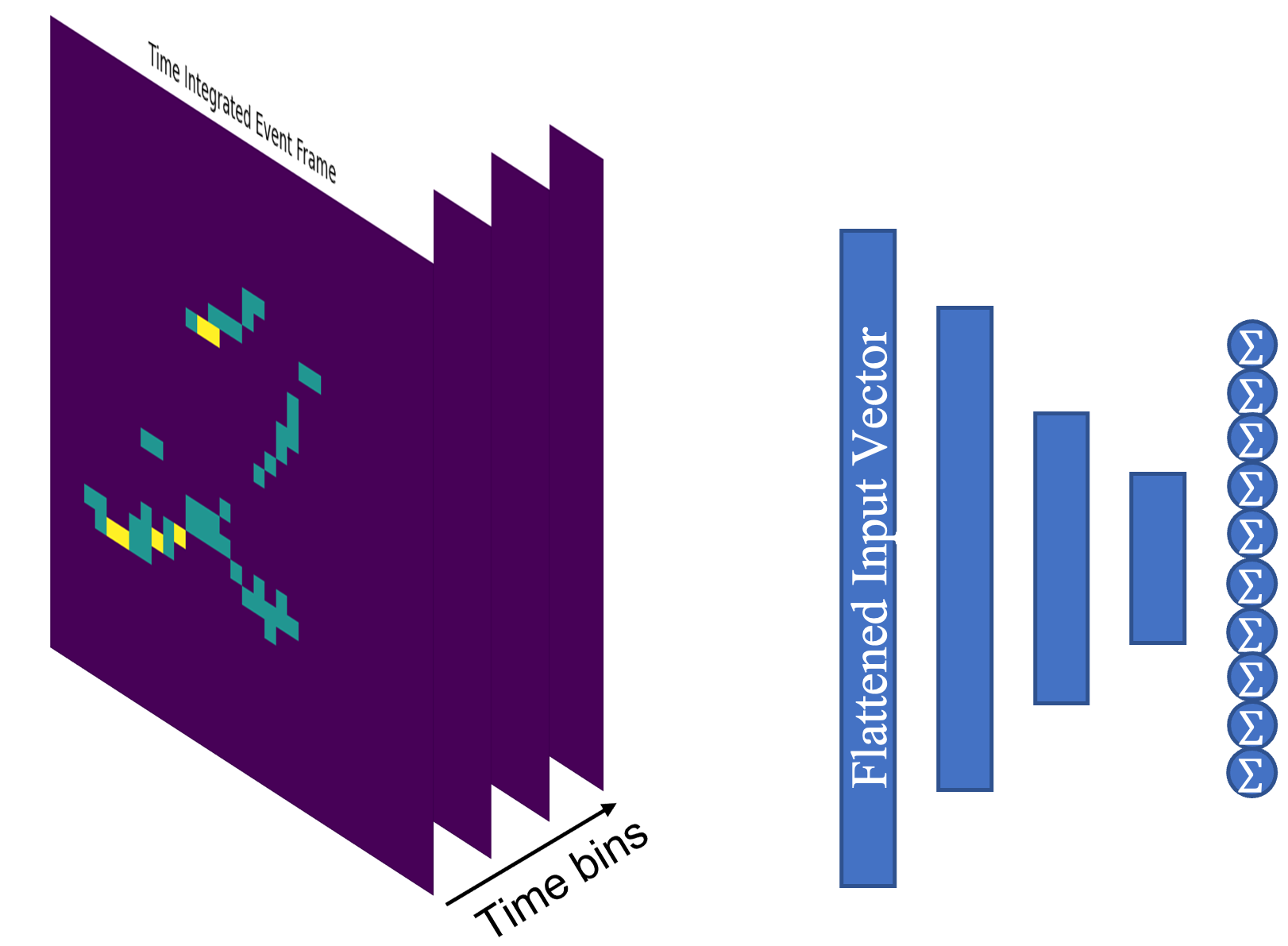
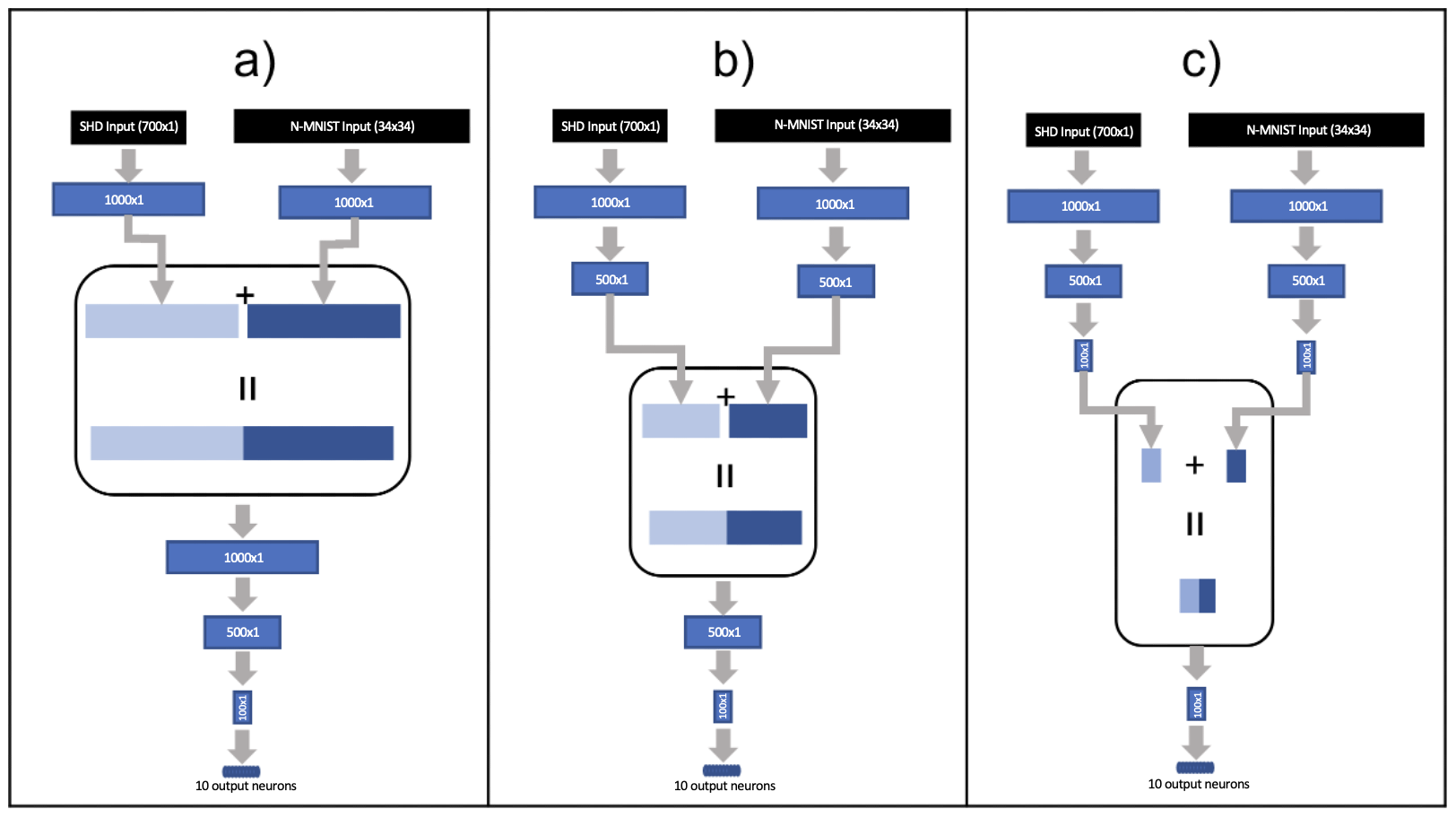
技术框架:该方法的技术框架主要包括两个分支:视觉模态分支(N-MNIST数据集)和听觉模态分支(SHD数据集)。这两个分支分别由SNN构成,用于处理各自模态的事件数据。在网络的较深层,将两个分支的输出进行连接(concatenation),形成多模态特征表示,然后输入到分类器进行数字识别。整体流程是:事件数据输入 -> 视觉/听觉SNN分支 -> 特征融合 -> 分类。
关键创新:该论文的关键创新在于探索了多模态SNN在事件数据处理中的应用,并验证了其优于单模态SNN的性能。此外,研究还发现感觉融合的过程对视觉和听觉分支的融合深度不敏感,这意味着可以在网络的较深层进行简单的特征连接,而无需复杂的融合策略。
关键设计:论文中,视觉和听觉分支的具体SNN结构未知,但强调了在较深层进行特征连接。损失函数和具体的网络参数设置也未知。重要的是,该研究关注的是多模态融合的架构,而非特定SNN结构的优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,多模态SNN在N-MNIST和SHD组合数据集上实现了98.43%的准确率,显著优于单模态视觉和单模态听觉SNN。此外,研究发现感觉融合的过程对视觉和听觉分支的融合深度不敏感,简化了多模态SNN的设计。
🎯 应用场景
该研究成果可应用于智能机器人、自动驾驶等领域,通过融合视觉和听觉等多模态信息,提高环境感知和理解能力。例如,在嘈杂环境中,机器人可以通过听觉信息辅助视觉识别,提高目标检测的准确性。未来,该方法有望扩展到更多模态的融合,提升智能系统的鲁棒性和适应性。
📄 摘要(原文)
Spiking neural networks (SNNs) are the third generation of neural networks that are biologically inspired to process data in a fashion that emulates the exchange of signals in the brain. Within the Computer Vision community SNNs have garnered significant attention due in large part to the availability of event-based sensors that produce a spatially resolved spike train in response to changes in scene radiance. SNNs are used to process event-based data due to their neuromorphic nature. The proposed work examines the neuromorphic advantage of fusing multiple sensory inputs in classification tasks. Specifically we study the performance of a SNN in digit classification by passing in a visual modality branch (Neuromorphic-MNIST [N-MNIST]) and an auditory modality branch (Spiking Heidelberg Digits [SHD]) from datasets that were created using event-based sensors to generate a series of time-dependent events. It is observed that multi-modal SNNs outperform unimodal visual and unimodal auditory SNNs. Furthermore, it is observed that the process of sensory fusion is insensitive to the depth at which the visual and auditory branches are combined. This work achieves a 98.43% accuracy on the combined N-MNIST and SHD dataset using a multimodal SNN that concatenates the visual and auditory branches at a late depth.