Training-Free Sketch-Guided Diffusion with Latent Optimization
作者: Sandra Zhang Ding, Jiafeng Mao, Kiyoharu Aizawa
分类: cs.CV
发布日期: 2024-08-31 (更新: 2025-05-07)
备注: 8 pages
💡 一句话要点
提出基于潜在空间优化的免训练草图引导扩散模型,实现精确图像生成控制
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 文本到图像生成 扩散模型 草图引导 潜在空间优化 免训练 图像编辑 内容创作
📋 核心要点
- 文本到图像生成模型在图像生成方面表现出色,但难以实现对生成结果的精确控制,尤其是在布局和结构方面。
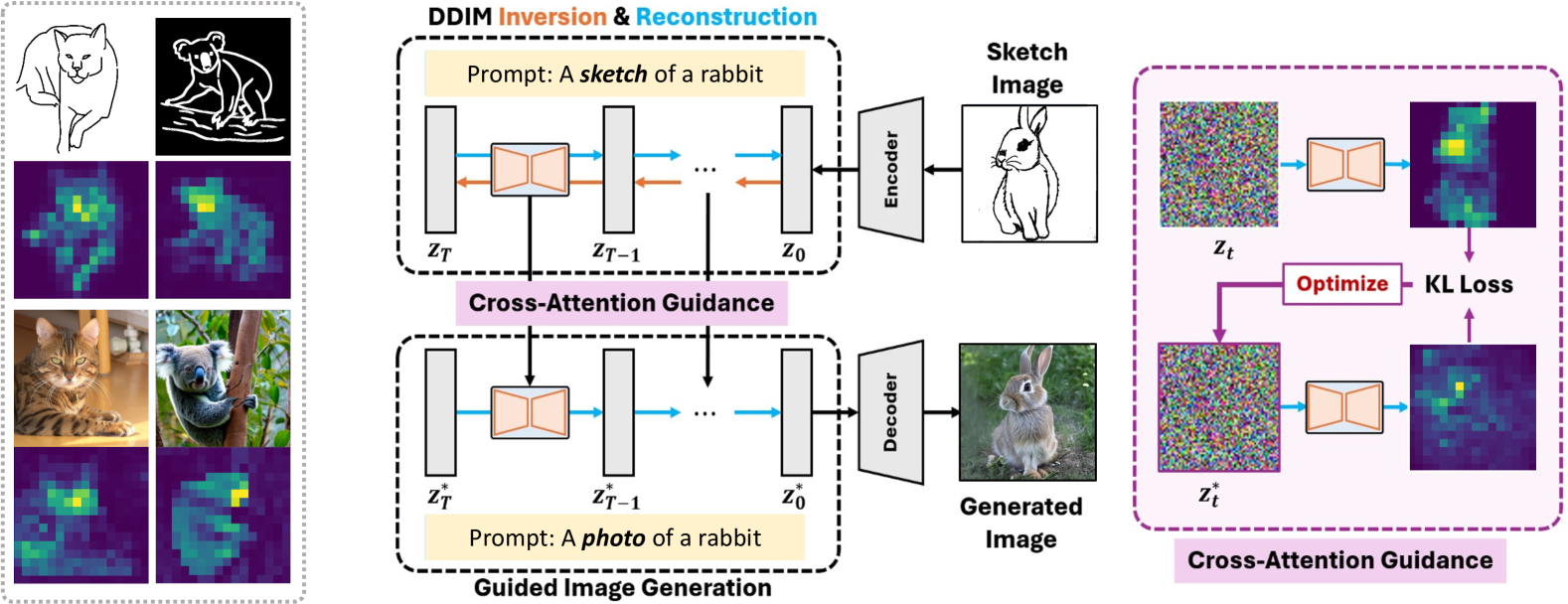
- 该论文提出一种免训练的草图引导扩散模型,通过潜在空间优化,利用交叉注意力图来约束生成过程,使图像结构与草图对齐。
- 通过潜在优化,该方法提高了图像生成的准确性,使用户能够更好地控制和定制生成内容,具有实际应用价值。
📝 摘要(中文)
本文提出了一种创新的免训练流程,旨在扩展现有的文本到图像(T2I)生成模型,使其能够整合草图作为附加条件。为了生成布局和结构与输入草图高度相似的新图像,我们发现草图的核心特征可以通过扩散模型的交叉注意力图进行追踪。我们引入了潜在优化方法,该方法在生成过程的每个中间步骤中,利用交叉注意力图来细化噪声潜在变量,从而确保生成的图像严格遵循参考草图中所概述的期望结构。通过潜在优化,我们的方法提高了图像生成的准确性,为用户在内容创作中提供了更大的控制和定制选项。
🔬 方法详解
问题定义:现有文本到图像生成模型虽然能够生成高质量和多样化的图像,但在实际应用中,用户难以精确控制生成图像的布局和结构,尤其是在需要参考草图进行创作时。现有的方法通常需要大量的训练数据和计算资源,且泛化能力有限。
核心思路:该论文的核心思路是利用扩散模型中的交叉注意力图来追踪草图的关键特征,并通过在潜在空间中优化噪声潜在变量,强制生成过程遵循草图的布局和结构。这种方法无需额外的训练,可以直接应用于现有的文本到图像生成模型。
技术框架:该方法主要包含以下几个阶段:1) 输入文本描述和参考草图;2) 使用现有的文本到图像扩散模型生成初始的噪声潜在变量;3) 在扩散模型的每个中间步骤,计算交叉注意力图,并利用这些注意力图来指导潜在变量的优化;4) 通过优化后的潜在变量生成最终的图像。
关键创新:该方法最重要的创新点在于提出了“潜在优化”的概念,即在扩散模型的潜在空间中,通过优化噪声潜在变量来控制生成过程,使其更好地符合参考草图的布局和结构。这种方法无需额外的训练,可以直接应用于现有的文本到图像生成模型,具有很强的通用性和灵活性。
关键设计:关键设计包括:1) 如何有效地利用交叉注意力图来提取草图的关键特征;2) 如何设计优化目标函数,以确保生成的图像既符合文本描述,又符合草图的布局和结构;3) 如何平衡文本描述和草图约束之间的关系,避免过度拟合草图。
🖼️ 关键图片


📊 实验亮点
该论文提出了一种免训练的草图引导图像生成方法,通过潜在空间优化,实现了对生成图像布局和结构的精确控制。实验结果表明,该方法能够有效地将草图的结构信息融入到生成图像中,生成与草图高度一致的图像,且无需额外的训练数据和计算资源。具体性能数据未知,但定性结果表明该方法优于现有方法。
🎯 应用场景
该研究成果可广泛应用于图像编辑、内容创作、设计辅助等领域。例如,用户可以通过简单的草图和文本描述,快速生成符合特定要求的图像,极大地提高了创作效率和灵活性。该技术还可以应用于虚拟现实、游戏开发等领域,为用户提供更加个性化和定制化的内容体验。未来,该技术有望成为图像生成领域的重要组成部分。
📄 摘要(原文)
Based on recent advanced diffusion models, Text-to-image (T2I) generation models have demonstrated their capabilities to generate diverse and high-quality images. However, leveraging their potential for real-world content creation, particularly in providing users with precise control over the image generation result, poses a significant challenge. In this paper, we propose an innovative training-free pipeline that extends existing text-to-image generation models to incorporate a sketch as an additional condition. To generate new images with a layout and structure closely resembling the input sketch, we find that these core features of a sketch can be tracked with the cross-attention maps of diffusion models. We introduce latent optimization, a method that refines the noisy latent at each intermediate step of the generation process using cross-attention maps to ensure that the generated images adhere closely to the desired structure outlined in the reference sketch. Through latent optimization, our method enhances the accuracy of image generation, offering users greater control and customization options in content creation.