From Latent to Engine Manifolds: Analyzing ImageBind's Multimodal Embedding Space
作者: Andrew Hamara, Pablo Rivas
分类: cs.CV, cs.AI
发布日期: 2024-08-30
备注: The 26th International Conference on Artificial Intelligence (ICAI'24)
💡 一句话要点
利用ImageBind分析多模态嵌入空间,为在线汽配列表生成有意义的融合嵌入。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 ImageBind 嵌入学习 向量数据库 跨模态检索
📋 核心要点
- 现有在线汽配列表缺乏有效的多模态信息融合方法,难以准确理解帖子语义。
- 提出一种基于ImageBind的简单嵌入融合流程,捕获图像/文本对的重叠信息,生成联合嵌入。
- 实验表明,该方法生成的联合嵌入具有良好的语义质量,纯音频嵌入也能关联语义相似的列表。
📝 摘要(中文)
本研究探讨了ImageBind为在线汽车配件列表生成有意义的融合多模态嵌入的能力。我们提出了一种简单的嵌入融合工作流程,旨在捕获图像/文本对的重叠信息,最终将帖子的语义组合成一个联合嵌入。在将这些融合嵌入存储在向量数据库中后,我们进行了降维实验,并通过聚类和检查最靠近每个聚类质心的帖子,提供了经验证据来传达联合嵌入的语义质量。此外,我们使用ImageBind的新兴零样本跨模态检索的初步发现表明,纯音频嵌入可以与语义相似的市场列表相关联,这表明了未来研究的潜在途径。
🔬 方法详解
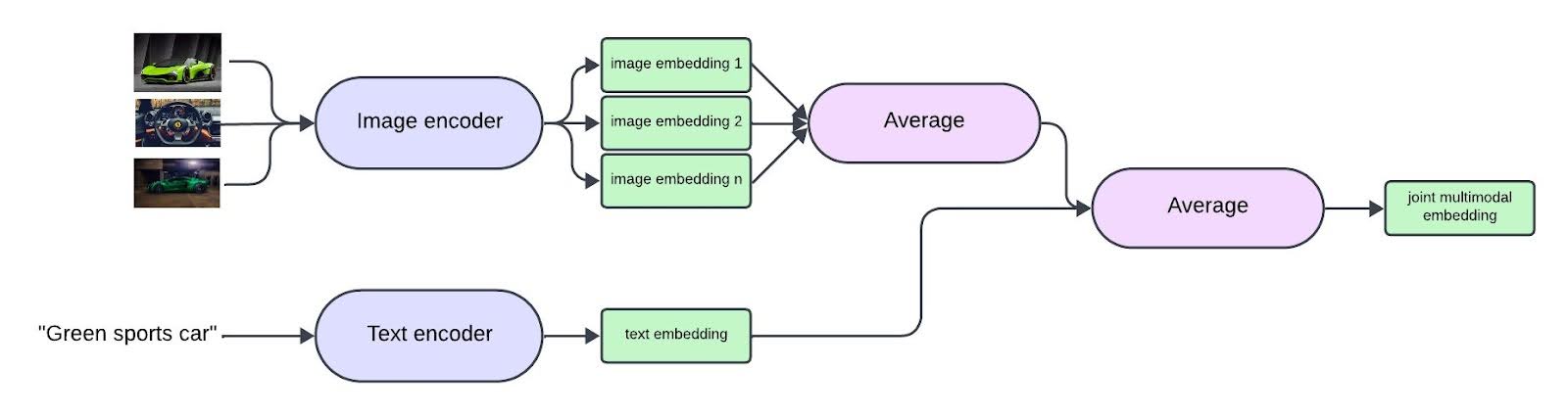
问题定义:论文旨在解决在线汽配列表中图像和文本信息融合的问题,现有方法难以有效利用多模态信息,导致无法准确理解帖子语义。具体来说,如何将图像和文本的语义信息有效地结合起来,生成一个能够代表帖子整体语义的联合嵌入是关键挑战。
核心思路:论文的核心思路是利用ImageBind模型强大的多模态表征能力,将图像和文本信息分别编码成嵌入向量,然后通过简单的融合策略(具体融合方式未知)将这些嵌入向量组合成一个联合嵌入。这样做的目的是希望ImageBind能够学习到图像和文本之间的关联性,从而使联合嵌入能够更好地捕捉帖子的整体语义。
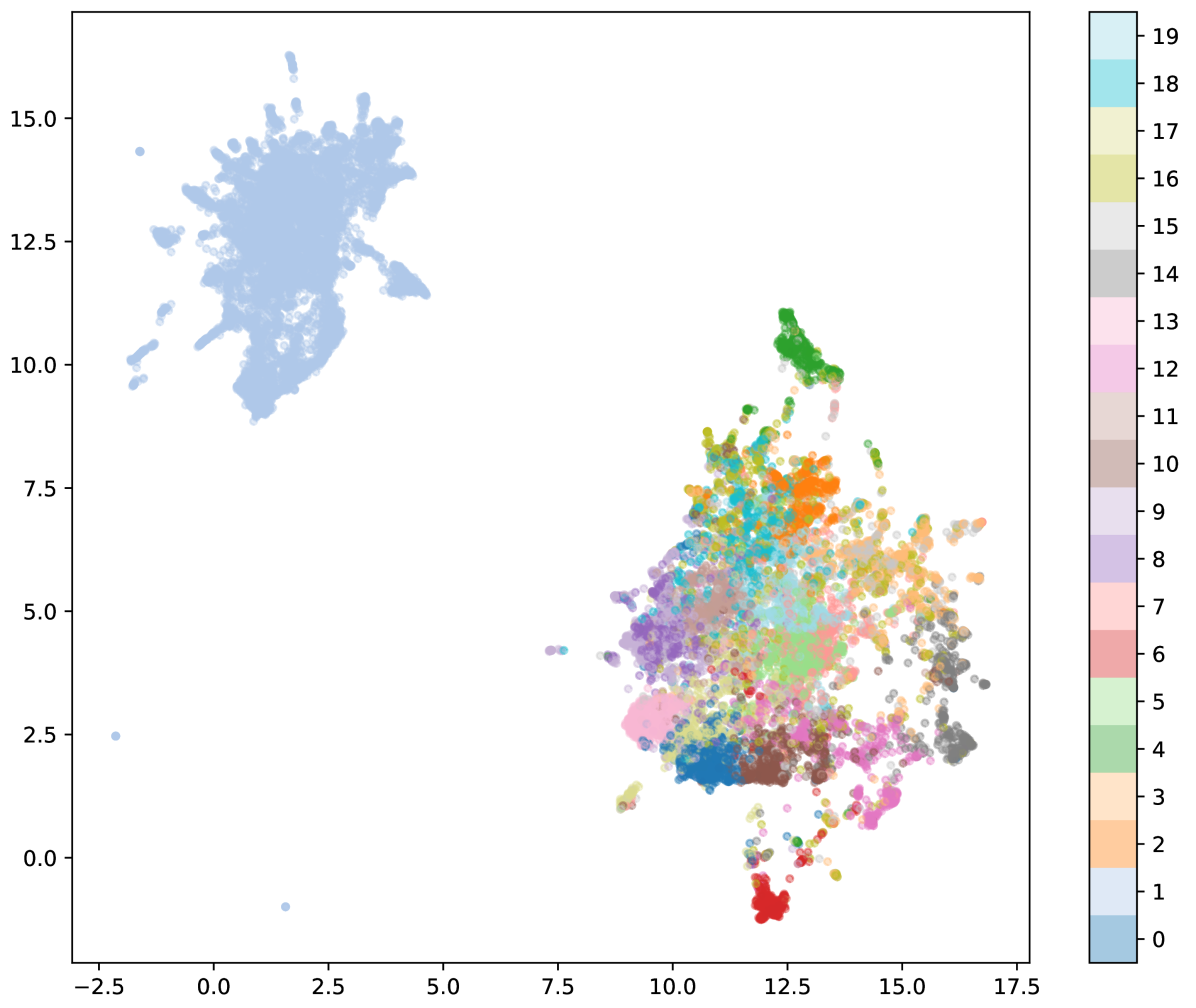
技术框架:整体流程包括以下几个步骤:1) 使用ImageBind分别提取图像和文本的嵌入向量;2) 使用某种融合策略(具体策略未知)将图像和文本嵌入融合为联合嵌入;3) 将联合嵌入存储在向量数据库中;4) 使用降维技术对嵌入进行可视化;5) 通过聚类分析和最近邻搜索来评估联合嵌入的语义质量。
关键创新:论文的关键创新在于将ImageBind模型应用于在线汽配列表的多模态信息融合任务,并探索了其零样本跨模态检索能力。虽然嵌入融合策略可能比较简单,但利用ImageBind强大的预训练能力,可以直接获得具有良好语义表征能力的联合嵌入,无需从头训练模型。
关键设计:论文中没有详细描述具体的融合策略,例如是使用简单的向量拼接、加权平均,还是更复杂的注意力机制。此外,论文也没有提供关于ImageBind模型参数设置、损失函数等方面的具体信息。这些细节的缺失使得方法的可复现性受到一定影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于ImageBind的嵌入融合方法能够生成具有良好语义质量的联合嵌入。通过聚类分析和最近邻搜索,可以发现语义相似的帖子聚集在一起,表明该方法能够有效地捕捉帖子的整体语义。此外,初步实验表明,纯音频嵌入可以与语义相似的市场列表相关联,为未来的跨模态检索研究提供了新的思路。
🎯 应用场景
该研究成果可应用于智能推荐系统、跨模态检索、内容审核等领域。例如,可以根据用户的搜索关键词(文本)或上传的图片,快速找到相关的汽车配件列表。此外,还可以利用音频信息进行辅助检索,例如通过识别发动机声音来推荐相关的维修服务。
📄 摘要(原文)
This study investigates ImageBind's ability to generate meaningful fused multimodal embeddings for online auto parts listings. We propose a simplistic embedding fusion workflow that aims to capture the overlapping information of image/text pairs, ultimately combining the semantics of a post into a joint embedding. After storing such fused embeddings in a vector database, we experiment with dimensionality reduction and provide empirical evidence to convey the semantic quality of the joint embeddings by clustering and examining the posts nearest to each cluster centroid. Additionally, our initial findings with ImageBind's emergent zero-shot cross-modal retrieval suggest that pure audio embeddings can correlate with semantically similar marketplace listings, indicating potential avenues for future research.