BOP-Distrib: Revisiting 6D Pose Estimation Benchmarks for Better Evaluation under Visual Ambiguities
作者: Boris Meden, Asma Brazi, Fabrice Mayran de Chamisso, Steve Bourgeois, Vincent Lepetit
分类: cs.CV
发布日期: 2024-08-30 (更新: 2026-01-08)
💡 一句话要点
BOP-Distrib:重新审视6D位姿估计基准,提升视觉歧义下的评估质量
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 6D位姿估计 视觉歧义 基准数据集 物体识别 位姿分布 图像理解
📋 核心要点
- 现有6D位姿估计基准数据集在处理视觉歧义时,仅考虑全局物体对称性,忽略了视角相关的图像级歧义。
- 论文提出一种自动重标注方法,生成图像特定的6D位姿分布ground truth,考虑物体表面可见性以准确确定视觉歧义。
- 通过新的ground truth,重新评估了现有单一位姿估计方法,并为位姿分布估计方法设计了精确率/召回率评估指标。
📝 摘要(中文)
6D位姿估计旨在确定最能解释相机观测结果的物体位姿。对于非歧义性物体,解是唯一的;但对于对称物体或对称性破坏元素被遮挡时,根据视角,解会变成多模态位姿分布。目前,6D位姿估计方法在数据集上进行基准测试时,其ground truth标注仅将视觉歧义视为与全局物体对称性相关,而实际上应该针对每个图像进行定义,以考虑相机视角。因此,我们首先提出一种自动方法,使用特定于每个图像的6D位姿分布重新标注这些数据集,同时考虑图像中的物体表面可见性,以正确确定视觉歧义。其次,基于改进后的ground truth,我们重新评估了最先进的单一位姿方法,结果表明这极大地改变了这些方法的排名。第三,由于一些最新的工作侧重于估计完整的解集,我们推导出一个精确率/召回率公式,以针对我们的图像级分布ground truth评估它们,使其成为真实图像上位姿分布方法的首个基准。
🔬 方法详解
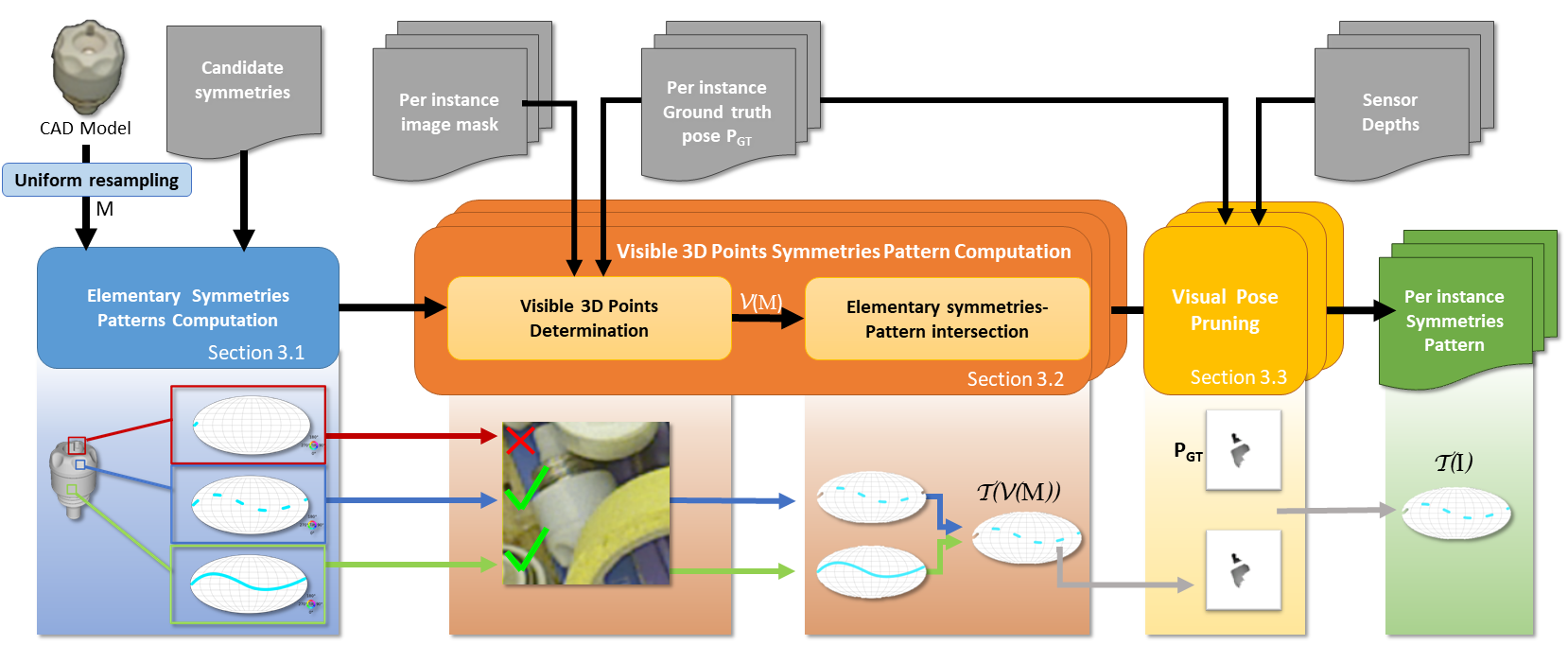
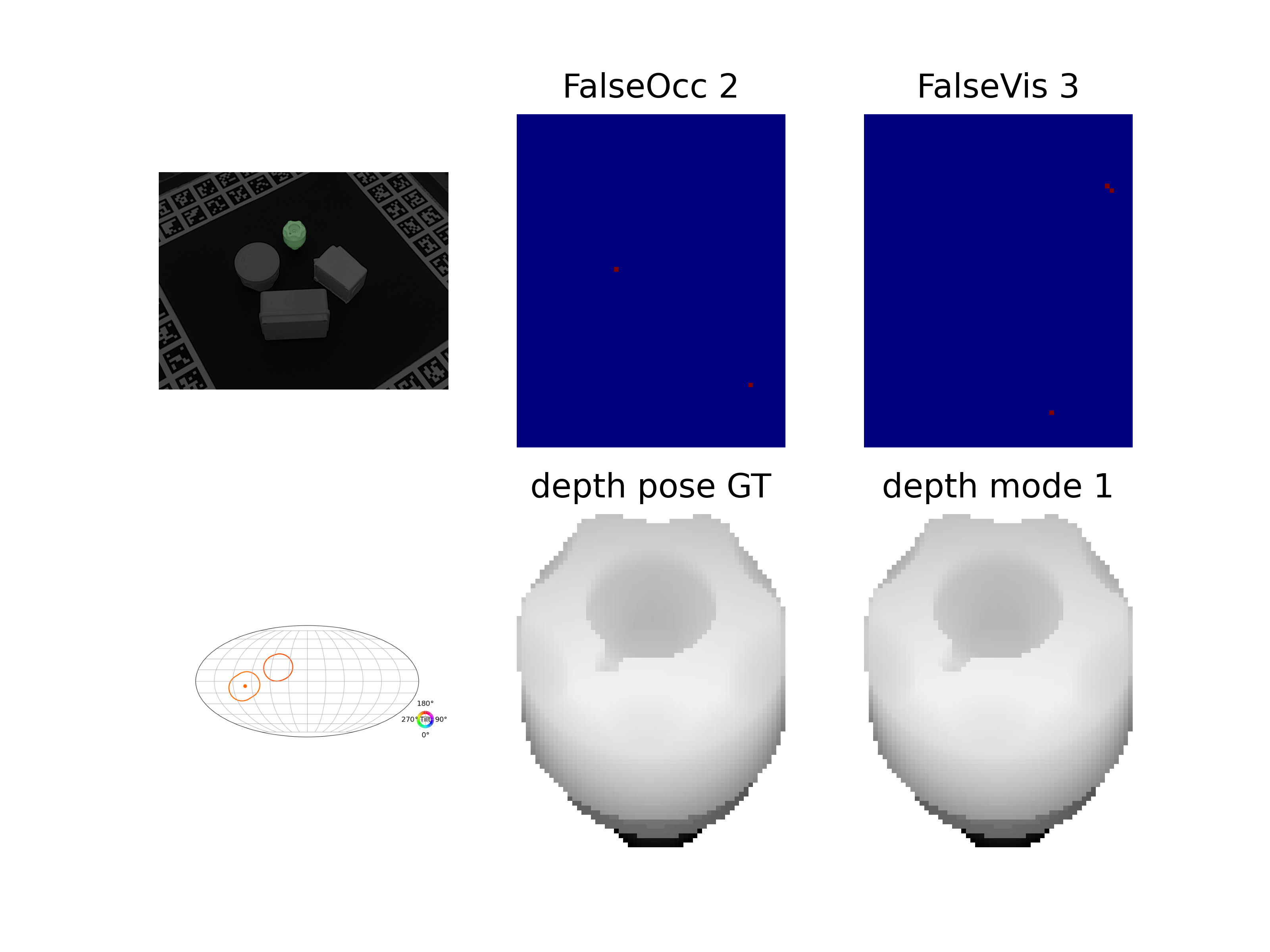
问题定义:现有6D位姿估计的benchmark在标注ground truth时,对于对称物体或者存在遮挡的物体,仅仅考虑了全局的对称性,而忽略了视角带来的图像级别的歧义性。例如,一个完全对称的物体,从某个角度看过去可能只有一种可能的位姿,而从另一个角度看过去可能有多种可能的位姿。现有方法没有区分这些情况,导致评估结果不准确。
核心思路:论文的核心思路是针对每个图像,自动生成一个6D位姿的分布,作为新的ground truth。这个分布考虑了物体表面的可见性,从而能够更准确地反映图像中存在的视觉歧义。这样,在评估6D位姿估计方法时,就可以更公平地比较不同方法在处理视觉歧义方面的能力。
技术框架:论文提出的方法主要包含以下几个阶段:1) 使用现有的3D模型和图像,计算物体表面的可见性;2) 根据物体表面的可见性,确定图像中存在的视觉歧义;3) 生成一个6D位姿的分布,作为新的ground truth;4) 使用新的ground truth,重新评估现有的6D位姿估计方法。对于位姿分布估计方法,论文提出了基于Precision/Recall的评估指标。
关键创新:论文的关键创新在于提出了一个自动生成图像特定6D位姿分布ground truth的方法。这个方法考虑了物体表面的可见性,从而能够更准确地反映图像中存在的视觉歧义。此外,论文还提出了一个针对位姿分布估计方法的评估指标。与现有方法相比,该方法能够更公平地评估不同方法在处理视觉歧义方面的能力。
关键设计:论文使用渲染技术来计算物体表面的可见性。具体来说,对于每个图像,论文首先将3D模型渲染到图像中,然后计算每个像素的深度值。通过比较渲染的深度值和真实的深度值,可以确定物体表面的可见性。论文使用一种基于采样的算法来生成6D位姿的分布。具体来说,论文首先随机采样一些位姿,然后根据物体表面的可见性,对这些位姿进行加权。权重越高,表示该位姿越有可能。最后,论文将这些加权的位姿作为6D位姿的分布。
🖼️ 关键图片

📊 实验亮点
论文通过实验证明,使用新的ground truth重新评估现有单一位姿估计方法,显著改变了方法的排名,表明了现有基准的不足。此外,论文提出的针对位姿分布估计方法的评估指标,为该领域的研究提供了新的工具。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于机器人抓取、增强现实、自动驾驶等领域。通过更准确的6D位姿估计,机器人可以更可靠地抓取物体,AR系统可以更精确地叠加虚拟物体,自动驾驶系统可以更准确地感知周围环境。未来,该研究可以推动6D位姿估计技术在实际场景中的应用。
📄 摘要(原文)
6D pose estimation aims at determining the object pose that best explains the camera observation. The unique solution for non-ambiguous objects can turn into a multi-modal pose distribution for symmetrical objects or when occlusions of symmetry-breaking elements happen, depending on the viewpoint. Currently, 6D pose estimation methods are benchmarked on datasets that consider, for their ground truth annotations, visual ambiguities as only related to global object symmetries, whereas they should be defined per-image to account for the camera viewpoint. We thus first propose an automatic method to re-annotate those datasets with a 6D pose distribution specific to each image, taking into account the object surface visibility in the image to correctly determine the visual ambiguities. Second, given this improved ground truth, we re-evaluate the state-of-the-art single pose methods and show that this greatly modifies the ranking of these methods. Third, as some recent works focus on estimating the complete set of solutions, we derive a precision/recall formulation to evaluate them against our image-wise distribution ground truth, making it the first benchmark for pose distribution methods on real images.