ConDense: Consistent 2D/3D Pre-training for Dense and Sparse Features from Multi-View Images
作者: Xiaoshuai Zhang, Zhicheng Wang, Howard Zhou, Soham Ghosh, Danushen Gnanapragasam, Varun Jampani, Hao Su, Leonidas Guibas
分类: cs.CV
发布日期: 2024-08-30
备注: ECCV 2024
💡 一句话要点
提出ConDense框架以解决3D基础模型训练中的特征一致性问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D基础模型 特征一致性 多视角图像 联合训练 稀疏特征 体积渲染 深度学习
📋 核心要点
- 现有的3D基础模型训练方法在特征一致性和噪声控制方面存在不足,影响了模型的性能。
- 本文提出的ConDense框架通过2D-3D联合训练方案,利用多视角图像提取一致的2D和3D特征。
- 实验结果表明,ConDense在3D分类和分割任务中显著优于其他预训练方法,且支持多种下游任务。
📝 摘要(中文)
为推动3D基础模型的创建,本文提出了ConDense框架,利用现有的预训练2D网络和大规模多视角数据集进行3D预训练。我们提出了一种新颖的2D-3D联合训练方案,通过类似NeRF的体积渲染过程强制2D和3D特征的一致性。使用密集的每像素特征,我们能够直接将2D模型的学习先验提炼到3D模型中,创建有用的3D骨干网络,并提取更一致且噪声更少的2D特征。此外,ConDense还可以提取稀疏特征(如关键点),并保持2D-3D一致性。我们的预训练模型在多种3D任务中表现出色,显著超越其他3D预训练方法。
🔬 方法详解
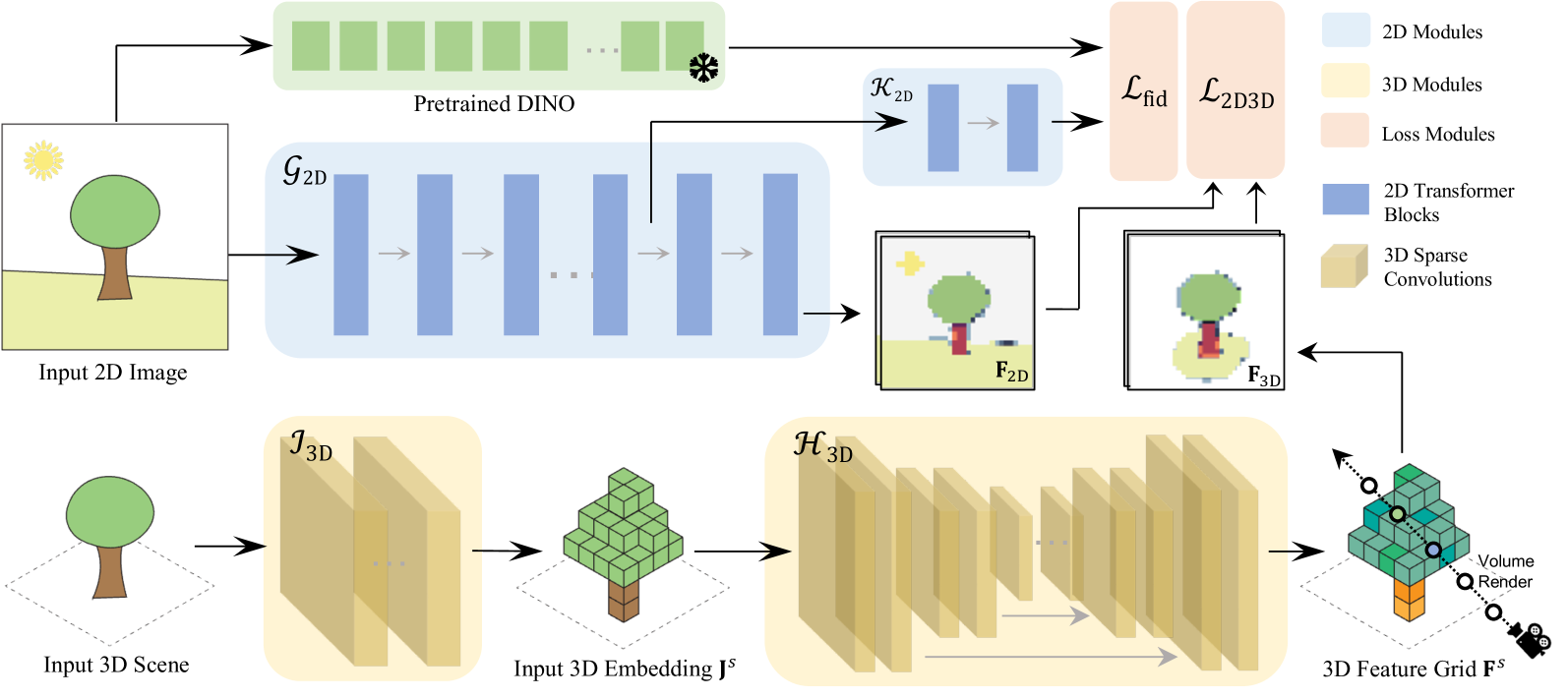
问题定义:本文旨在解决3D基础模型训练中2D和3D特征一致性不足的问题。现有方法往往无法有效地将2D模型的知识迁移到3D模型中,导致性能下降。
核心思路:ConDense框架通过引入2D-3D联合训练方案,利用多视角图像数据集,强制2D和3D特征的一致性,从而提高模型的整体性能。
技术框架:整体架构包括数据预处理、特征提取、2D-3D一致性损失计算和模型训练等模块。通过体积渲染过程实现2D和3D特征的联合学习。
关键创新:最重要的创新在于提出了一种新的2D-3D联合训练方案,利用密集的每像素特征实现2D和3D特征的一致性,显著提升了模型的性能。
关键设计:在损失函数设计上,结合了2D-3D一致性损失和特征提取网络的优化,确保了模型在训练过程中的稳定性和有效性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,ConDense预训练模型在3D分类和分割任务中表现优异,相较于其他3D预训练方法,性能提升幅度达到显著的水平。此外,利用稀疏特征,ConDense还支持高效的2D与3D场景匹配等下游任务。
🎯 应用场景
该研究的潜在应用领域包括3D物体识别、场景重建和增强现实等。通过高效的特征提取和一致性训练,ConDense框架能够为多种3D任务提供强大的支持,推动相关技术的发展和应用。
📄 摘要(原文)
To advance the state of the art in the creation of 3D foundation models, this paper introduces the ConDense framework for 3D pre-training utilizing existing pre-trained 2D networks and large-scale multi-view datasets. We propose a novel 2D-3D joint training scheme to extract co-embedded 2D and 3D features in an end-to-end pipeline, where 2D-3D feature consistency is enforced through a volume rendering NeRF-like ray marching process. Using dense per pixel features we are able to 1) directly distill the learned priors from 2D models to 3D models and create useful 3D backbones, 2) extract more consistent and less noisy 2D features, 3) formulate a consistent embedding space where 2D, 3D, and other modalities of data (e.g., natural language prompts) can be jointly queried. Furthermore, besides dense features, ConDense can be trained to extract sparse features (e.g., key points), also with 2D-3D consistency -- condensing 3D NeRF representations into compact sets of decorated key points. We demonstrate that our pre-trained model provides good initialization for various 3D tasks including 3D classification and segmentation, outperforming other 3D pre-training methods by a significant margin. It also enables, by exploiting our sparse features, additional useful downstream tasks, such as matching 2D images to 3D scenes, detecting duplicate 3D scenes, and querying a repository of 3D scenes through natural language -- all quite efficiently and without any per-scene fine-tuning.