AdaptVision: Dynamic Input Scaling in MLLMs for Versatile Scene Understanding
作者: Yonghui Wang, Wengang Zhou, Hao Feng, Houqiang Li
分类: cs.CV
发布日期: 2024-08-30
🔗 代码/项目: GITHUB
💡 一句话要点
AdaptVision:MLLM中动态输入缩放,用于多功能场景理解
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 动态输入缩放 视觉token 场景理解 图像分割 视觉-语言任务 文档理解
📋 核心要点
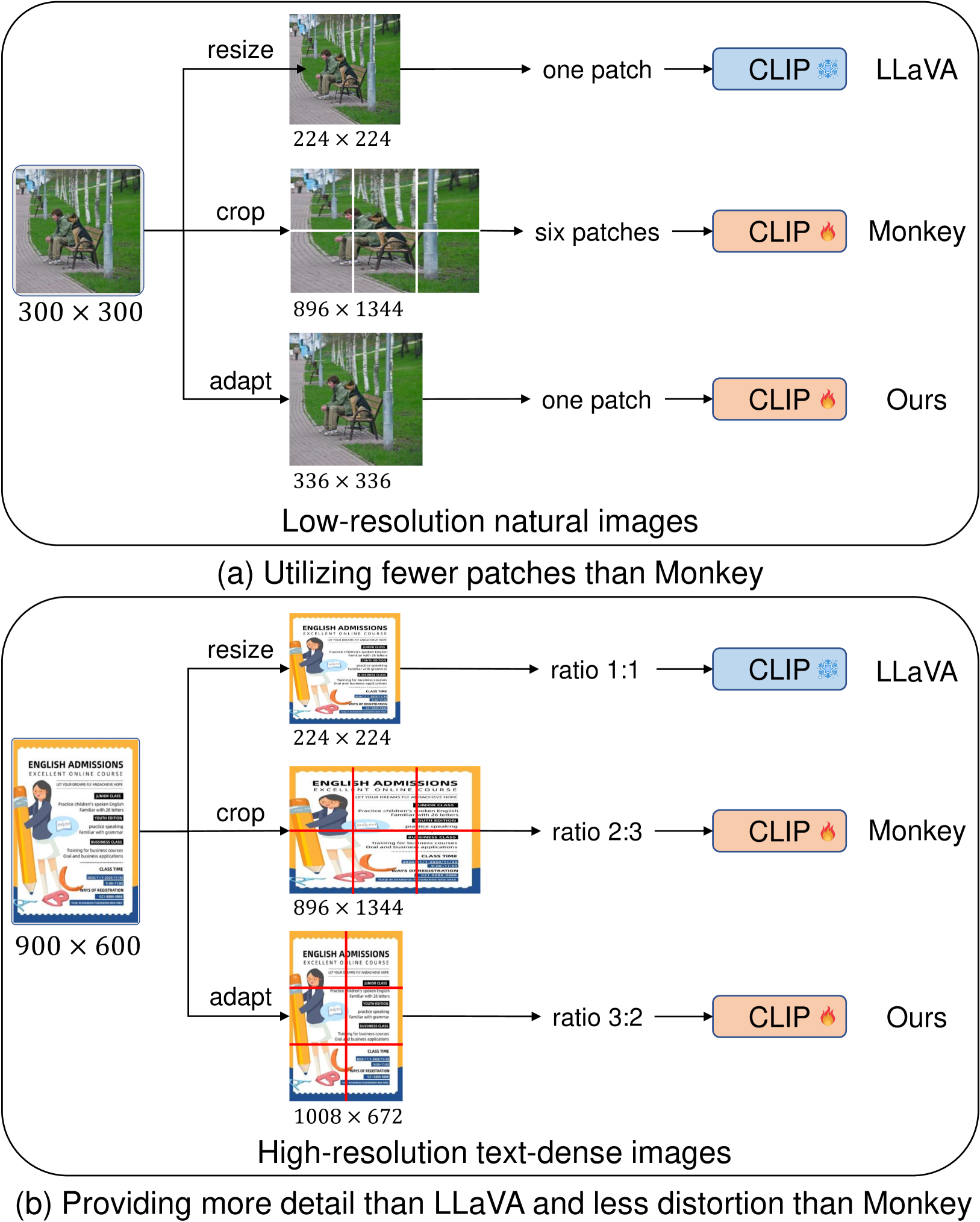
- 现有MLLM通常将图像缩放到固定分辨率,忽略了图像内容和分辨率对视觉token需求的影响。
- AdaptVision通过动态图像分割模块,根据图像内容和分辨率自适应地调整视觉token的数量,优化模型输入。
- 实验表明,AdaptVision在处理自然和文本相关场景中的视觉-语言任务时,性能显著提升,可处理高达1008x1008分辨率的图像。
📝 摘要(中文)
本文提出AdaptVision,一种多模态大型语言模型,专门设计用于动态处理不同分辨率的输入图像。核心思想是模型所需的视觉token数量取决于输入图像的分辨率和内容。信息密度较低的自然图像可以通过较少视觉token在较低分辨率下有效解释。而包含文本内容的图像,例如富文本的文档,需要更多的视觉token才能准确解释文本。基于此,我们设计了一个动态图像分割模块,根据图像的大小和宽高比调整视觉token的数量。该方法减轻了将图像调整为统一分辨率时产生的失真效应,并动态优化输入到LLM的视觉token。我们的模型能够处理高达1008x1008分辨率的图像。在各种数据集上的大量实验表明,我们的方法在处理自然和文本相关场景中的视觉-语言任务方面取得了令人印象深刻的性能。
🔬 方法详解
问题定义:现有MLLM在处理视觉信息时,通常会将输入图像缩放到统一的固定分辨率,然后进行token化。这种做法忽略了不同图像的内容差异以及分辨率对信息密度的影响。对于信息密度低的图像,高分辨率可能引入冗余信息;而对于包含大量文本的图像,低分辨率则可能导致信息丢失。因此,如何根据图像内容和分辨率动态调整视觉token的数量,是当前MLLM面临的一个挑战。
核心思路:AdaptVision的核心思路是根据输入图像的内容和分辨率,动态地调整输入到MLLM的视觉token数量。对于信息密度较低的图像,使用较少的视觉token和较低的分辨率;对于信息密度较高的图像(例如包含大量文本的文档),则使用较多的视觉token和较高的分辨率。这样可以避免信息冗余或丢失,提高模型的效率和准确性。
技术框架:AdaptVision主要包含一个动态图像分割模块。该模块首先分析输入图像的大小和宽高比,然后根据图像的内容(例如是否包含文本)自适应地调整图像分割的策略。具体来说,该模块会确定需要将图像分割成多少个patch,以及每个patch的大小。分割后的图像patch会被转换成视觉token,然后输入到LLM中进行处理。整个流程旨在优化输入LLM的视觉token数量,从而提升模型性能。
关键创新:AdaptVision的关键创新在于提出了动态图像分割模块,该模块能够根据图像的内容和分辨率自适应地调整视觉token的数量。与传统的固定分辨率输入方法相比,AdaptVision能够更好地适应不同类型的图像,从而提高模型的泛化能力和效率。这种动态调整视觉token数量的策略是AdaptVision与现有方法的本质区别。
关键设计:动态图像分割模块的设计是AdaptVision的关键。该模块需要能够准确地评估图像的信息密度,并根据评估结果调整分割策略。具体的实现细节可能包括使用预训练的文本检测模型来判断图像中是否包含文本,并根据文本的数量和大小来调整分割的粒度。此外,损失函数的设计也至关重要,需要平衡模型在不同分辨率下的性能表现。
🖼️ 关键图片


📊 实验亮点
AdaptVision在多个数据集上进行了广泛的实验,结果表明其在处理自然和文本相关场景中的视觉-语言任务方面取得了显著的性能提升。具体而言,AdaptVision能够处理高达1008x1008分辨率的图像,并且在文档理解任务上表现出色,证明了其动态调整视觉token数量策略的有效性。实验结果表明,AdaptVision优于现有的固定分辨率输入方法。
🎯 应用场景
AdaptVision在多模态场景理解方面具有广泛的应用前景,例如文档理解、图像检索、视觉问答等。该模型可以应用于智能客服、自动化报告生成、以及辅助医学图像诊断等领域。通过动态调整视觉token的数量,AdaptVision能够更有效地处理各种类型的图像,提高相关应用的性能和用户体验。未来,该技术有望进一步推动多模态人工智能的发展。
📄 摘要(原文)
Over the past few years, the advancement of Multimodal Large Language Models (MLLMs) has captured the wide interest of researchers, leading to numerous innovations to enhance MLLMs' comprehension. In this paper, we present AdaptVision, a multimodal large language model specifically designed to dynamically process input images at varying resolutions. We hypothesize that the requisite number of visual tokens for the model is contingent upon both the resolution and content of the input image. Generally, natural images with a lower information density can be effectively interpreted by the model using fewer visual tokens at reduced resolutions. In contrast, images containing textual content, such as documents with rich text, necessitate a higher number of visual tokens for accurate text interpretation due to their higher information density. Building on this insight, we devise a dynamic image partitioning module that adjusts the number of visual tokens according to the size and aspect ratio of images. This method mitigates distortion effects that arise from resizing images to a uniform resolution and dynamically optimizing the visual tokens input to the LLMs. Our model is capable of processing images with resolutions up to $1008\times 1008$. Extensive experiments across various datasets demonstrate that our method achieves impressive performance in handling vision-language tasks in both natural and text-related scenes. The source code and dataset are now publicly available at \url{https://github.com/harrytea/AdaptVision}.