VideoLLM-MoD: Efficient Video-Language Streaming with Mixture-of-Depths Vision Computation
作者: Shiwei Wu, Joya Chen, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, Mike Zheng Shou
分类: cs.CV
发布日期: 2024-08-29
💡 一句话要点
VideoLLM-MoD:混合深度视觉计算的高效视频语言流处理
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视频语言模型 长视频理解 混合深度模型 视觉计算优化 Transformer 效率提升 流式视频处理
📋 核心要点
- 现有视觉语言模型在处理长视频时,增加视觉token虽提升理解力,但计算和内存成本剧增。
- VideoLLM-MoD通过学习跳过Transformer层中冗余视觉token的计算,降低计算负担。
- 实验表明,该方法在多个视频理解任务上实现了显著的效率提升,同时保持或提升了性能。
📝 摘要(中文)
大型视觉语言模型(如GPT-4、LLaVA)面临一个难题:增加视觉token的数量通常能提升视觉理解能力,但也会显著增加内存和计算成本,尤其是在长期、密集的视频帧流处理场景中。虽然已经开发了像Q-Former和Perceiver Resampler这样的可学习方法来减少视觉token的负担,但它们忽略了LLM因果建模的上下文(即键值缓存),可能导致在处理用户查询时错过视觉线索。本文提出了一种新方法,通过“跳过层”而非减少视觉token的数量来降低视觉计算量。我们的方法VideoLLM-MoD,受到混合深度LLM的启发,解决了长期或流式视频中大量视觉token带来的挑战。具体来说,对于每个transformer层,我们学习跳过大部分(例如80%)视觉token的计算,直接将它们传递到下一层。这种方法显著提高了模型效率,使整个训练过程的时间节省约42%,内存节省约30%。此外,我们的方法减少了上下文中的计算,避免了减少视觉token,从而保持甚至提高了性能。我们进行了广泛的实验,证明了VideoLLM-MoD的有效性,展示了其在COIN、Ego4D和Ego-Exo4D数据集中的叙述、预测和总结任务上的最先进结果。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型在处理长视频或视频流时,由于视觉token数量过多而导致的计算和内存开销过大的问题。现有方法,如Q-Former和Perceiver Resampler,虽然减少了视觉token的数量,但可能会丢失重要的视觉信息,影响模型性能。
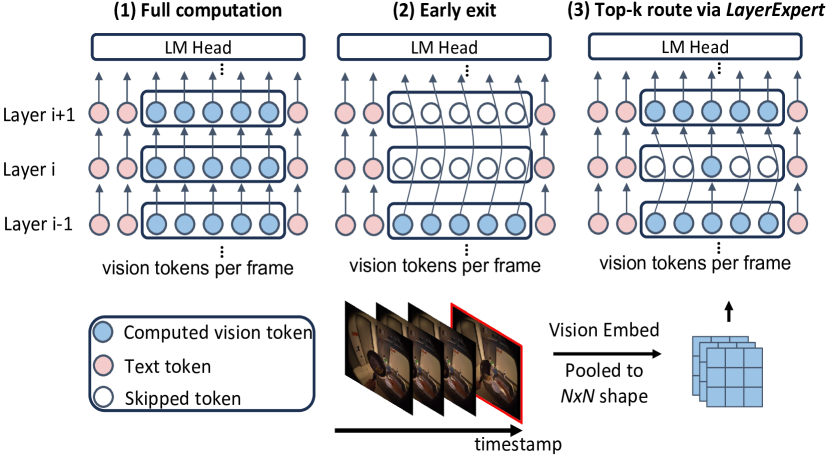
核心思路:论文的核心思路是借鉴混合深度模型(Mixture-of-Depths)的思想,让模型学习在Transformer的不同层中跳过一部分视觉token的计算,而不是直接减少视觉token的数量。这样可以在减少计算量的同时,保留尽可能多的视觉信息。
技术框架:VideoLLM-MoD的整体框架基于现有的视觉语言模型,例如LLaVA。其主要改进在于Transformer层中引入了一个可学习的“跳过”机制。对于每个视觉token,模型会学习一个概率,决定是否跳过当前层的计算,直接传递到下一层。
关键创新:该方法最重要的创新点在于,它不是简单地减少视觉token的数量,而是通过学习跳过冗余的计算,从而在减少计算量的同时,尽可能地保留了视觉信息。这种方法避免了现有方法可能导致的视觉信息丢失问题。
关键设计:对于每个Transformer层,模型学习一个二元掩码(binary mask),用于指示哪些视觉token需要跳过计算。这个掩码是通过一个可学习的神经网络生成的,该网络的输入是视觉token的特征。损失函数包括一个标准交叉熵损失,用于训练视觉语言模型,以及一个正则化项,用于鼓励模型跳过更多的视觉token,从而降低计算量。跳过的比例(例如80%)是一个超参数,需要根据具体任务进行调整。
🖼️ 关键图片
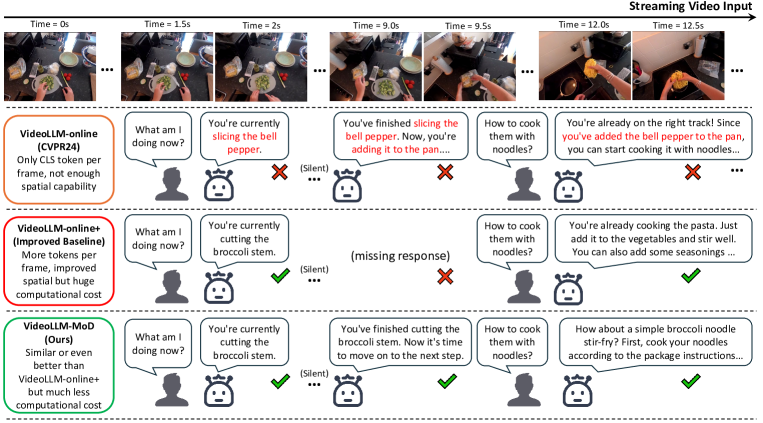
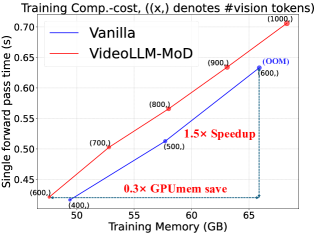
📊 实验亮点
实验结果表明,VideoLLM-MoD在COIN、Ego4D和Ego-Exo4D等数据集上的叙述、预测和总结任务中取得了最先进的结果。与原始模型相比,该方法在训练过程中节省了约42%的时间和30%的内存,同时保持甚至提高了性能。这些结果证明了VideoLLM-MoD在提高视觉语言模型效率方面的有效性。
🎯 应用场景
该研究成果可广泛应用于需要处理长视频或视频流的场景,例如视频监控、自动驾驶、机器人导航、视频会议、在线教育等。通过降低视觉计算量,可以使这些应用在资源受限的设备上运行,或者处理更大规模的视频数据,从而提高效率和降低成本。未来,该方法还可以与其他模型压缩技术相结合,进一步提升视觉语言模型的性能。
📄 摘要(原文)
A well-known dilemma in large vision-language models (e.g., GPT-4, LLaVA) is that while increasing the number of vision tokens generally enhances visual understanding, it also significantly raises memory and computational costs, especially in long-term, dense video frame streaming scenarios. Although learnable approaches like Q-Former and Perceiver Resampler have been developed to reduce the vision token burden, they overlook the context causally modeled by LLMs (i.e., key-value cache), potentially leading to missed visual cues when addressing user queries. In this paper, we introduce a novel approach to reduce vision compute by leveraging redundant vision tokens "skipping layers" rather than decreasing the number of vision tokens. Our method, VideoLLM-MoD, is inspired by mixture-of-depths LLMs and addresses the challenge of numerous vision tokens in long-term or streaming video. Specifically, for each transformer layer, we learn to skip the computation for a high proportion (e.g., 80\%) of vision tokens, passing them directly to the next layer. This approach significantly enhances model efficiency, achieving approximately \textasciitilde42\% time and \textasciitilde30\% memory savings for the entire training. Moreover, our method reduces the computation in the context and avoid decreasing the vision tokens, thus preserving or even improving performance compared to the vanilla model. We conduct extensive experiments to demonstrate the effectiveness of VideoLLM-MoD, showing its state-of-the-art results on multiple benchmarks, including narration, forecasting, and summarization tasks in COIN, Ego4D, and Ego-Exo4D datasets.