COIN: Control-Inpainting Diffusion Prior for Human and Camera Motion Estimation
作者: Jiefeng Li, Ye Yuan, Davis Rempe, Haotian Zhang, Pavlo Molchanov, Cewu Lu, Jan Kautz, Umar Iqbal
分类: cs.CV, cs.AI
发布日期: 2024-08-29
备注: ECCV 2024
💡 一句话要点
COIN:用于人和相机运动估计的可控Inpainting扩散先验
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 人体运动估计 相机运动估计 扩散模型 Inpainting 运动先验 分数蒸馏采样 人-场景关系
📋 核心要点
- 从移动相机估计全局人体运动极具挑战,因为人和相机的运动相互纠缠,难以解耦。
- COIN提出一种可控Inpainting运动扩散先验,通过控制-Inpainting分数蒸馏采样方法,实现人和相机运动的精细控制和解耦。
- 实验表明,COIN在全局人体运动和相机运动估计方面显著优于现有方法,例如在RICH数据集上W-MPJPE降低了33%。
📝 摘要(中文)
本文提出COIN,一种可控Inpainting运动扩散先验,旨在解决从移动相机估计全局人体运动的难题。现有方法依赖学习的人体运动先验,但常导致过度平滑的运动和未对齐的2D投影。COIN引入了一种新颖的控制-Inpainting分数蒸馏采样方法,以确保在联合优化框架内,从扩散先验中获得对齐良好、一致且高质量的运动。此外,本文还提出了一种新的人-场景关系损失,通过强制人类、相机和场景之间的一致性来缓解尺度模糊性。在三个具有挑战性的基准测试上的实验表明,COIN在全局人体运动估计和相机运动估计方面优于现有技术水平的方法。例如,在RICH数据集上,COIN在世界关节位置误差(W-MPJPE)方面优于现有技术水平的方法33%。
🔬 方法详解
问题定义:论文旨在解决从移动相机视频中准确估计全局人体运动和相机运动的问题。现有方法依赖学习的运动先验,但容易产生过度平滑的运动,并且2D投影与图像不一致。此外,人和相机运动的尺度模糊性也是一个挑战。
核心思路:论文的核心思路是利用预训练的运动扩散模型作为运动先验,并通过可控的Inpainting过程来引导运动估计。通过控制Inpainting过程,可以更好地解耦人和相机的运动,并生成更真实、更符合图像信息的运动。同时,引入人-场景关系损失来约束尺度,解决尺度模糊性问题。
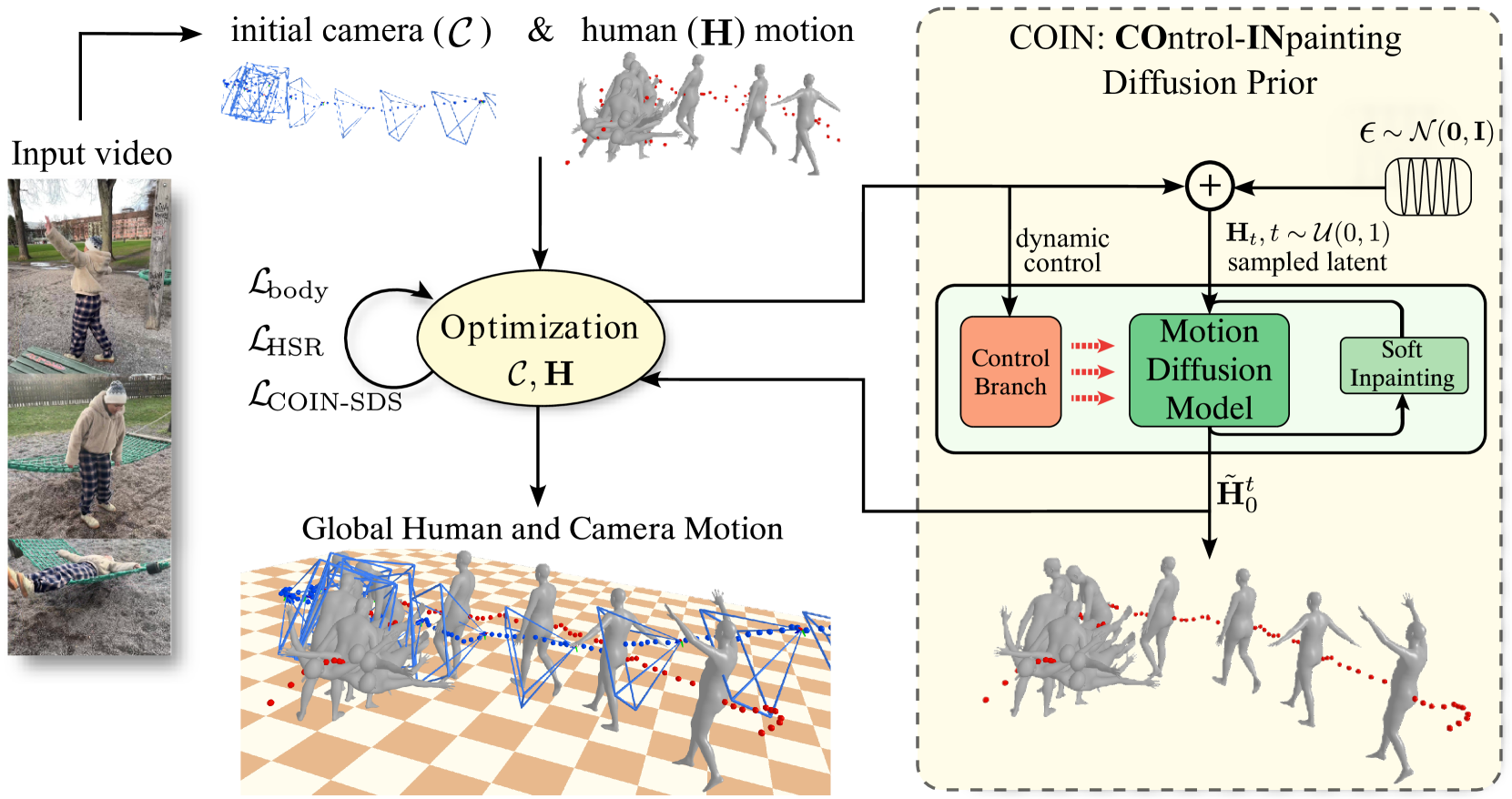
技术框架:COIN的整体框架是一个联合优化框架,包括以下几个主要模块:1) 运动扩散模型:使用预训练的运动扩散模型作为运动先验。2) 控制-Inpainting模块:通过控制Inpainting过程,引导扩散模型生成符合图像信息的运动。3) 优化模块:联合优化人体运动、相机运动和场景信息,并使用多种损失函数进行约束,包括2D投影损失、运动平滑损失和人-场景关系损失。
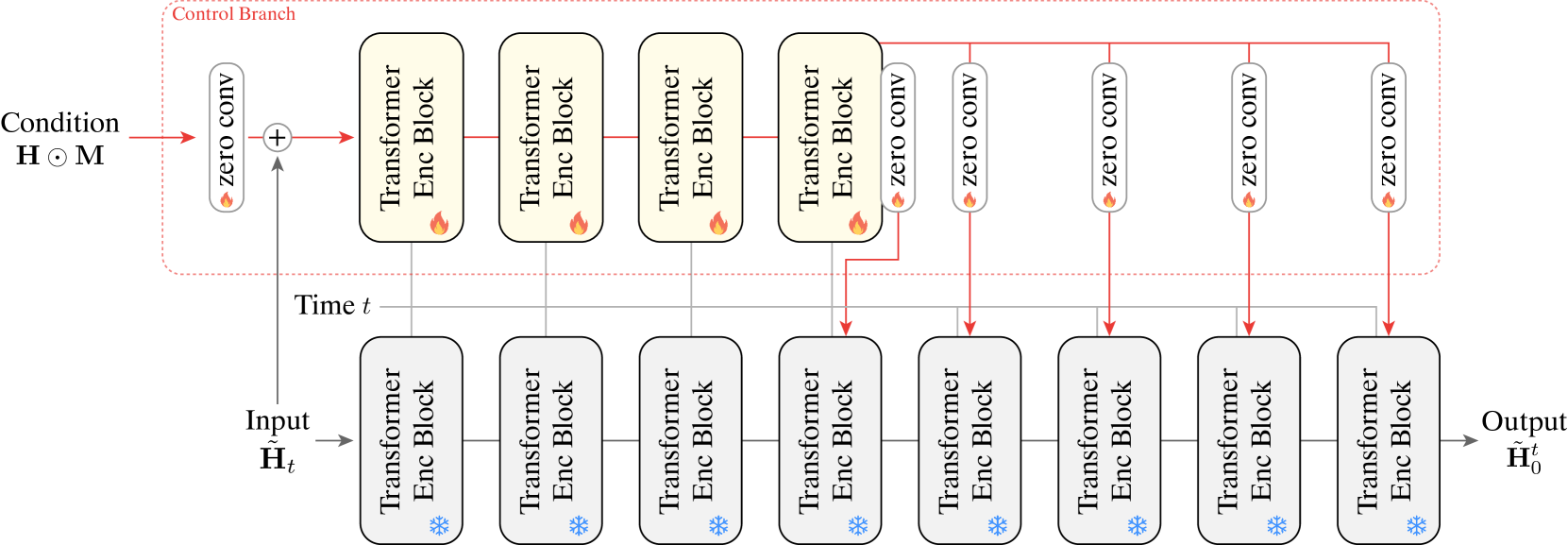
关键创新:论文的关键创新在于提出了控制-Inpainting分数蒸馏采样方法。该方法允许在扩散模型的采样过程中,通过控制信号(例如2D关键点投影)来引导运动生成,从而实现对人和相机运动的精细控制。与现有方法相比,COIN能够更好地利用运动先验,并生成更真实、更符合图像信息的运动。
关键设计:控制-Inpainting模块的关键设计在于如何将控制信号融入到扩散模型的采样过程中。论文采用分数蒸馏采样方法,通过计算控制信号对运动的影响,并将其作为梯度信息注入到扩散模型的采样过程中。人-场景关系损失的关键设计在于如何定义人和场景之间的关系。论文通过约束人体和场景之间的距离和方向关系,来缓解尺度模糊性。
🖼️ 关键图片

📊 实验亮点
COIN在三个具有挑战性的基准测试上取得了显著的性能提升。在RICH数据集上,COIN在世界关节位置误差(W-MPJPE)方面优于现有技术水平的方法33%。在Human3.6M数据集上,COIN也取得了与现有方法相当或更好的性能。这些实验结果表明,COIN能够有效地利用运动先验,并生成更真实、更符合图像信息的运动。
🎯 应用场景
COIN的研究成果可应用于虚拟现实、增强现实、人机交互、运动分析、自动驾驶等领域。例如,在虚拟现实中,可以利用COIN生成更真实的人体运动,提高用户体验。在运动分析中,可以利用COIN准确估计运动员的运动轨迹,为训练提供指导。在自动驾驶中,可以利用COIN预测行人的运动轨迹,提高安全性。
📄 摘要(原文)
Estimating global human motion from moving cameras is challenging due to the entanglement of human and camera motions. To mitigate the ambiguity, existing methods leverage learned human motion priors, which however often result in oversmoothed motions with misaligned 2D projections. To tackle this problem, we propose COIN, a control-inpainting motion diffusion prior that enables fine-grained control to disentangle human and camera motions. Although pre-trained motion diffusion models encode rich motion priors, we find it non-trivial to leverage such knowledge to guide global motion estimation from RGB videos. COIN introduces a novel control-inpainting score distillation sampling method to ensure well-aligned, consistent, and high-quality motion from the diffusion prior within a joint optimization framework. Furthermore, we introduce a new human-scene relation loss to alleviate the scale ambiguity by enforcing consistency among the humans, camera, and scene. Experiments on three challenging benchmarks demonstrate the effectiveness of COIN, which outperforms the state-of-the-art methods in terms of global human motion estimation and camera motion estimation. As an illustrative example, COIN outperforms the state-of-the-art method by 33% in world joint position error (W-MPJPE) on the RICH dataset.