Law of Vision Representation in MLLMs
作者: Shijia Yang, Bohan Zhai, Quanzeng You, Jianbo Yuan, Hongxia Yang, Chenfeng Xu
分类: cs.CV
发布日期: 2024-08-29 (更新: 2025-10-06)
备注: The code is available at https://github.com/bronyayang/Law_of_Vision_Representation_in_MLLMs
💡 一句话要点
提出多模态大语言模型(MLLM)的视觉表征定律,通过AC score优化视觉表征。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉表征 跨模态对齐 AC score 模型优化
📋 核心要点
- 现有MLLM训练中,视觉表征的选择和优化缺乏有效指导,需要大量计算资源进行语言模型的微调。
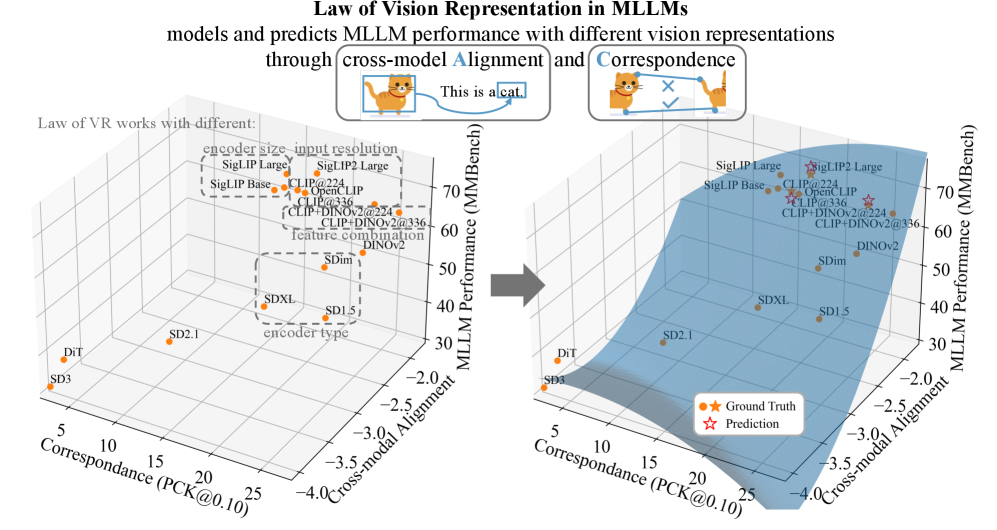
- 论文提出“视觉表征定律”,通过AC score量化跨模态对齐和视觉表征对应关系,并预测MLLM性能。
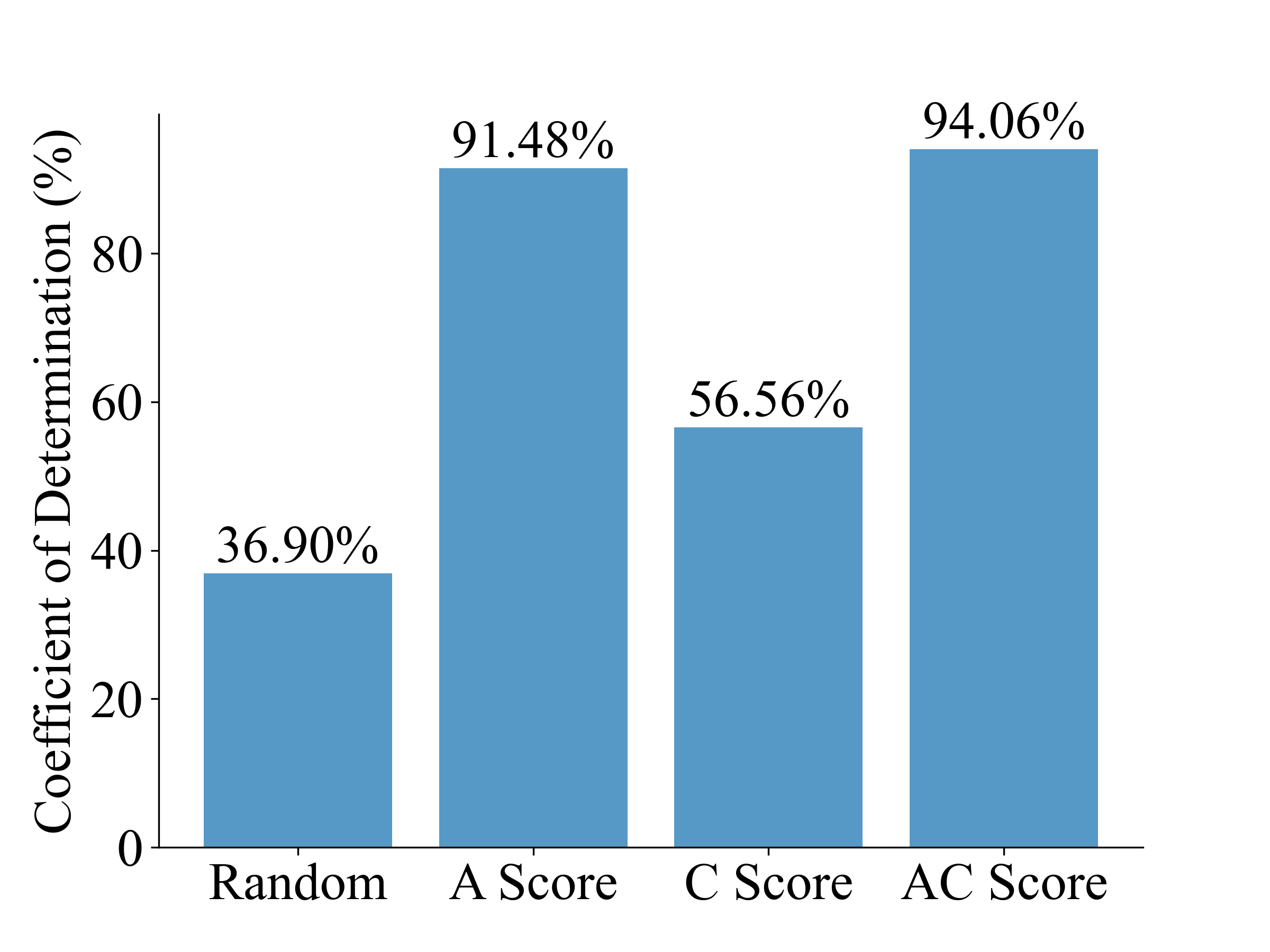
- 实验表明AC score与模型性能线性相关,可用于高效选择和训练最优视觉表征,显著降低计算成本。
📝 摘要(中文)
本文提出了多模态大语言模型(MLLM)中的“视觉表征定律”。该定律揭示了跨模态对齐、视觉表征对应关系以及MLLM性能之间的强相关性。我们使用跨模态对齐和对应关系得分(AC score)来量化这两个因素。通过涉及13种不同视觉表征设置和8个基准评估的广泛实验,我们发现AC score与模型性能呈线性相关。通过利用这种关系,我们能够仅识别和训练最佳视觉表征,而无需每次都对语言模型进行微调,从而将计算成本降低99.7%。
🔬 方法详解
问题定义:现有MLLM在选择合适的视觉表征时面临挑战。每次更换视觉表征都需要对整个语言模型进行微调,计算成本高昂。缺乏一种有效的方法来评估不同视觉表征的优劣,并指导视觉表征的优化。
核心思路:论文的核心思路是发现并利用跨模态对齐、视觉表征对应关系与MLLM性能之间的内在联系。通过量化这种联系,可以仅通过评估视觉表征的质量来预测MLLM的性能,从而避免对语言模型进行昂贵的微调。
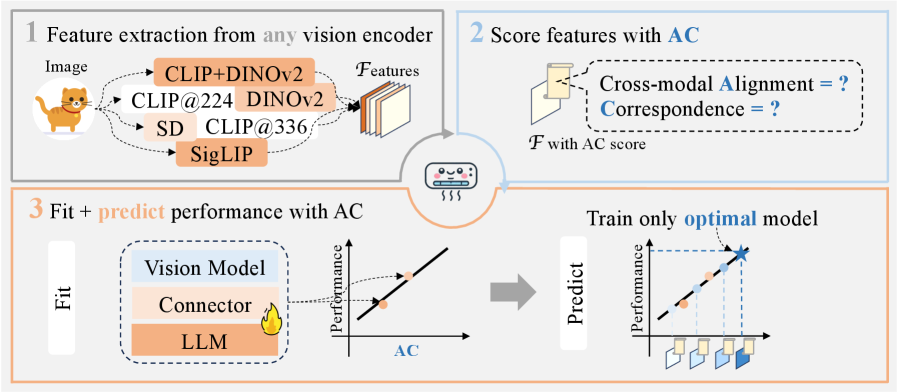
技术框架:论文提出了一个基于AC score的视觉表征评估框架。该框架首先提取视觉表征,然后计算其与语言模型的对齐程度和对应关系,得到AC score。最后,利用AC score预测MLLM的性能。整个流程无需对语言模型进行微调。
关键创新:最重要的技术创新点在于发现了“视觉表征定律”,即AC score与MLLM性能之间存在线性相关关系。这一发现使得可以在不微调语言模型的情况下,通过AC score来选择和优化视觉表征。与现有方法需要对整个模型进行微调相比,该方法大大降低了计算成本。
关键设计:AC score的计算是关键。具体来说,需要定义合适的指标来衡量跨模态对齐和视觉表征对应关系。论文中使用了具体的计算方法,但具体细节未知。此外,线性关系的拟合和验证也需要仔细设计实验。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AC score与MLLM性能之间存在显著的线性相关性。通过利用这种关系,可以在不微调语言模型的情况下,选择和训练最优视觉表征,从而将计算成本降低99.7%。在多个基准测试中,使用AC score选择的视觉表征能够达到与微调语言模型相近甚至更好的性能。
🎯 应用场景
该研究成果可应用于各种多模态大语言模型,用于高效选择和优化视觉表征。这可以显著降低MLLM的训练成本,加速MLLM的开发和部署。此外,该研究也为理解MLLM的内部机制提供了新的视角,有助于未来设计更强大的多模态模型。
📄 摘要(原文)
We present the "Law of Vision Representation" in multimodal large language models (MLLMs). It reveals a strong correlation between the combination of cross-modal alignment, correspondence in vision representation, and MLLM performance. We quantify the two factors using the cross-modal Alignment and Correspondence score (AC score). Through extensive experiments involving thirteen different vision representation settings and evaluations across eight benchmarks, we find that the AC score is linearly correlated to model performance. By leveraging this relationship, we are able to identify and train the optimal vision representation only, which does not require finetuning the language model every time, resulting in a 99.7% reduction in computational cost.