EvLight++: Low-Light Video Enhancement with an Event Camera: A Large-Scale Real-World Dataset, Novel Method, and More
作者: Kanghao Chen, Guoqiang Liang, Hangyu Li, Yunfan Lu, Lin Wang
分类: cs.CV
发布日期: 2024-08-29
备注: Journal extension based on EvLight (arXiv:2404.00834)
💡 一句话要点
EvLight++:提出一种事件相机引导的低光视频增强方法,并构建大规模真实数据集。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低光视频增强 事件相机 多模态融合 信噪比引导 循环神经网络
📋 核心要点
- 现有低光视频增强研究受限于缺乏大规模、真实世界、时空对齐的事件-视频数据集。
- EvLight++利用事件相机高动态范围的优势,设计多尺度融合分支和SNR引导的特征选择,提升低光视频质量。
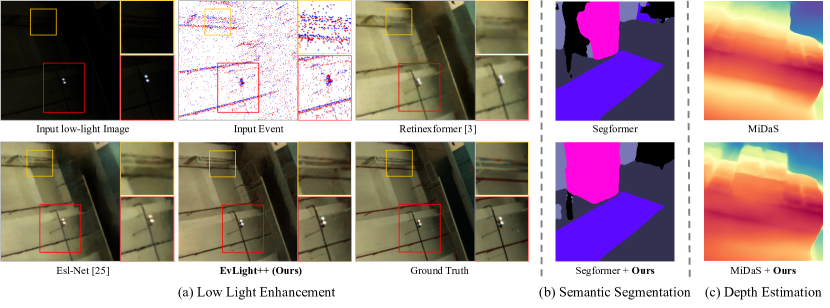
- 实验表明,EvLight++在低光视频增强任务上显著优于现有方法,并在语义分割等下游任务中取得显著提升。
📝 摘要(中文)
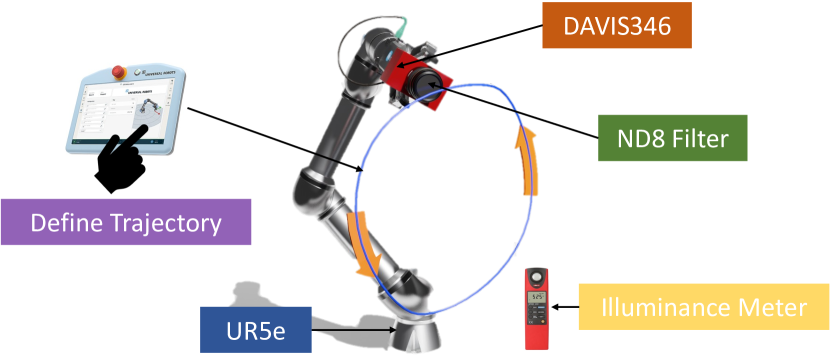
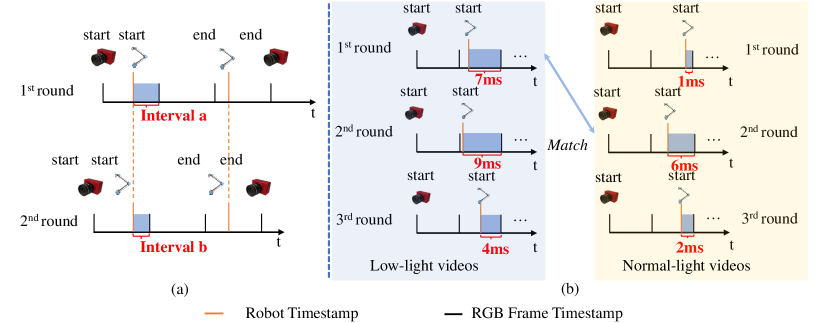
本文提出了一种基于事件相机的低光视频增强方法EvLight++,并构建了一个大规模真实世界数据集,该数据集包含超过30,000对在不同光照条件下捕获的帧和事件。该数据集通过机器人手臂以小于0.03mm的空间对齐精度和小于0.01s的时间对齐误差进行收集。EvLight++采用事件引导的低光视频增强方法,在真实场景中表现出鲁棒性。该方法设计了一个多尺度整体融合分支,用于整合图像和事件的结构和纹理信息。为了应对区域光照和噪声的变化,引入了信噪比(SNR)引导的区域特征选择,增强高SNR区域的特征,并通过从事件中提取结构信息来增强低SNR区域的特征。为了整合时间信息并确保时间一致性,进一步引入了循环模块和时间损失。在自建数据集和合成SDSD数据集上的实验表明,EvLight++显著优于单图像和视频方法,分别提高了1.37 dB和3.71 dB。通过使用基础模型进行细致的标注,扩展了数据集,添加了伪分割和深度标签,以探索其在语义分割和单目深度估计等下游任务中的潜力。在各种低光场景下的实验表明,增强后的结果在语义分割的mIoU方面提高了15.97%。
🔬 方法详解
问题定义:论文旨在解决低光照条件下视频质量差的问题。现有方法,如单图像增强和传统视频增强方法,在处理低光视频时,容易受到噪声和光照不均的影响,导致细节丢失和伪影。此外,缺乏大规模真实数据集也限制了相关算法的开发和评估。
核心思路:论文的核心思路是利用事件相机的高动态范围特性,结合图像信息,实现更鲁棒的低光视频增强。通过融合事件和图像的多尺度特征,并根据信噪比自适应地选择和增强特征,从而提高视频的亮度和清晰度。同时,引入时间信息以保证视频帧之间的时间一致性。
技术框架:EvLight++的整体框架包括以下几个主要模块:1) 多尺度整体融合分支:用于提取和融合图像和事件的多尺度特征。2) SNR引导的区域特征选择:根据信噪比自适应地选择和增强特征,抑制噪声。3) 循环模块:用于整合时间信息,保证视频帧之间的时间一致性。4) 时间损失:用于约束视频帧之间的时间一致性。整个流程首先对图像和事件数据进行预处理,然后通过多尺度融合分支提取特征,接着利用SNR引导的特征选择模块增强特征,最后通过循环模块和时间损失进行时间一致性约束,得到增强后的视频。
关键创新:论文的关键创新点在于:1) 构建了一个大规模真实世界的事件-视频数据集,为低光视频增强研究提供了数据基础。2) 提出了SNR引导的区域特征选择方法,能够自适应地增强高信噪比区域的特征,并利用事件信息增强低信噪比区域的特征。3) 将事件相机数据与传统视频增强方法相结合,充分利用了事件相机的高动态范围特性。
关键设计:在多尺度融合分支中,使用了卷积神经网络提取图像和事件的多尺度特征,并通过注意力机制进行融合。在SNR引导的特征选择模块中,使用信噪比作为权重,自适应地选择和增强特征。在循环模块中,使用了LSTM网络来整合时间信息。时间损失函数包括L1损失和感知损失,用于约束视频帧之间的时间一致性。数据集的空间对齐精度小于0.03mm,时间对齐误差小于0.01s(90%的数据)。
🖼️ 关键图片
📊 实验亮点
EvLight++在自建数据集和合成SDSD数据集上进行了广泛的实验,结果表明,该方法显著优于现有的单图像和视频增强方法,分别提高了1.37 dB和3.71 dB。此外,在语义分割任务中,使用EvLight++增强后的视频,mIoU指标提高了15.97%,表明该方法能够有效提高低光视频的质量,并改善下游任务的性能。
🎯 应用场景
EvLight++在安防监控、自动驾驶、医疗影像等领域具有广泛的应用前景。在低光照条件下,该方法可以显著提高视频的清晰度和可识别性,从而提升监控系统的性能和安全性。在自动驾驶领域,可以帮助车辆在夜间或弱光环境下更好地感知周围环境。在医疗影像领域,可以提高低剂量CT图像的质量,减少辐射剂量。
📄 摘要(原文)
Event cameras offer significant advantages for low-light video enhancement, primarily due to their high dynamic range. Current research, however, is severely limited by the absence of large-scale, real-world, and spatio-temporally aligned event-video datasets. To address this, we introduce a large-scale dataset with over 30,000 pairs of frames and events captured under varying illumination. This dataset was curated using a robotic arm that traces a consistent non-linear trajectory, achieving spatial alignment precision under 0.03mm and temporal alignment with errors under 0.01s for 90% of the dataset. Based on the dataset, we propose \textbf{EvLight++}, a novel event-guided low-light video enhancement approach designed for robust performance in real-world scenarios. Firstly, we design a multi-scale holistic fusion branch to integrate structural and textural information from both images and events. To counteract variations in regional illumination and noise, we introduce Signal-to-Noise Ratio (SNR)-guided regional feature selection, enhancing features from high SNR regions and augmenting those from low SNR regions by extracting structural information from events. To incorporate temporal information and ensure temporal coherence, we further introduce a recurrent module and temporal loss in the whole pipeline. Extensive experiments on our and the synthetic SDSD dataset demonstrate that EvLight++ significantly outperforms both single image- and video-based methods by 1.37 dB and 3.71 dB, respectively. To further explore its potential in downstream tasks like semantic segmentation and monocular depth estimation, we extend our datasets by adding pseudo segmentation and depth labels via meticulous annotation efforts with foundation models. Experiments under diverse low-light scenes show that the enhanced results achieve a 15.97% improvement in mIoU for semantic segmentation.