More Text, Less Point: Towards 3D Data-Efficient Point-Language Understanding
作者: Yuan Tang, Xu Han, Xianzhi Li, Qiao Yu, Jinfeng Xu, Yixue Hao, Long Hu, Min Chen
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-08-28 (更新: 2025-05-22)
🔗 代码/项目: GITHUB
💡 一句话要点
提出GreenPLM,利用更多文本数据提升3D数据稀缺场景下的点云-语言理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D点云理解 大型语言模型 多模态学习 数据高效学习 文本增强 模态对齐 零参数注意力
📋 核心要点
- 现有方法在3D场景理解中依赖大规模3D-文本数据集,数据稀缺限制了大型语言模型在该领域的应用。
- GreenPLM的核心思想是利用预训练点云-文本编码器将3D点云映射到文本空间,并扩展文本数据以弥补3D数据不足。
- 实验结果表明,GreenPLM仅使用少量3D数据即可超越现有方法,甚至仅使用文本数据也能达到竞争性性能。
📝 摘要(中文)
本文提出了一种新的任务:3D数据高效的点云-语言理解。该任务旨在使大型语言模型(LLM)能够以最少的3D点云和文本数据对实现强大的3D对象理解。为了解决这个问题,我们引入了GreenPLM,它利用更多的文本数据来弥补3D数据的不足。首先,受到CLIP的启发,我们使用预训练的点云-文本编码器将3D点云空间映射到文本空间,从而将文本空间与LLM无缝连接。一旦建立了点-文-LLM连接,我们通过扩展中间文本空间来进一步增强文本-LLM对齐,从而减少对3D点云数据的依赖。具体来说,我们生成了600万个3D对象的自由文本描述,并设计了一个三阶段训练策略,以帮助LLM更好地探索不同模态之间的内在联系。为了实现高效的模态对齐,我们设计了一个零参数交叉注意力模块用于token池化。大量的实验结果表明,GreenPLM仅需现有最先进模型使用的12%的3D训练数据即可实现卓越的3D理解。值得注意的是,GreenPLM仅使用文本数据也能实现具有竞争力的性能。
🔬 方法详解
问题定义:现有方法在3D点云-语言理解任务中,严重依赖大规模的3D-文本配对数据集。然而,获取和标注此类数据成本高昂,导致数据稀缺问题,阻碍了大型语言模型在3D场景理解中的应用。因此,如何利用有限的3D数据,甚至仅利用文本数据,实现鲁棒的3D对象理解是本文要解决的核心问题。
核心思路:GreenPLM的核心思路是“More Text, Less Point”,即利用更多的文本数据来弥补3D点云数据的不足。具体而言,首先将3D点云映射到文本空间,然后通过扩展文本空间,增强文本与大型语言模型(LLM)的对齐,从而减少对3D点云数据的依赖。这种设计思路的合理性在于,文本数据更容易获取,且LLM在文本理解方面已经展现出强大的能力。
技术框架:GreenPLM的整体框架包含以下几个主要模块:1) 预训练的点云-文本编码器:用于将3D点云映射到文本空间。2) 文本扩展模块:生成大量的3D对象自由文本描述,用于扩展文本空间。3) 大型语言模型(LLM):用于进行3D对象理解。4) 三阶段训练策略:用于帮助LLM更好地探索不同模态之间的内在联系。5) 零参数交叉注意力模块:用于实现高效的模态对齐。
关键创新:GreenPLM最重要的技术创新点在于其“More Text, Less Point”的思想,即利用更多的文本数据来弥补3D点云数据的不足。与现有方法相比,GreenPLM更加注重利用文本数据的优势,减少对昂贵的3D数据的依赖。此外,三阶段训练策略和零参数交叉注意力模块也为高效的模态对齐提供了保障。
关键设计:GreenPLM的关键设计包括:1) 使用预训练的CLIP模型作为点云-文本编码器的初始化。2) 生成600万个3D对象的自由文本描述,用于扩展文本空间。3) 设计了一个三阶段训练策略,包括:a) 点云-文本对齐阶段,b) 文本-LLM对齐阶段,c) 多模态融合阶段。4) 设计了一个零参数交叉注意力模块,用于token pooling,以实现高效的模态对齐。损失函数方面,主要采用对比学习损失和交叉熵损失。
🖼️ 关键图片
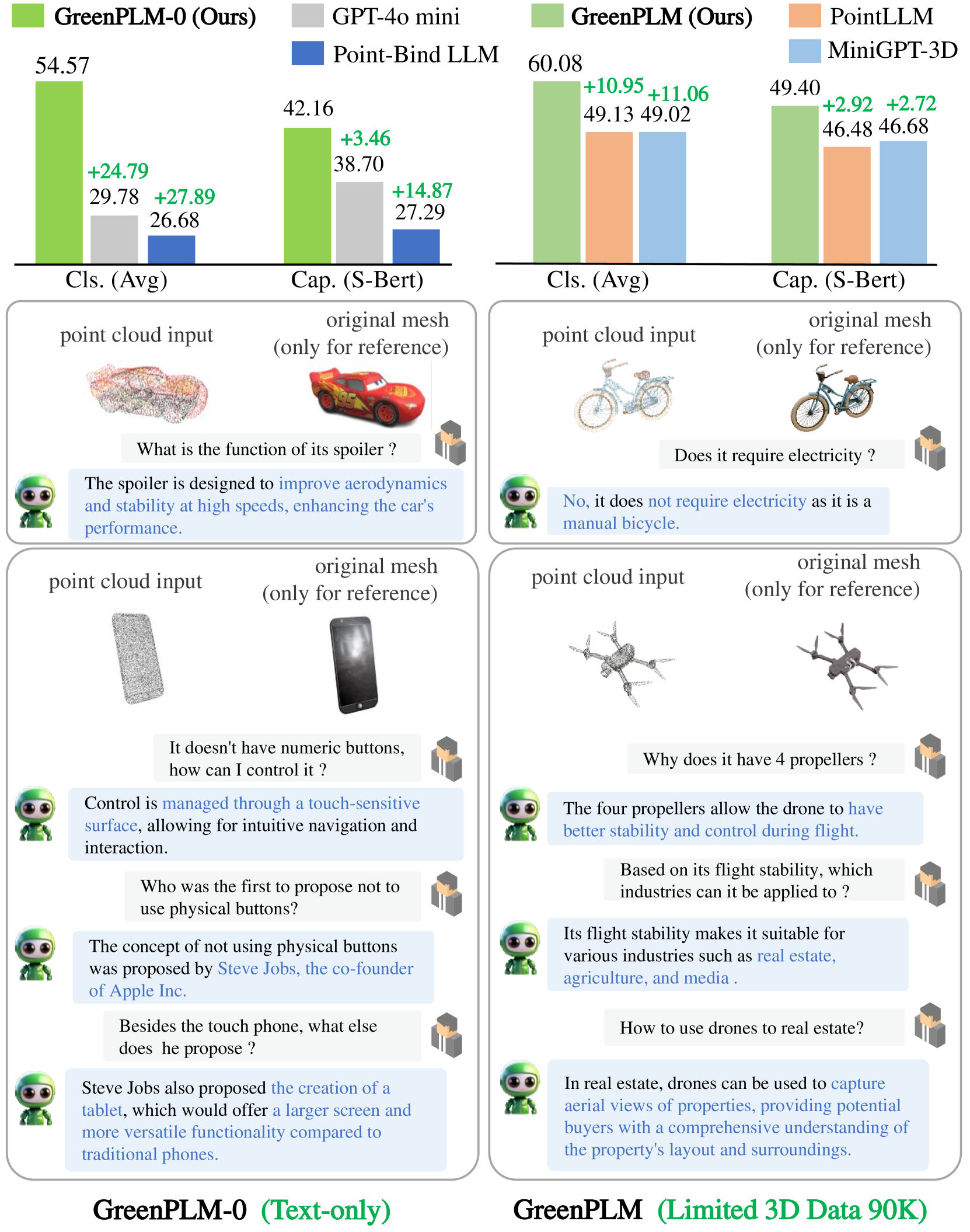

📊 实验亮点
GreenPLM仅使用现有最先进模型使用的12%的3D训练数据即可实现卓越的3D理解性能。在某些任务上,GreenPLM甚至超越了使用完整数据集训练的模型。更令人印象深刻的是,GreenPLM仅使用文本数据也能实现具有竞争力的性能,这表明了其强大的文本理解能力和模态迁移能力。
🎯 应用场景
GreenPLM在机器人导航、自动驾驶、虚拟现实和增强现实等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在自动驾驶领域,它可以提高车辆对3D场景的感知能力,从而提高驾驶安全性。在虚拟现实和增强现实领域,它可以增强用户与虚拟环境的交互体验。
📄 摘要(原文)
Enabling Large Language Models (LLMs) to comprehend the 3D physical world remains a significant challenge. Due to the lack of large-scale 3D-text pair datasets, the success of LLMs has yet to be replicated in 3D understanding. In this paper, we rethink this issue and propose a new task: 3D Data-Efficient Point-Language Understanding. The goal is to enable LLMs to achieve robust 3D object understanding with minimal 3D point cloud and text data pairs. To address this task, we introduce GreenPLM, which leverages more text data to compensate for the lack of 3D data. First, inspired by using CLIP to align images and text, we utilize a pre-trained point cloud-text encoder to map the 3D point cloud space to the text space. This mapping leaves us to seamlessly connect the text space with LLMs. Once the point-text-LLM connection is established, we further enhance text-LLM alignment by expanding the intermediate text space, thereby reducing the reliance on 3D point cloud data. Specifically, we generate 6M free-text descriptions of 3D objects, and design a three-stage training strategy to help LLMs better explore the intrinsic connections between different modalities. To achieve efficient modality alignment, we design a zero-parameter cross-attention module for token pooling. Extensive experimental results show that GreenPLM requires only 12% of the 3D training data used by existing state-of-the-art models to achieve superior 3D understanding. Remarkably, GreenPLM also achieves competitive performance using text-only data. The code and weights are available at: https://github.com/TangYuan96/GreenPLM.