A Survey on Evaluation of Multimodal Large Language Models
作者: Jiaxing Huang, Jingyi Zhang
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-08-28
💡 一句话要点
综述多模态大语言模型评测方法,促进更可靠的通用人工智能发展
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 模型评估 通用人工智能 评估基准 评估指标 多模态学习 人工智能
📋 核心要点
- 现有MLLM评估方法分散,缺乏系统性梳理,难以指导研究人员选择合适的评估方案。
- 本文对MLLM评估任务、基准和指标进行全面分类和总结,旨在为MLLM研究人员提供系统性的评估方法指导。
- 该综述强调了评估在MLLM发展中的重要性,并期望通过系统性评估促进更强大和可靠的MLLM的开发。
📝 摘要(中文)
本文全面综述了多模态大语言模型(MLLM)的评估方法。MLLM通过整合强大的大语言模型(LLM)与各种模态编码器(例如,视觉、音频)来模仿人类的感知和推理系统,将LLM定位为“大脑”,各种模态编码器定位为感觉器官。这种框架赋予了MLLM类人的能力,并暗示了实现通用人工智能(AGI)的潜在途径。随着GPT-4V和Gemini等全能MLLM的出现,人们开发了多种评估方法来评估它们在不同维度上的能力。本文对MLLM评估方法进行了系统而全面的回顾,涵盖以下关键方面:(1)MLLM及其评估的背景;(2)“评估什么”,回顾并根据评估的能力对现有的MLLM评估任务进行分类,包括通用多模态识别、感知、推理和可信度,以及特定领域的应用,如社会经济、自然科学和工程、医疗用途、AI代理、遥感、视频和音频处理、3D点云分析等;(3)“在哪里评估”,将MLLM评估基准总结为通用和特定基准;(4)“如何评估”,回顾并说明MLLM评估步骤和指标。我们的总体目标是为MLLM评估领域的研究人员提供有价值的见解,从而促进开发更强大和可靠的MLLM。我们强调,评估应被视为一个关键学科,对于推进MLLM领域至关重要。
🔬 方法详解
问题定义:现有MLLM的评估方法繁多且分散,缺乏统一的框架和标准,难以系统地评估MLLM在不同任务和领域的能力。此外,如何针对特定应用场景选择合适的评估基准和指标也是一个挑战。
核心思路:本文的核心思路是对现有的MLLM评估方法进行系统性的梳理和分类,从“评估什么”、“在哪里评估”和“如何评估”三个维度构建一个全面的评估框架。通过对评估任务、基准和指标的详细分析,为研究人员提供选择和设计MLLM评估方案的指导。
技术框架:该综述的技术框架主要包含以下几个部分:首先,介绍MLLM的背景和评估的重要性;其次,对MLLM的评估任务进行分类,包括通用多模态能力和特定领域的应用;然后,总结常用的MLLM评估基准,分为通用基准和特定领域基准;最后,回顾MLLM的评估步骤和指标,并进行详细的说明。
关键创新:本文的创新在于构建了一个系统性的MLLM评估框架,将现有的评估方法按照评估任务、评估基准和评估指标三个维度进行分类和总结。这种分类方法有助于研究人员更好地理解MLLM的评估体系,并为设计新的评估方法提供指导。
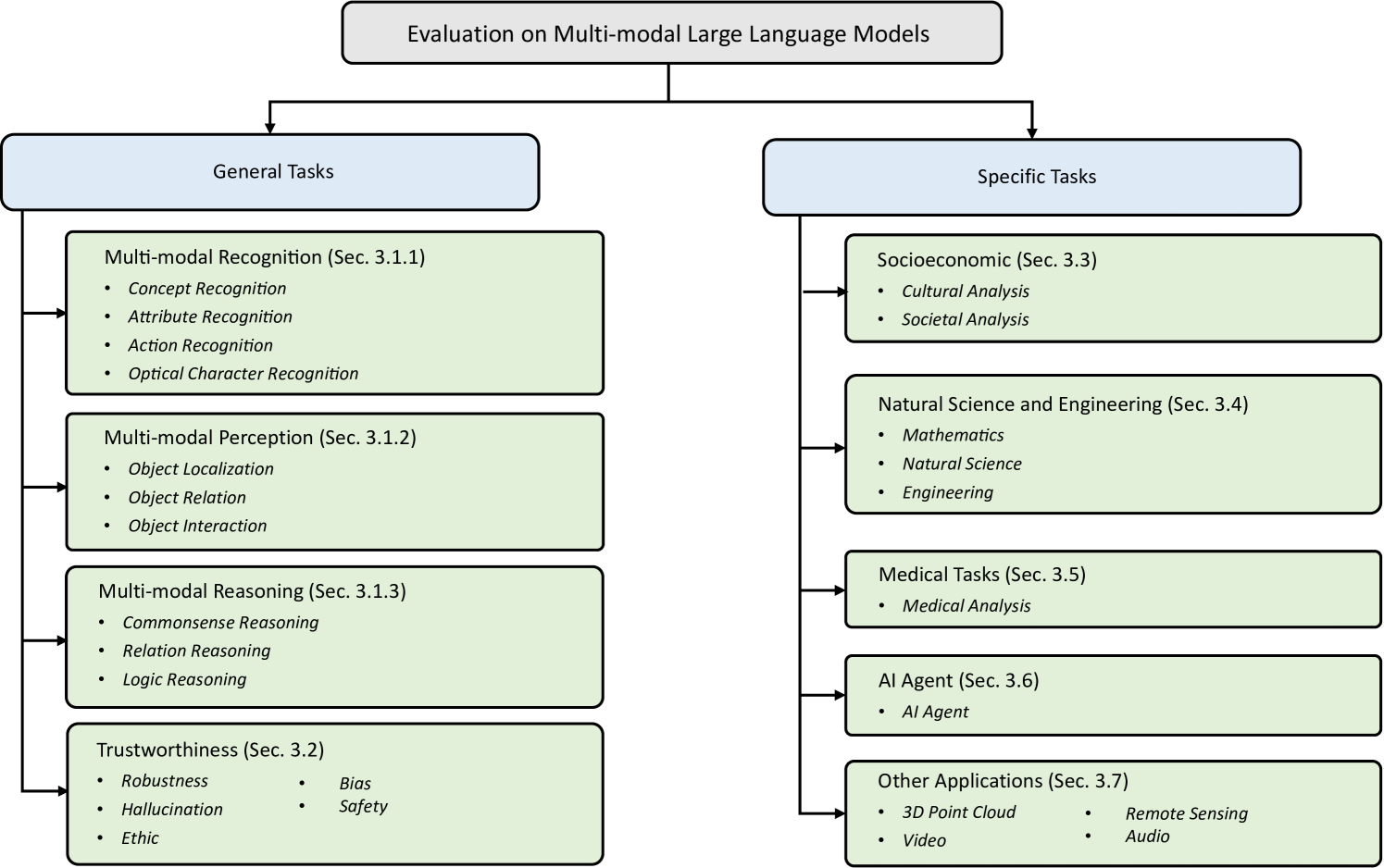
关键设计:本文的关键设计在于对评估任务的分类,包括通用多模态识别、感知、推理和可信度,以及特定领域的应用,如社会经济、自然科学和工程、医疗用途、AI代理、遥感、视频和音频处理、3D点云分析等。这种分类方式能够帮助研究人员针对不同的应用场景选择合适的评估方法。
🖼️ 关键图片
📊 实验亮点
该综述系统性地总结了MLLM的评估方法,并将其分为通用能力评估和特定领域应用评估两大类。通过对现有评估基准和指标的分析,为研究人员提供了选择和设计MLLM评估方案的指导,有助于推动MLLM的性能提升和应用拓展。
🎯 应用场景
该研究成果可应用于指导MLLM的开发和改进,促进其在各个领域的应用,例如智能助手、医疗诊断、自动驾驶、工业自动化等。通过系统性的评估,可以提高MLLM的可靠性和安全性,加速其在实际场景中的部署。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the "brain" and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) "what to evaluate" that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) "where to evaluate" that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) "how to evaluate" that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.