Learning-based Multi-View Stereo: A Survey
作者: Fangjinhua Wang, Qingtian Zhu, Di Chang, Quankai Gao, Junlin Han, Tong Zhang, Richard Hartley, Marc Pollefeys
分类: cs.CV
发布日期: 2024-08-27 (更新: 2026-01-13)
备注: Accepted to IEEE T-PAMI 2026
💡 一句话要点
综述学习型多视图立体视觉方法,重点分析深度图方法并展望未来方向。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 多视图立体视觉 三维重建 深度学习 深度图估计 计算机视觉
📋 核心要点
- 传统MVS方法在复杂光照、纹理缺失等场景下重建效果不佳,鲁棒性有待提升。
- 本文对基于学习的MVS方法进行分类和综述,重点关注深度图方法,分析其优势与不足。
- 总结了现有方法在常用数据集上的性能,并对未来研究方向进行了展望,为后续研究提供参考。
📝 摘要(中文)
三维重建旨在恢复场景的稠密三维结构,在增强/虚拟现实(AR/VR)、自动驾驶和机器人等应用中至关重要。多视图立体视觉(MVS)算法利用从不同视点捕获的场景的多幅图像,合成全面的三维表示,从而能够在复杂环境中进行精确重建。由于其效率和有效性,MVS已成为基于图像的三维重建的关键方法。近年来,随着深度学习的成功,许多基于学习的MVS方法被提出,相对于传统方法取得了令人瞩目的性能。我们将这些基于学习的方法分为:基于深度图、基于体素、基于NeRF、基于3D高斯溅射和大型前馈方法。其中,我们重点关注基于深度图的方法,由于其简洁性、灵活性和可扩展性,它是MVS的主要分支。在本综述中,我们对撰写本文时的文献进行了全面回顾。我们研究了这些基于学习的方法,总结了它们在常用基准测试中的性能,并讨论了该领域有希望的未来研究方向。
🔬 方法详解
问题定义:论文旨在对基于学习的多视图立体视觉(MVS)方法进行全面的综述,特别是针对深度图估计方法。现有MVS方法在处理复杂场景(如光照变化、纹理缺失、遮挡等)时,重建精度和鲁棒性面临挑战。传统方法依赖手工设计的特征和优化策略,泛化能力有限。
核心思路:论文的核心思路是对现有基于学习的MVS方法进行系统性的分类、分析和比较,从而帮助研究人员快速了解该领域的研究现状和发展趋势。通过重点分析深度图估计方法,揭示其在MVS中的重要地位和优势。
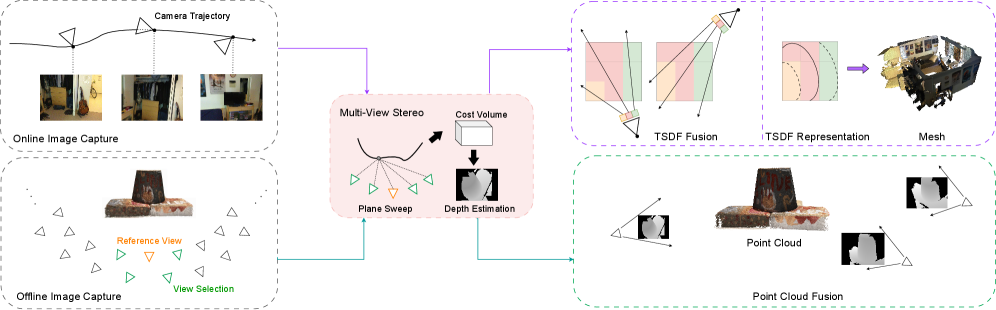
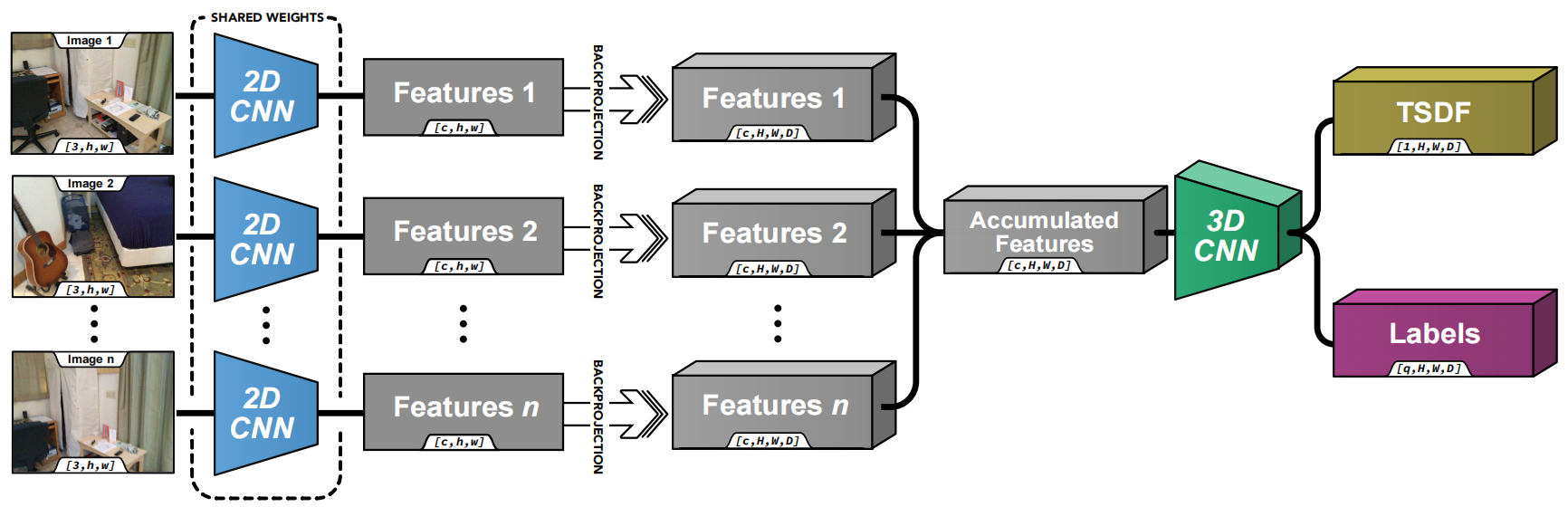
技术框架:论文首先对MVS问题进行简要介绍,然后将基于学习的MVS方法分为五大类:基于深度图、基于体素、基于NeRF、基于3D高斯溅射和大型前馈方法。接着,论文深入分析了基于深度图的方法,包括其基本原理、网络结构、损失函数和优化策略。最后,论文总结了现有方法在常用基准测试中的性能,并讨论了未来研究方向。
关键创新:该论文的主要创新在于对现有基于学习的MVS方法进行了全面的分类和综述,特别是对深度图估计方法进行了深入分析。此外,论文还对未来研究方向进行了展望,为后续研究提供了有价值的参考。
关键设计:论文对各类方法的网络结构、损失函数和训练策略进行了详细描述。例如,对于基于深度图的方法,论文分析了不同的深度图表示方法(如离散深度、连续深度)、深度图融合策略(如方差融合、学习融合)以及深度图优化方法(如深度图细化、深度图滤波)。
🖼️ 关键图片

📊 实验亮点
该综述总结了当前主流的基于学习的MVS方法在多个公开数据集上的性能表现,例如DTU、Tanks and Temples等。通过对比不同方法的精度、完整性和运行效率,为研究人员选择合适的MVS算法提供了参考依据。虽然论文没有提出新的算法,但其对现有方法的系统性分析和未来方向展望,对后续研究具有指导意义。
🎯 应用场景
该研究成果可广泛应用于增强现实/虚拟现实(AR/VR)、自动驾驶、机器人导航、三维地图构建、文物数字化保护等领域。通过提高三维重建的精度和鲁棒性,可以为这些应用提供更可靠的环境感知和交互能力,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
3D reconstruction aims to recover the dense 3D structure of a scene. It plays an essential role in various applications such as Augmented/Virtual Reality (AR/VR), autonomous driving and robotics. Leveraging multiple views of a scene captured from different viewpoints, Multi-View Stereo (MVS) algorithms synthesize a comprehensive 3D representation, enabling precise reconstruction in complex environments. Due to its efficiency and effectiveness, MVS has become a pivotal method for image-based 3D reconstruction. Recently, with the success of deep learning, many learning-based MVS methods have been proposed, achieving impressive performance against traditional methods. We categorize these learning-based methods as: depth map-based, voxel-based, NeRF-based, 3D Gaussian Splatting-based, and large feed-forward methods. Among these, we focus significantly on depth map-based methods, which are the main family of MVS due to their conciseness, flexibility and scalability. In this survey, we provide a comprehensive review of the literature at the time of this writing. We investigate these learning-based methods, summarize their performances on popular benchmarks, and discuss promising future research directions in this area.