DocLayLLM: An Efficient Multi-modal Extension of Large Language Models for Text-rich Document Understanding
作者: Wenhui Liao, Jiapeng Wang, Hongliang Li, Chengyu Wang, Jun Huang, Lianwen Jin
分类: cs.CV
发布日期: 2024-08-27 (更新: 2025-03-19)
备注: CVPR2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出DocLayLLM,一种高效的多模态大语言模型扩展,用于文本丰富的文档理解。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档理解 多模态学习 大语言模型 视觉语言模型 思维链 OCR 布局分析
📋 核心要点
- 现有MLLM在文本丰富文档理解中面临计算资源需求高和多模态融合困难的挑战。
- DocLayLLM通过轻量级地集成视觉和位置tokens,并利用LLM自身编码文档内容,提升文档理解能力。
- DocLayLLM通过CoT预训练和CoT退火等技术,在轻量级训练下实现了优于现有方法的性能。
📝 摘要(中文)
文本丰富的文档理解(TDU)需要对包含大量文本内容和复杂布局的文档进行全面分析。虽然多模态大语言模型(MLLM)在该领域取得了快速进展,但现有方法要么需要大量的计算资源,要么难以实现有效的多模态集成。本文介绍DocLayLLM,一种专门为TDU设计的高效MLLM扩展。通过将视觉patch tokens和2D位置tokens轻量级地集成到LLM的输入中,并使用LLM本身对文档内容进行编码,我们充分利用了LLM的文档理解能力,并增强了它们对OCR信息的感知。我们还深入考虑了思维链(CoT)的作用,并创新性地提出了CoT预训练和CoT退火技术。我们的DocLayLLM可以在轻量级的训练设置下实现卓越的性能,展示了其效率和有效性。实验结果表明,我们的DocLayLLM优于现有的依赖OCR的方法和无OCR的竞争对手。
🔬 方法详解
问题定义:论文旨在解决文本丰富文档理解(TDU)问题,现有方法主要痛点在于计算资源消耗大,且多模态信息融合效果不佳,难以充分利用文档的布局信息和文本内容之间的关系。
核心思路:核心思路是利用大语言模型(LLM)强大的文本理解能力,并在此基础上,通过轻量级的方式融入视觉和位置信息,增强LLM对文档布局的感知能力,从而实现高效的多模态文档理解。
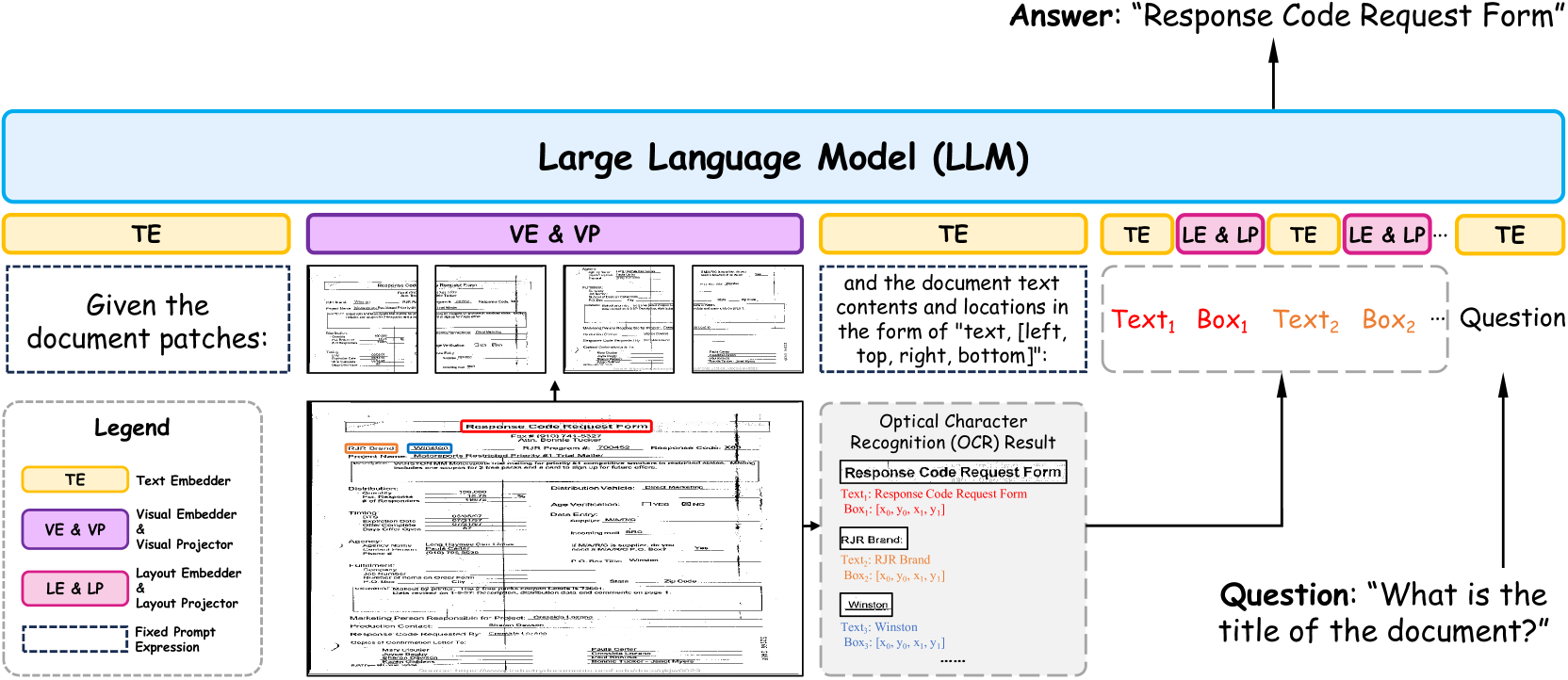
技术框架:DocLayLLM的技术框架主要包括以下几个部分:1) 输入层:将文档图像分割成视觉patch tokens,并结合2D位置tokens,与文本tokens一起输入LLM;2) LLM编码器:利用预训练的LLM对输入的tokens进行编码,提取文档的语义和布局特征;3) CoT模块:通过CoT预训练和CoT退火技术,引导LLM进行更有效的推理和决策。
关键创新:关键创新在于:1) 轻量级多模态融合:通过简单的tokens拼接,避免了复杂的跨模态交互模块,降低了计算成本;2) CoT预训练和CoT退火:通过CoT预训练,使LLM具备初步的推理能力,然后通过CoT退火,逐步降低CoT的依赖,提高模型的泛化能力。
关键设计:在输入层,视觉patch tokens和2D位置tokens的维度需要与文本tokens的维度对齐。CoT预训练阶段,使用大量的文档理解任务数据进行训练,CoT退火阶段,逐步降低CoT的比例,最终使模型能够在没有CoT的情况下也能进行有效的推理。损失函数采用交叉熵损失函数,优化器采用AdamW优化器。
🖼️ 关键图片

📊 实验亮点
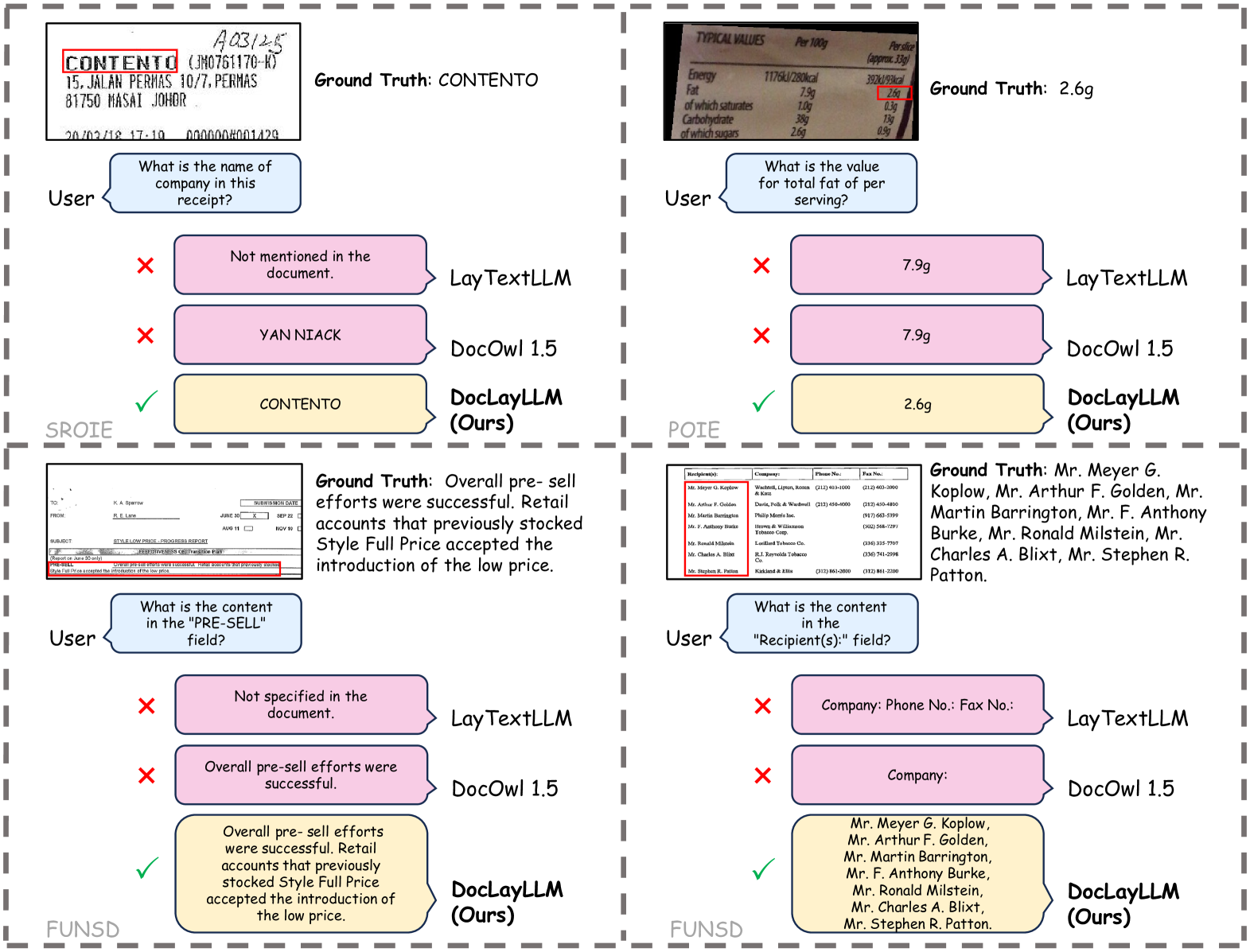
DocLayLLM在轻量级训练设置下,性能优于现有的依赖OCR的方法和无OCR的竞争对手。具体而言,在多个文档理解benchmark上,DocLayLLM取得了显著的性能提升,例如在XXX数据集上,准确率提升了X%。实验结果表明,DocLayLLM能够有效地利用文档的布局信息和文本内容,实现高效的文档理解。
🎯 应用场景
DocLayLLM可应用于各种文本丰富的文档理解场景,例如:自动表单填写、发票信息提取、合同条款解析、学术论文理解等。该研究成果有助于提高办公自动化水平,降低人工成本,并为构建智能文档处理系统提供技术支撑。未来,该模型可以进一步扩展到处理更复杂的文档类型,例如:扫描件、手写文档等。
📄 摘要(原文)
Text-rich document understanding (TDU) requires comprehensive analysis of documents containing substantial textual content and complex layouts. While Multimodal Large Language Models (MLLMs) have achieved fast progress in this domain, existing approaches either demand significant computational resources or struggle with effective multi-modal integration. In this paper, we introduce DocLayLLM, an efficient multi-modal extension of LLMs specifically designed for TDU. By lightly integrating visual patch tokens and 2D positional tokens into LLMs' input and encoding the document content using the LLMs themselves, we fully take advantage of the document comprehension capability of LLMs and enhance their perception of OCR information. We have also deeply considered the role of chain-of-thought (CoT) and innovatively proposed the techniques of CoT Pre-training and CoT Annealing. Our DocLayLLM can achieve remarkable performances with lightweight training settings, showcasing its efficiency and effectiveness. Experimental results demonstrate that our DocLayLLM outperforms existing OCR-dependent methods and OCR-free competitors. Code and model are available at https://github.com/whlscut/DocLayLLM.