HPT++: Hierarchically Prompting Vision-Language Models with Multi-Granularity Knowledge Generation and Improved Structure Modeling
作者: Yubin Wang, Xinyang Jiang, De Cheng, Wenli Sun, Dongsheng Li, Cairong Zhao
分类: cs.CV
发布日期: 2024-08-27
备注: 19 pages, 7 figures, 7 tables. arXiv admin note: substantial text overlap with arXiv:2312.06323
💡 一句话要点
HPT++:通过多粒度知识生成和改进的结构建模,分层提示视觉-语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 提示学习 知识图谱 分层提示 关系建模
📋 核心要点
- 现有方法缺乏对类别相关描述中结构化信息的有效利用,限制了提示学习的性能。
- HPT++利用LLM构建知识图谱,并设计分层提示结构,同时建模结构化和非结构化知识。
- 实验表明,HPT++在多种泛化任务上显著优于现有SOTA方法,验证了其有效性。
📝 摘要(中文)
提示学习已成为将CLIP等视觉-语言基础模型(VLMs)适配到下游任务的常用策略。随着大型语言模型(LLMs)的出现,最近的研究探索了使用类别相关描述来增强提示有效性的潜力。然而,传统的描述缺乏明确的结构化信息,而这些信息对于表示关键元素(如实体或属性)与特定类别之间的相互联系至关重要。由于现有的提示调优方法很少考虑管理结构化知识,本文提倡利用LLMs为每个描述构建一个图,以优先考虑这种结构化知识。因此,我们提出了一种名为分层提示调优(HPT)的新方法,能够同时建模结构化和传统的语言知识。具体来说,我们引入了一个关系引导的注意力模块,以捕获实体和属性之间的成对关联,用于低级提示学习。此外,通过结合建模整体语义的高级和全局级提示,所提出的分层结构形成了跨层互连,并使模型能够处理更复杂和长期的关系。最后,通过增强多粒度知识生成,重新设计关系驱动的注意力重加权模块,并对分层文本编码器施加一致性约束,我们提出了HPT++,它进一步提高了HPT的性能。我们的实验在广泛的评估设置中进行,包括基类到新类的泛化、跨数据集评估和领域泛化。大量的实验结果和消融研究证明了我们方法的有效性,该方法始终优于现有的SOTA方法。
🔬 方法详解
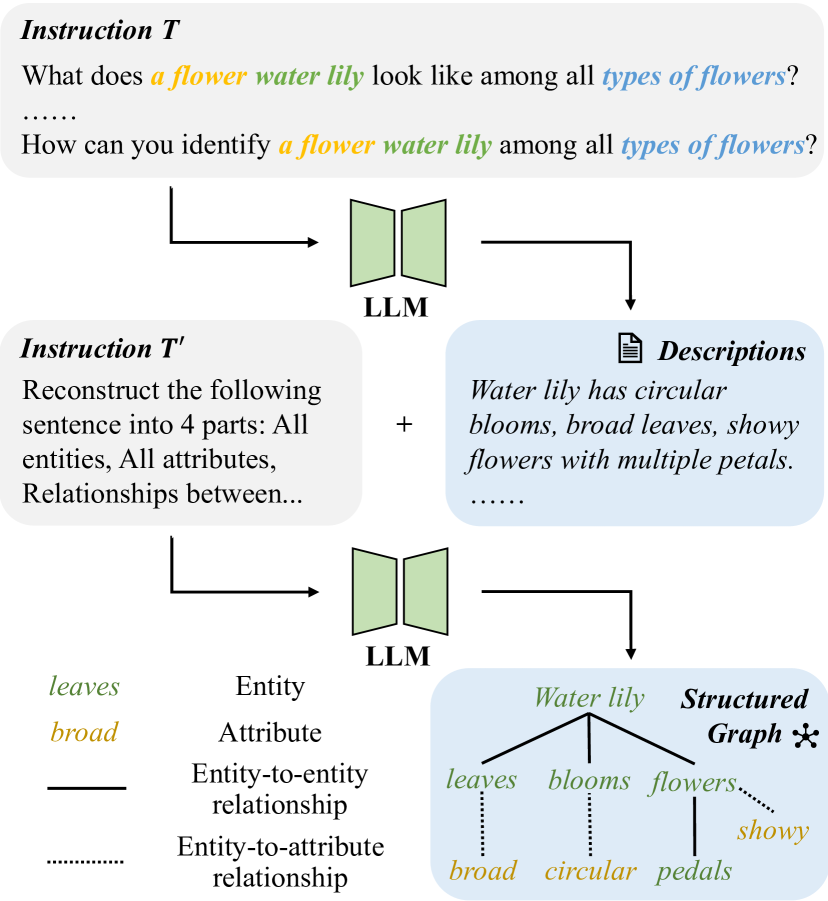
问题定义:现有的视觉-语言模型(VLM)的提示调优方法,在利用类别相关描述时,未能充分挖掘和利用其中蕴含的结构化知识,例如实体、属性以及它们之间的关系。这种结构化信息的缺失限制了模型对复杂语义的理解和泛化能力。
核心思路:论文的核心思路是利用大型语言模型(LLM)生成类别描述的知识图谱,并将结构化知识融入到提示学习过程中。通过构建分层提示结构,模型可以同时学习结构化和非结构化的知识,从而提高提示的有效性和模型的性能。
技术框架:HPT++包含以下主要模块:1) 利用LLM生成类别描述的知识图谱;2) 构建分层提示结构,包括低级(实体和属性)、高级(局部语义)和全局级(整体语义)提示;3) 设计关系引导的注意力模块,用于捕获实体和属性之间的成对关联;4) 采用一致性约束,保证分层文本编码器的一致性。
关键创新:HPT++的关键创新在于:1) 提出了一种利用LLM生成知识图谱并融入提示学习的方法;2) 设计了一种分层提示结构,能够同时建模结构化和非结构化的知识;3) 引入了关系引导的注意力模块,用于捕获实体和属性之间的关系。
关键设计:关系引导的注意力模块通过计算实体和属性之间的注意力权重,来捕捉它们之间的关联。分层提示结构通过跨层互连,使模型能够处理更复杂和长期的关系。一致性约束通过最小化不同层级编码器输出的差异,来保证模型的一致性。
🖼️ 关键图片


📊 实验亮点
HPT++在基类到新类的泛化、跨数据集评估和领域泛化等多个任务上都取得了显著的性能提升,超越了现有的SOTA方法。例如,在某些任务上,HPT++的准确率提升超过5%,证明了其有效性。
🎯 应用场景
HPT++可应用于各种视觉-语言任务,例如图像分类、零样本学习、跨数据集泛化和领域泛化。该方法能够提高模型对复杂场景的理解能力,并增强其在不同领域和数据集上的泛化性能,具有广泛的应用前景。
📄 摘要(原文)
Prompt learning has become a prevalent strategy for adapting vision-language foundation models (VLMs) such as CLIP to downstream tasks. With the emergence of large language models (LLMs), recent studies have explored the potential of using category-related descriptions to enhance prompt effectiveness. However, conventional descriptions lack explicit structured information necessary to represent the interconnections among key elements like entities or attributes with relation to a particular category. Since existing prompt tuning methods give little consideration to managing structured knowledge, this paper advocates leveraging LLMs to construct a graph for each description to prioritize such structured knowledge. Consequently, we propose a novel approach called Hierarchical Prompt Tuning (HPT), enabling simultaneous modeling of both structured and conventional linguistic knowledge. Specifically, we introduce a relationship-guided attention module to capture pair-wise associations among entities and attributes for low-level prompt learning. In addition, by incorporating high-level and global-level prompts modeling overall semantics, the proposed hierarchical structure forges cross-level interlinks and empowers the model to handle more complex and long-term relationships. Finally, by enhancing multi-granularity knowledge generation, redesigning the relationship-driven attention re-weighting module, and incorporating consistent constraints on the hierarchical text encoder, we propose HPT++, which further improves the performance of HPT. Our experiments are conducted across a wide range of evaluation settings, including base-to-new generalization, cross-dataset evaluation, and domain generalization. Extensive results and ablation studies demonstrate the effectiveness of our methods, which consistently outperform existing SOTA methods.