Text-guided Foundation Model Adaptation for Long-Tailed Medical Image Classification
作者: Sirui Li, Li Lin, Yijin Huang, Pujin Cheng, Xiaoying Tang
分类: cs.CV
发布日期: 2024-08-27
备注: Accepted by IEEE ISBI 2024
💡 一句话要点
提出TFA-LT,通过文本引导的微调方法解决医学图像长尾分类问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长尾学习 医学图像分类 预训练模型 文本引导 多模态学习
📋 核心要点
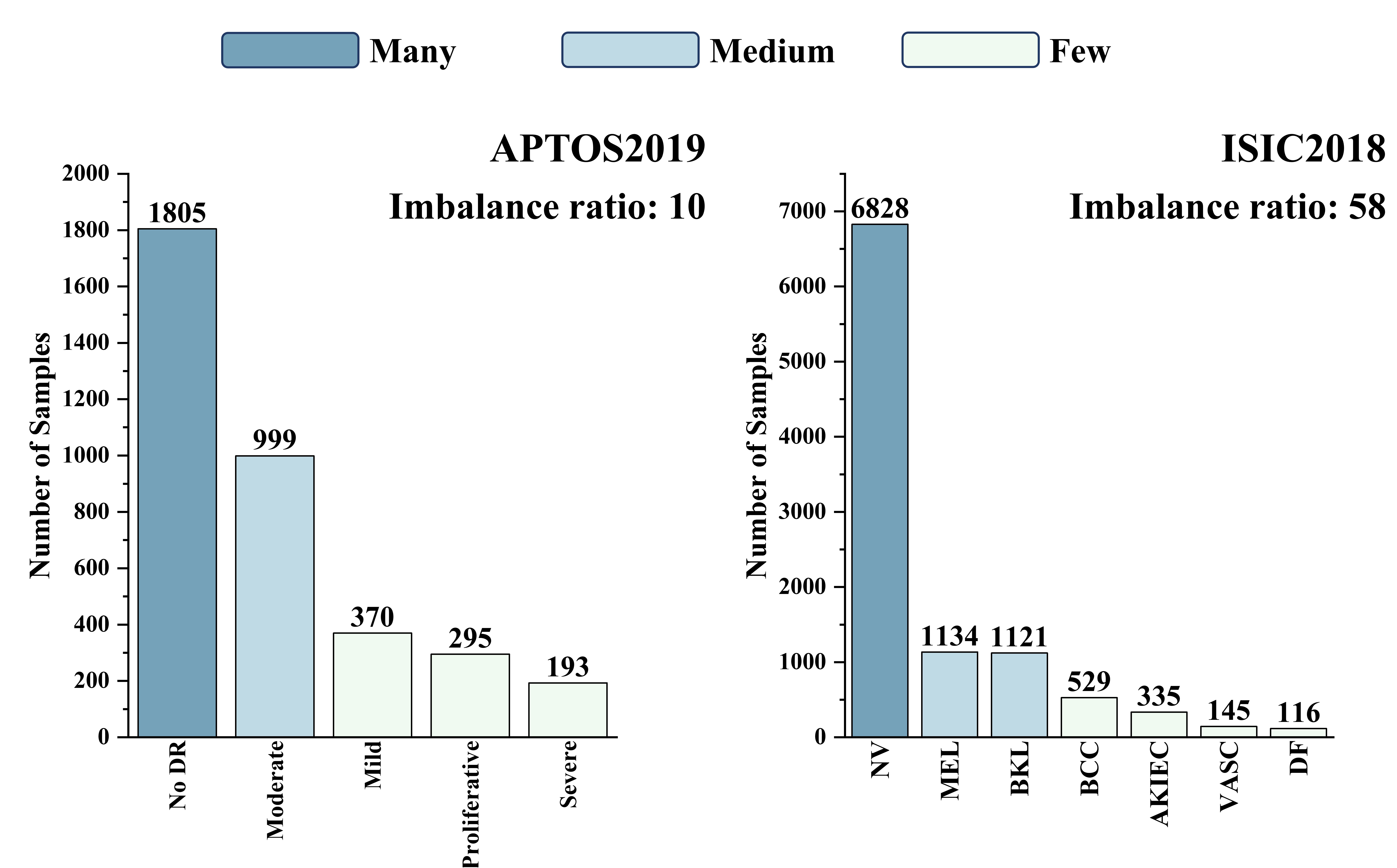
- 医学图像长尾分布导致罕见疾病诊断精度低,现有方法难以有效利用有限数据。
- TFA-LT通过文本引导的预训练模型微调,利用少量线性适配器和集成器实现性能提升。
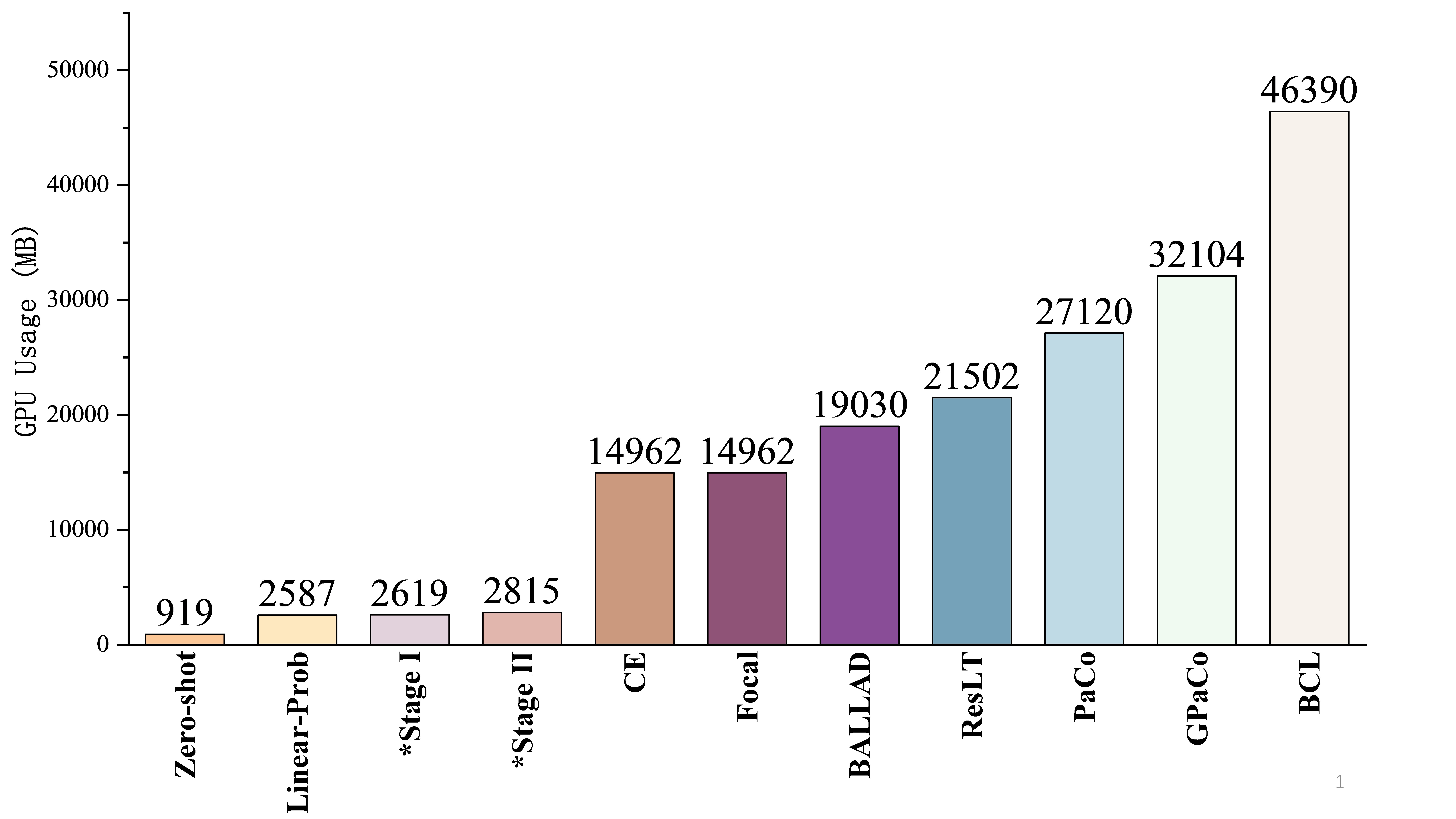
- 实验表明,TFA-LT在显著降低计算资源需求的同时,大幅提升了长尾医学图像分类的准确率。
📝 摘要(中文)
在医学领域,由于罕见疾病标签的稀缺性,长尾数据集中的不平衡数据分布严重影响了深度学习模型的诊断准确性。最近的多模态文本-图像监督预训练模型为数据稀缺问题提供了新的解决方案。然而,相对于自然图像,它们在医学领域的预训练不足限制了其在医学图像分类中的性能。为了解决这个问题,我们提出了一种新的文本引导的预训练模型微调方法,用于长尾医学图像分类(TFA-LT)。我们采用了一种两阶段训练策略,仅使用两个线性适配器和一个集成器来整合预训练模型的表征,以实现平衡的结果。在两个长尾医学图像数据集上的实验结果验证了我们方法的简单性、轻量性和效率:我们的方法仅需当前最佳算法6.1%的GPU内存使用量,即可实现高达27.1%的准确率提升,突出了预训练模型微调在该领域的巨大潜力。
🔬 方法详解
问题定义:论文旨在解决医学图像分类中,由于长尾数据分布导致的模型性能下降问题。具体来说,罕见疾病的图像数据非常有限,使得模型难以学习到有效的特征表示,从而影响诊断准确性。现有方法通常需要大量的计算资源和复杂的训练策略,且泛化能力有限。
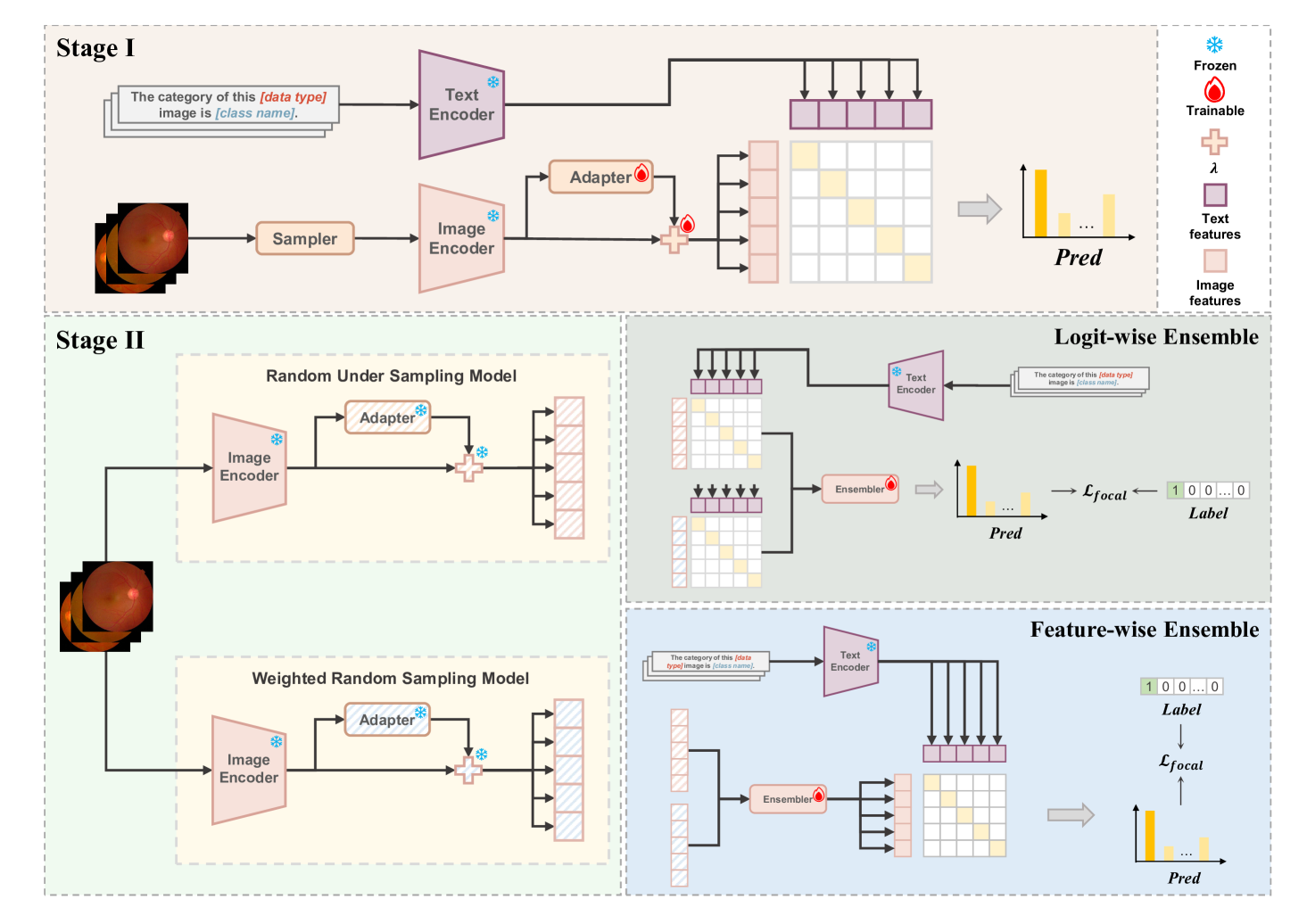
核心思路:论文的核心思路是利用预训练的文本-图像多模态模型,通过文本信息引导模型适应医学图像分类任务。由于预训练模型已经在大量数据上学习了通用的视觉和语言知识,因此可以通过微调的方式,将其知识迁移到医学图像领域,从而缓解数据稀缺问题。同时,利用文本信息可以更好地指导模型学习医学图像的特征表示。
技术框架:TFA-LT采用两阶段训练策略。第一阶段,使用两个线性适配器分别连接到预训练模型的图像编码器和文本编码器,并使用文本信息引导图像特征的学习。第二阶段,使用一个集成器将两个适配器的输出进行融合,以获得最终的分类结果。整个框架结构简单,易于实现。
关键创新:该方法最重要的创新点在于利用文本信息引导预训练模型的微调过程。通过将文本信息融入到训练过程中,可以更好地利用预训练模型的知识,并使其更好地适应医学图像分类任务。此外,该方法采用轻量级的线性适配器和集成器,降低了计算资源的需求。
关键设计:在第一阶段,使用对比学习损失函数来训练图像和文本适配器,使得图像特征和文本特征在嵌入空间中更加接近。在第二阶段,使用交叉熵损失函数来训练集成器,以优化最终的分类结果。线性适配器的维度设置为预训练模型特征维度的1/4,以降低计算量。集成器采用简单的加权平均方式进行融合。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TFA-LT在两个长尾医学图像数据集上均取得了显著的性能提升。在CXR数据集上,TFA-LT的准确率提升了27.1%,在Derm7pt数据集上,准确率提升了12.5%。更重要的是,TFA-LT仅需当前最佳算法6.1%的GPU内存使用量,验证了其轻量性和高效性。
🎯 应用场景
该研究成果可应用于多种医学图像诊断场景,尤其是在罕见疾病诊断方面具有重要价值。通过利用预训练模型和文本信息,可以有效提高诊断准确率,辅助医生进行更准确的判断。未来,该方法有望推广到其他长尾数据分布的医学图像分析任务中,例如病理图像分析、眼底图像分析等。
📄 摘要(原文)
In medical contexts, the imbalanced data distribution in long-tailed datasets, due to scarce labels for rare diseases, greatly impairs the diagnostic accuracy of deep learning models. Recent multimodal text-image supervised foundation models offer new solutions to data scarcity through effective representation learning. However, their limited medical-specific pretraining hinders their performance in medical image classification relative to natural images. To address this issue, we propose a novel Text-guided Foundation model Adaptation for Long-Tailed medical image classification (TFA-LT). We adopt a two-stage training strategy, integrating representations from the foundation model using just two linear adapters and a single ensembler for balanced outcomes. Experimental results on two long-tailed medical image datasets validate the simplicity, lightweight and efficiency of our approach: requiring only 6.1% GPU memory usage of the current best-performing algorithm, our method achieves an accuracy improvement of up to 27.1%, highlighting the substantial potential of foundation model adaptation in this area.