Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos
作者: Qirui Chen, Shangzhe Di, Weidi Xie
分类: cs.CV
发布日期: 2024-08-26
💡 一句话要点
提出GeLM模型,解决长时第一视角视频多跳问答中的时序定位与推理难题
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多跳问答 长时视频 第一视角视频 时序定位 多模态学习 大语言模型 视觉推理
📋 核心要点
- 现有方法在长时第一视角视频多跳问答中,缺乏有效的时序定位和多跳推理能力,难以准确提取证据。
- 提出GeLM模型,通过引入 grounding 模块,利用灵活的 grounding tokens 从视频中检索时序证据,增强多模态大语言模型。
- GeLM在MultiHop-EgoQA数据集上取得了显著提升,并在ActivityNet-RTL数据集上达到了SOTA,验证了其有效性。
📝 摘要(中文)
本文研究了长时第一视角视频中的多跳视频问答(MH-VidQA)问题。该任务不仅需要回答视觉问题,还需要定位视频中多个相关的时序区间作为视觉证据。我们开发了一个自动化的流程来创建包含相关时序证据的多跳问答对,从而构建一个大规模的指令调优数据集。为了评估该任务的进展,我们进一步构建了一个高质量的基准数据集MultiHop-EgoQA,并进行了细致的人工验证和改进。实验结果表明,现有的多模态系统在多跳定位和推理能力方面表现不足,导致性能不佳。为此,我们提出了一种新的架构,称为基于大语言模型进行证据定位(GeLM),通过整合一个定位模块,利用灵活的定位tokens从视频中检索时序证据,从而增强多模态大语言模型(MLLMs)。在我们的视觉指令数据上训练后,GeLM展示了改进的多跳定位和推理能力,为这项具有挑战性的任务设定了新的基线。此外,当在第三人称视角视频上训练时,相同的架构在单跳VidQA基准数据集ActivityNet-RTL上也取得了最先进的性能,证明了其有效性。
🔬 方法详解
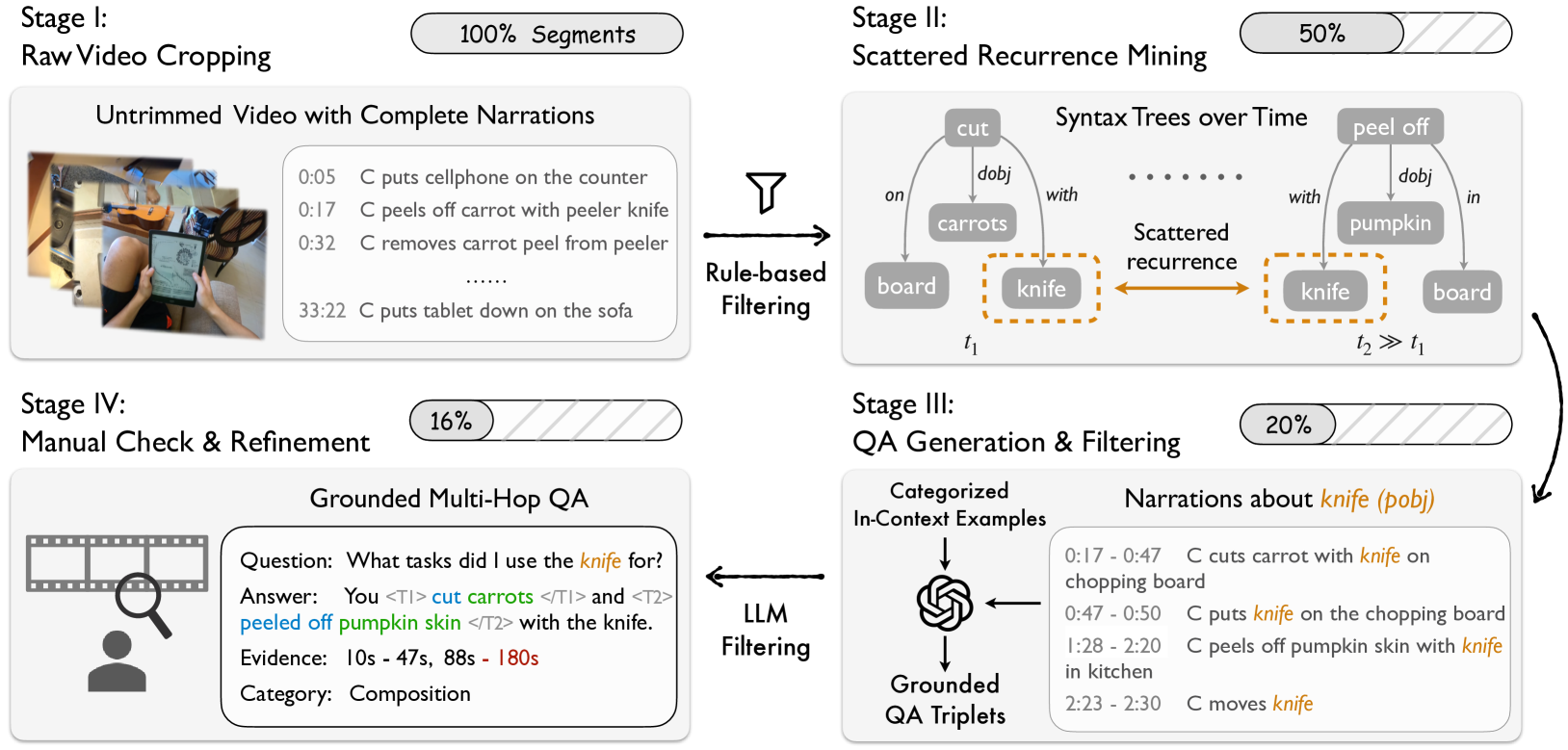
问题定义:论文旨在解决长时第一视角视频中的多跳视频问答(MH-VidQA)问题。现有方法在处理此类问题时,面临着两个主要痛点:一是难以准确地从长视频中定位多个相关的时序区间作为视觉证据;二是缺乏有效的多跳推理能力,无法将多个证据片段整合起来回答复杂问题。
核心思路:论文的核心思路是利用 grounding 模块增强多模态大语言模型(MLLMs),使其能够更好地从视频中定位和提取时序证据。通过引入灵活的 grounding tokens,模型可以学习到如何根据问题定位相关的视频片段,并将这些片段作为上下文输入到大语言模型中进行推理。这种方法将时序定位和多跳推理解耦,使得模型可以专注于学习更有效的推理策略。
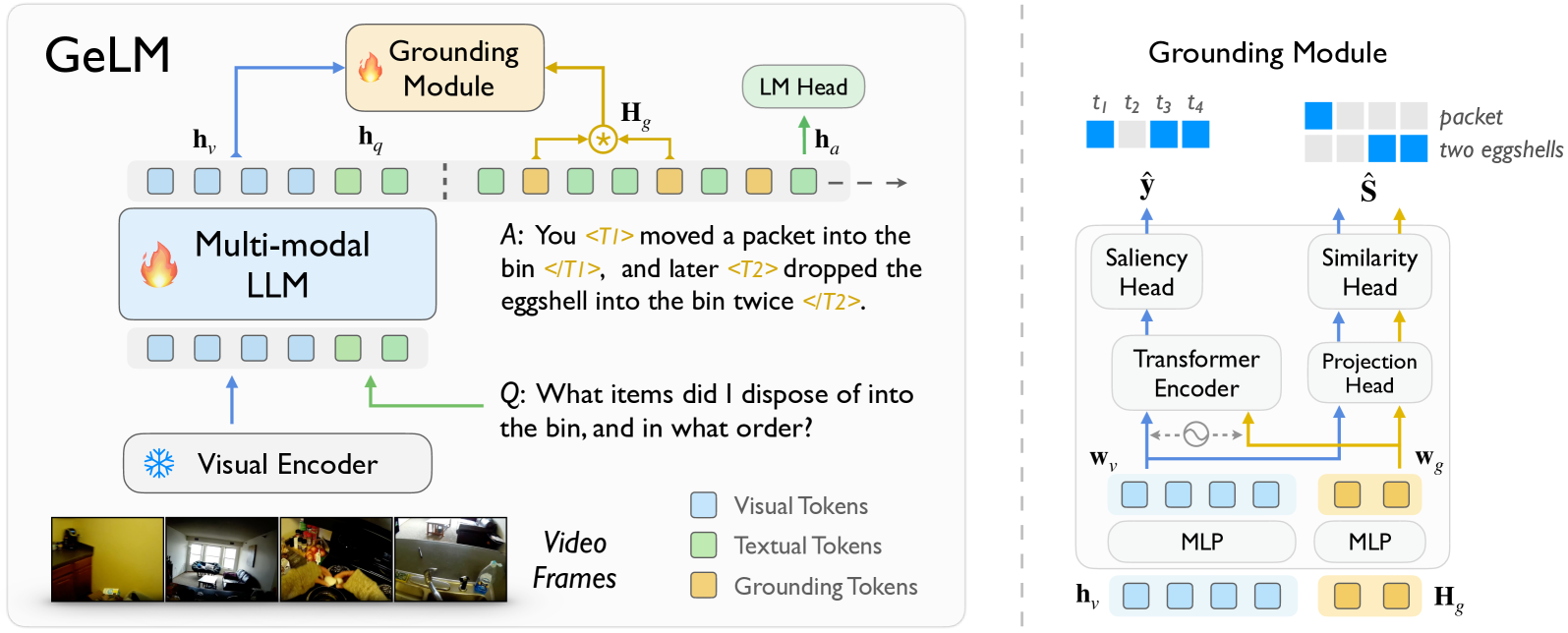
技术框架:GeLM的整体架构包含以下几个主要模块:1) 视频编码器:用于将视频帧编码成视觉特征;2) 问题编码器:用于将问题编码成文本特征;3) Grounding模块:利用问题特征和视频特征,预测与问题相关的时序区间;4) 大语言模型(LLM):将问题特征和提取到的视频片段特征作为输入,生成答案。整个流程是:首先,视频和问题分别通过编码器提取特征;然后,Grounding模块根据问题特征在视频中定位相关的时序区间;最后,将问题特征和提取到的视频片段特征输入到LLM中,生成答案。
关键创新:论文最重要的技术创新点在于提出了基于 grounding tokens 的 grounding 模块。与传统的时序定位方法不同,该模块不直接预测具体的时序边界,而是学习一组 grounding tokens,这些 tokens 可以灵活地表示不同的时序区间。这种方法可以更好地处理多跳问答问题,因为不同的 grounding tokens 可以对应于不同的证据片段。
关键设计:在 grounding 模块中,论文使用了 Transformer 结构来学习 grounding tokens。具体来说,问题特征被用作 query,视频特征被用作 key 和 value,通过 self-attention 机制学习 grounding tokens。损失函数包括一个定位损失和一个问答损失。定位损失用于监督 grounding 模块的训练,使其能够准确地定位相关的时序区间。问答损失用于监督 LLM 的训练,使其能够根据提取到的视频片段生成正确的答案。
🖼️ 关键图片

📊 实验亮点
GeLM在MultiHop-EgoQA数据集上取得了显著的性能提升,相较于现有方法,在多跳问答的准确率上有了明显的提高。此外,GeLM在ActivityNet-RTL数据集上也达到了state-of-the-art的性能,证明了其在单跳视频问答任务上的有效性。这些实验结果表明,GeLM能够有效地解决长时视频中的多跳问答问题。
🎯 应用场景
该研究成果可应用于智能助手、视频监控、教育视频分析等领域。例如,在智能助手中,可以帮助用户快速找到视频中问题的答案,提高用户体验。在视频监控中,可以自动分析视频内容,检测异常事件。在教育视频分析中,可以帮助学生更好地理解视频内容,提高学习效率。未来,该技术有望进一步发展,实现更复杂的多模态推理任务。
📄 摘要(原文)
This paper considers the problem of Multi-Hop Video Question Answering (MH-VidQA) in long-form egocentric videos. This task not only requires to answer visual questions, but also to localize multiple relevant time intervals within the video as visual evidences. We develop an automated pipeline to create multi-hop question-answering pairs with associated temporal evidence, enabling to construct a large-scale dataset for instruction-tuning. To monitor the progress of this new task, we further curate a high-quality benchmark, MultiHop-EgoQA, with careful manual verification and refinement. Experimental results reveal that existing multi-modal systems exhibit inadequate multi-hop grounding and reasoning abilities, resulting in unsatisfactory performance. We then propose a novel architecture, termed as Grounding Scattered Evidence with Large Language Model (GeLM), that enhances multi-modal large language models (MLLMs) by incorporating a grounding module to retrieve temporal evidence from videos using flexible grounding tokens. Trained on our visual instruction data, GeLM demonstrates improved multi-hop grounding and reasoning capabilities, setting a new baseline for this challenging task. Furthermore, when trained on third-person view videos, the same architecture also achieves state-of-the-art performance on the single-hop VidQA benchmark, ActivityNet-RTL, demonstrating its effectiveness.