Video-CCAM: Enhancing Video-Language Understanding with Causal Cross-Attention Masks for Short and Long Videos
作者: Jiajun Fei, Dian Li, Zhidong Deng, Zekun Wang, Gang Liu, Hui Wang
分类: cs.CV, cs.AI
发布日期: 2024-08-26
备注: 10 pages, 5 figures
🔗 代码/项目: GITHUB
💡 一句话要点
Video-CCAM:利用因果交叉注意力掩码增强视频语言理解能力,适用于短视频和长视频
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频语言理解 多模态学习 长视频理解 因果注意力 交叉注意力 视觉指令微调 大型语言模型 时序建模
📋 核心要点
- 现有Video-MLLM处理长视频时,面临视觉tokens过多导致的信息损失和推理速度下降问题。
- Video-CCAM在视觉编码器和LLM之间引入因果交叉注意力掩码(CCAMs),提升模型对时序信息的敏感性。
- 实验表明,Video-CCAM在多个视频理解基准测试中取得了领先的性能,尤其是在长视频任务上。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在需要跨领域知识的各种下游任务中展现出巨大的潜力。能够处理视频的MLLMs,即Video-MLLMs,在视频语言理解方面引起了广泛的兴趣。然而,视频,尤其是长视频,包含比图像更多的视觉tokens,这使得LLMs难以处理。现有的工作要么对视觉特征进行下采样,要么扩展LLM的上下文大小,这可能会导致高分辨率信息的丢失或降低推理速度。为了解决这些限制,我们在视觉编码器和大型语言模型(LLM)之间的中间投影器中应用交叉注意力层。由于朴素的交叉注意力机制对时间顺序不敏感,我们进一步在交叉注意力层中引入了因果交叉注意力掩码(CCAMs)。这个名为Video-CCAM的Video-MLLM以一种直接的两阶段方式进行训练:特征对齐和视觉指令微调。我们基于不同大小的LLMs(4B、9B和14B)开发了几个Video-CCAM模型。Video-CCAM被证明是一个强大的Video-MLLM,并在短视频和长视频中都表现出出色的性能。在MVBench和VideoChatGPT-QA等标准视频基准测试中,Video-CCAM表现出色(在MVBench中排名第1/2/3,在TGIF-QA中排名第1/2/3,在MSVD-QA、MSRVTT-QA和ActivityNet-QA中排名第2/3/4)。在包含长视频的基准测试中,Video-CCAM模型可以直接适应长视频理解,并且即使仅使用图像和16帧视频进行训练,仍然可以获得出色的分数。使用96帧(是训练帧数的6倍),Video-CCAM模型在VideoVista中分别排名第1/2/3,在MLVU中分别排名第1/2/4,在所有开源Video-MLLMs中。
🔬 方法详解
问题定义:论文旨在解决Video-MLLM在处理长视频时面临的挑战。现有方法,如视觉特征下采样和扩展LLM上下文窗口,要么损失高分辨率信息,要么降低推理速度。这些方法无法有效利用长视频中的时序信息,限制了模型在复杂视频理解任务中的表现。
核心思路:论文的核心思路是在视觉编码器和LLM之间引入带有因果掩码的交叉注意力机制。通过交叉注意力,模型可以学习视觉特征和文本特征之间的关联。而因果掩码则保证了模型在处理视频帧时,只能关注过去的信息,从而更好地捕捉视频中的时序关系。这种设计旨在提高模型对视频时序信息的利用率,同时避免信息泄露。
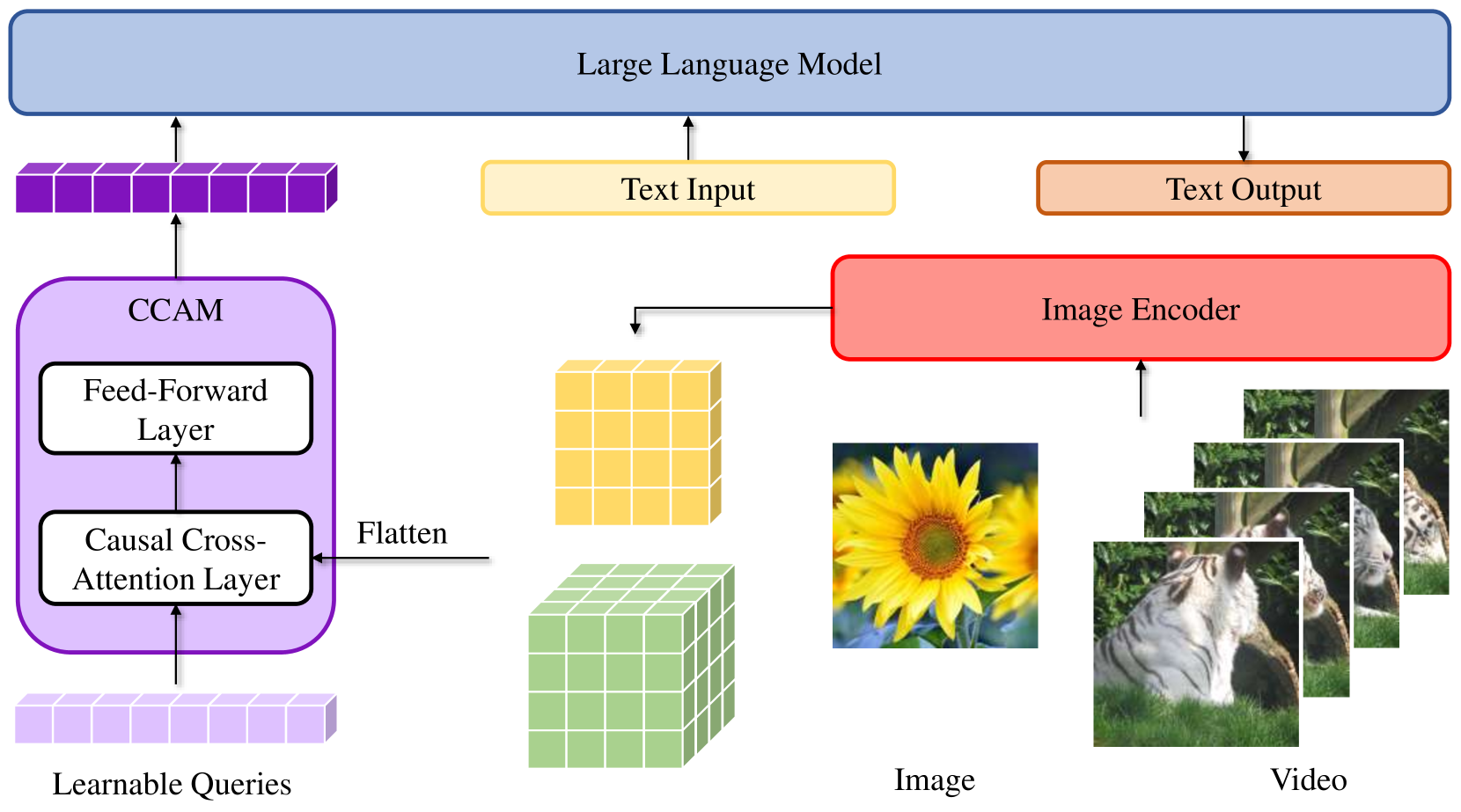
技术框架:Video-CCAM的整体框架包含三个主要模块:视觉编码器、中间投影器和大型语言模型(LLM)。视觉编码器负责提取视频帧的视觉特征。中间投影器包含交叉注意力层和因果交叉注意力掩码(CCAMs),用于将视觉特征与文本特征对齐。LLM则负责根据对齐后的特征生成文本输出。训练过程分为两个阶段:首先进行特征对齐,然后进行视觉指令微调。
关键创新:论文最关键的创新点是引入了因果交叉注意力掩码(CCAMs)。与传统的交叉注意力机制不同,CCAMs通过掩码机制限制了模型在处理视频帧时只能关注过去的信息,从而更好地捕捉视频中的时序关系。这种设计使得模型能够更有效地利用长视频中的时序信息,提高视频理解能力。
关键设计:论文使用了两阶段训练策略:特征对齐和视觉指令微调。在特征对齐阶段,使用对比学习损失来对齐视觉特征和文本特征。在视觉指令微调阶段,使用指令数据来微调整个模型,使其能够更好地完成各种视频理解任务。论文基于不同大小的LLMs(4B、9B和14B)开发了多个Video-CCAM模型,并针对不同的任务调整了训练参数。
🖼️ 关键图片


📊 实验亮点
Video-CCAM在多个视频理解基准测试中取得了显著的性能提升。在MVBench中排名第一,在TGIF-QA中排名第一,在MSVD-QA、MSRVTT-QA和ActivityNet-QA中排名第二。尤其值得一提的是,Video-CCAM在长视频基准测试VideoVista和MLVU中,分别排名第一和第二,超越了其他开源Video-MLLMs,证明了其在长视频理解方面的优势。
🎯 应用场景
Video-CCAM在视频理解领域具有广泛的应用前景,例如视频问答、视频摘要、视频编辑和视频内容推荐等。该模型能够有效处理长视频,使其在监控视频分析、电影理解和在线教育等领域具有实际应用价值。未来,Video-CCAM可以进一步扩展到其他多模态任务,例如视频生成和视频对话。
📄 摘要(原文)
Multi-modal large language models (MLLMs) have demonstrated considerable potential across various downstream tasks that require cross-domain knowledge. MLLMs capable of processing videos, known as Video-MLLMs, have attracted broad interest in video-language understanding. However, videos, especially long videos, contain more visual tokens than images, making them difficult for LLMs to process. Existing works either downsample visual features or extend the LLM context size, risking the loss of high-resolution information or slowing down inference speed. To address these limitations, we apply cross-attention layers in the intermediate projector between the visual encoder and the large language model (LLM). As the naive cross-attention mechanism is insensitive to temporal order, we further introduce causal cross-attention masks (CCAMs) within the cross-attention layers. This Video-MLLM, named Video-CCAM, is trained in a straightforward two-stage fashion: feature alignment and visual instruction tuning. We develop several Video-CCAM models based on LLMs of different sizes (4B, 9B, and 14B). Video-CCAM proves to be a robust Video-MLLM and shows outstanding performance from short videos to long ones. Among standard video benchmarks like MVBench and VideoChatGPT-QA, Video-CCAM shows outstanding performances (1st/2nd/3rd in MVBench and TGIF-QA, 2nd/3rd/4th in MSVD-QA, MSRVTT-QA, and ActivityNet-QA). In benchmarks encompassing long videos, Video-CCAM models can be directly adapted to long video understanding and still achieve exceptional scores despite being trained solely with images and 16-frame videos. Using 96 frames (6$\times$ the training number of frames), Video-CCAM models rank 1st/2nd/3rd in VideoVista and 1st/2nd/4th in MLVU among all open-source Video-MLLMs, respectively. The code is publicly available in \url{https://github.com/QQ-MM/Video-CCAM}.