ConVis: Contrastive Decoding with Hallucination Visualization for Mitigating Hallucinations in Multimodal Large Language Models
作者: Yeji Park, Deokyeong Lee, Junsuk Choe, Buru Chang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-08-25
备注: First two authors contributed equally. Source code is available at https://github.com/yejipark-m/ConVis
💡 一句话要点
ConVis:通过幻觉可视化对比解码缓解多模态大语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 幻觉抑制 对比学习 文本到图像生成 解码策略
📋 核心要点
- 多模态大语言模型容易产生与图像内容不符的幻觉,降低了模型的可靠性。
- ConVis利用文本到图像模型从幻觉文本重建图像,通过对比原始图像和重建图像的概率分布来抑制幻觉。
- ConVis无需额外训练数据或模型更新,在多个基准测试中有效降低了MLLM的幻觉。
📝 摘要(中文)
多模态大语言模型(MLLM)中生成的回复未能准确反映给定图像的幻觉问题,对其可靠性构成了重大挑战。为了解决这个问题,我们提出了一种新颖的、无需训练的对比解码方法ConVis。ConVis利用文本到图像(T2I)生成模型,从产生幻觉的caption中语义重建给定的图像。通过比较原始图像和重建图像产生的对比概率分布,ConVis使MLLM能够捕获视觉对比信号,从而惩罚幻觉生成。值得注意的是,该方法完全在解码过程中运行,无需额外的数据或模型更新。我们在五个流行的基准测试上进行了广泛的实验,结果表明ConVis有效地减少了各种MLLM中的幻觉,突出了其增强模型可靠性的潜力。
🔬 方法详解
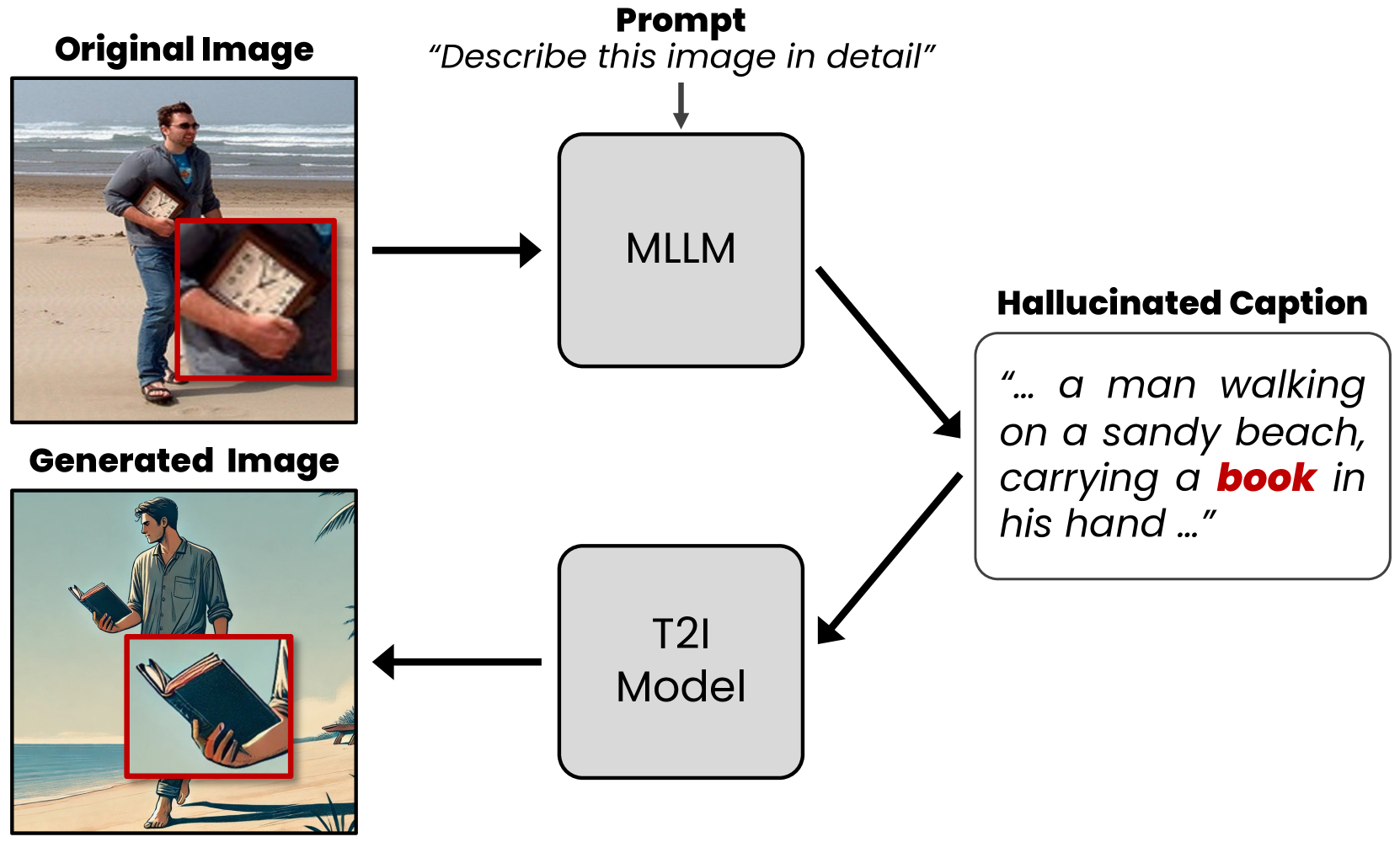
问题定义:论文旨在解决多模态大语言模型(MLLM)在生成图像描述时出现的幻觉问题,即生成的文本描述与图像内容不符。现有方法通常需要额外的训练数据或模型微调,成本较高且泛化能力有限。
核心思路:ConVis的核心思路是利用文本到图像(T2I)生成模型,将MLLM生成的文本描述反向生成图像,然后对比原始图像和重建图像的概率分布。如果生成的文本描述存在幻觉,那么重建的图像与原始图像的差异会比较大,通过对比这种差异可以有效抑制幻觉的产生。
技术框架:ConVis方法主要包含以下几个阶段:1) MLLM生成文本描述;2) 使用T2I模型从生成的文本描述重建图像;3) 计算原始图像和重建图像的概率分布;4) 对比两个概率分布,得到一个对比信号,用于调整MLLM的解码过程,抑制幻觉的产生。整个过程在解码阶段完成,无需额外的训练或微调。
关键创新:ConVis的关键创新在于利用T2I模型进行幻觉可视化,并通过对比原始图像和重建图像的概率分布来指导解码过程。这种方法无需额外的训练数据或模型微调,可以直接应用于现有的MLLM,具有很强的通用性和实用性。与现有方法相比,ConVis更加高效且易于部署。
关键设计:ConVis的关键设计包括:1) 选择合适的T2I模型,确保重建图像的质量;2) 设计合适的概率分布对比方法,能够有效捕捉原始图像和重建图像之间的差异;3) 设计合适的对比信号融合策略,将对比信号有效地融入到MLLM的解码过程中。具体的参数设置和损失函数细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
ConVis在五个流行的基准测试中进行了广泛的实验,结果表明ConVis有效地减少了各种MLLM中的幻觉。具体性能数据和提升幅度在摘要中没有给出,属于未知信息。但实验结果表明,ConVis在不进行额外训练的情况下,显著提升了MLLM的可靠性。
🎯 应用场景
ConVis方法可以广泛应用于各种需要可靠图像描述的多模态应用场景,例如:视觉问答、图像字幕、机器人导航等。通过降低MLLM的幻觉,可以提高这些应用的准确性和可靠性,从而提升用户体验和安全性。该研究对于推动多模态人工智能的发展具有重要意义。
📄 摘要(原文)
Hallucinations in Multimodal Large Language Models (MLLMs) where generated responses fail to accurately reflect the given image pose a significant challenge to their reliability. To address this, we introduce ConVis, a novel training-free contrastive decoding method. ConVis leverages a text-to-image (T2I) generation model to semantically reconstruct the given image from hallucinated captions. By comparing the contrasting probability distributions produced by the original and reconstructed images, ConVis enables MLLMs to capture visual contrastive signals that penalize hallucination generation. Notably, this method operates purely within the decoding process, eliminating the need for additional data or model updates. Our extensive experiments on five popular benchmarks demonstrate that ConVis effectively reduces hallucinations across various MLLMs, highlighting its potential to enhance model reliability.