Draw Like an Artist: Complex Scene Generation with Diffusion Model via Composition, Painting, and Retouching
作者: Minghao Liu, Le Zhang, Yingjie Tian, Xiaochao Qu, Luoqi Liu, Ting Liu
分类: cs.CV, cs.LG
发布日期: 2024-08-25
💡 一句话要点
CxD:通过组合、绘制和修饰,利用扩散模型生成复杂场景图像
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 复杂场景生成 文本到图像 大型语言模型 注意力机制
📋 核心要点
- 现有文本到图像扩散模型在复杂场景生成方面存在不足,缺乏对“复杂场景”的明确定义和有效处理方法。
- CxD框架模仿艺术家绘画过程,将复杂场景生成分解为组合、绘制和修饰三个阶段,利用LLM和注意力机制实现。
- 实验结果表明,CxD框架在生成高质量、语义一致和视觉多样化的复杂场景图像方面优于现有技术水平。
📝 摘要(中文)
本文针对文本到图像扩散模型在复杂场景生成方面探索不足的问题,首先提出了复杂场景的精确定义,并基于此定义引入了一组复杂分解准则(CDC)。受艺术家绘画过程的启发,本文提出了一种名为Complex Diffusion (CxD)的无训练扩散框架,该框架将过程分为三个阶段:组合、绘制和修饰。该方法利用大型语言模型(LLM)强大的思维链能力,基于CDC分解复杂提示,并管理组合和布局。然后,开发了一种注意力调制方法,引导简单提示到特定区域以完成复杂场景的绘制。最后,将LLM的详细输出注入到修饰模型中,以增强图像细节,从而实现修饰阶段。大量实验表明,该方法优于以往的SOTA方法,显著提高了复杂场景高质量、语义一致和视觉多样图像的生成能力,即使是复杂的提示。
🔬 方法详解
问题定义:现有文本到图像的扩散模型在生成复杂场景时面临挑战。主要痛点在于难以理解和分解复杂的文本提示,导致生成的图像在语义一致性、细节丰富度和整体布局上表现不佳。缺乏对复杂场景的明确定义和有效的分解策略是关键问题。
核心思路:论文的核心思路是模仿艺术家的绘画过程,将复杂场景的生成分解为三个可控的阶段:组合(Composition)、绘制(Painting)和修饰(Retouching)。通过这种分解,将复杂问题简化为多个子问题,并针对每个子问题设计专门的解决方案。
技术框架:CxD框架包含三个主要阶段: 1. 组合阶段:利用大型语言模型(LLM)的链式思考能力,根据提出的复杂分解准则(CDC)将复杂的文本提示分解为多个简单的提示,并确定场景中各个元素的布局。 2. 绘制阶段:使用注意力调制方法,将简单的提示引导到图像的特定区域,从而完成复杂场景的绘制。这种方法允许对图像的不同区域进行精细控制。 3. 修饰阶段:将LLM生成的详细描述注入到修饰模型中,以增强图像的细节和真实感。
关键创新:该方法最重要的创新点在于将复杂场景生成问题分解为三个阶段,并针对每个阶段设计了专门的解决方案。利用LLM进行场景分解和布局规划,以及使用注意力调制方法进行区域控制,是该方法的核心创新。与现有方法相比,CxD框架能够更好地理解和处理复杂的文本提示,生成更符合语义、细节更丰富的图像。
关键设计: * 复杂分解准则(CDC):用于指导LLM分解复杂提示,确保分解后的提示能够准确描述场景中的各个元素。 * 注意力调制方法:通过调整交叉注意力权重,将简单的提示引导到图像的特定区域。具体实现细节未知。 * 修饰模型:用于增强图像细节,具体模型结构未知。LLM的详细输出作为修饰模型的输入,用于指导细节增强。
🖼️ 关键图片

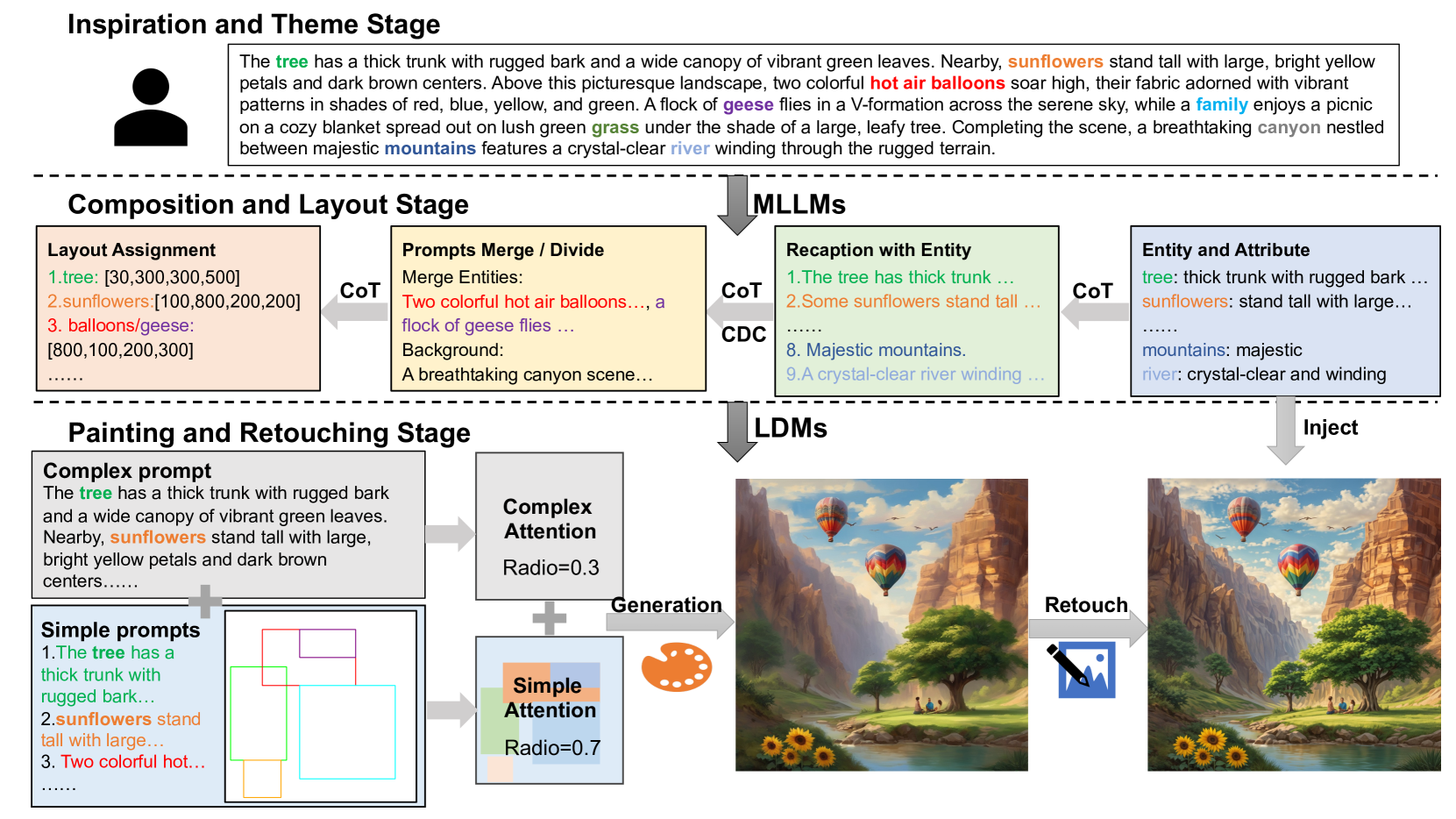
📊 实验亮点
实验结果表明,CxD框架在生成复杂场景图像方面显著优于现有SOTA方法。通过人工评估,CxD生成的图像在语义一致性、细节丰富度和整体视觉效果方面均有明显提升。具体性能数据未知,但论文强调了在处理复杂提示时,CxD能够生成更高质量、更符合语义的图像。
🎯 应用场景
该研究成果可应用于游戏开发、电影制作、广告设计等领域,能够根据复杂的文本描述自动生成高质量的场景图像,提高内容创作效率,降低创作成本。未来,该技术有望进一步发展,实现更精细的场景控制和更逼真的图像生成,为虚拟现实、增强现实等领域提供更强大的内容生成能力。
📄 摘要(原文)
Recent advances in text-to-image diffusion models have demonstrated impressive capabilities in image quality. However, complex scene generation remains relatively unexplored, and even the definition of `complex scene' itself remains unclear. In this paper, we address this gap by providing a precise definition of complex scenes and introducing a set of Complex Decomposition Criteria (CDC) based on this definition. Inspired by the artists painting process, we propose a training-free diffusion framework called Complex Diffusion (CxD), which divides the process into three stages: composition, painting, and retouching. Our method leverages the powerful chain-of-thought capabilities of large language models (LLMs) to decompose complex prompts based on CDC and to manage composition and layout. We then develop an attention modulation method that guides simple prompts to specific regions to complete the complex scene painting. Finally, we inject the detailed output of the LLM into a retouching model to enhance the image details, thus implementing the retouching stage. Extensive experiments demonstrate that our method outperforms previous SOTA approaches, significantly improving the generation of high-quality, semantically consistent, and visually diverse images for complex scenes, even with intricate prompts.