SceneDreamer360: Text-Driven 3D-Consistent Scene Generation with Panoramic Gaussian Splatting
作者: Wenrui Li, Fucheng Cai, Yapeng Mi, Zhe Yang, Wangmeng Zuo, Xingtao Wang, Xiaopeng Fan
分类: cs.CV, cs.MM
发布日期: 2024-08-25 (更新: 2024-10-14)
🔗 代码/项目: GITHUB
💡 一句话要点
SceneDreamer360:提出基于全景高斯溅射的文本驱动3D一致场景生成方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 文本驱动生成 3D场景生成 全景图像 高斯溅射 多视角一致性
📋 核心要点
- 现有文本驱动的3D场景生成方法在多视角一致性方面存在挑战,拼接的单视图图像容易导致空间不一致。
- SceneDreamer360利用全景图像生成模型作为先验,并结合3D高斯溅射,确保生成3D场景的多视角一致性。
- 通过增强全景图像生成质量和优化点云初始化,SceneDreamer360在3D场景质量和空间一致性上优于现有方法。
📝 摘要(中文)
本文提出了一种新颖的文本驱动的3D一致场景生成模型:SceneDreamer360。现有方法通常使用生成模型生成单视图图像,然后在3D空间中将它们拼接在一起,导致空间不一致和不真实感。为了解决这个问题,SceneDreamer360利用文本驱动的全景图像生成模型作为3D场景生成的先验,并采用3D高斯溅射(3DGS)来确保多视图全景图像之间的一致性。具体来说,SceneDreamer360通过三阶段全景增强来增强微调的Panfusion生成器,从而生成高分辨率、细节丰富的全景图像。在3D场景构建过程中,使用了一种新颖的点云融合初始化方法,从而产生更高质量和空间一致的点云。大量实验表明,与其他方法相比,SceneDreamer360及其全景图像生成和3DGS可以从任何文本提示生成更高质量、空间一致且视觉上吸引人的3D场景。
🔬 方法详解
问题定义:现有文本驱动的3D场景生成方法主要通过生成单视图图像然后拼接的方式构建3D场景,这种方式忽略了不同视角之间的关联性,导致生成的3D场景在空间上不一致,缺乏真实感。现有方法难以生成高质量、空间一致的全景3D场景。
核心思路:SceneDreamer360的核心思路是利用文本驱动的全景图像生成模型作为3D场景生成的先验知识,并结合3D高斯溅射(3DGS)技术,从而在生成过程中保证多视角的一致性。通过高质量的全景图像生成和3DGS的优化,可以有效地解决空间不一致的问题。
技术框架:SceneDreamer360主要包含两个阶段:1) 全景图像生成阶段:使用增强的Panfusion生成器生成高分辨率、细节丰富的全景图像。该阶段包含一个三阶段全景增强过程。2) 3D场景构建阶段:利用生成的全景图像初始化3D高斯溅射,并通过优化3D高斯参数来构建最终的3D场景。该阶段使用了一种新颖的点云融合初始化方法。
关键创新:SceneDreamer360的关键创新在于:1) 将文本驱动的全景图像生成作为3D场景生成的先验,从而避免了单视图生成带来的不一致性问题。2) 提出了一种新颖的点云融合初始化方法,能够生成更高质量和空间一致的点云。3) 结合全景图像生成和3DGS,实现了高质量、空间一致的文本驱动3D场景生成。
关键设计:在全景图像生成阶段,采用了三阶段全景增强策略,具体细节未知。在3D场景构建阶段,使用了一种新颖的点云融合初始化方法,具体实现细节未知。损失函数方面,可能使用了用于3DGS优化的标准损失函数,例如D-L1损失和SSIM损失。具体的网络结构和参数设置在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片

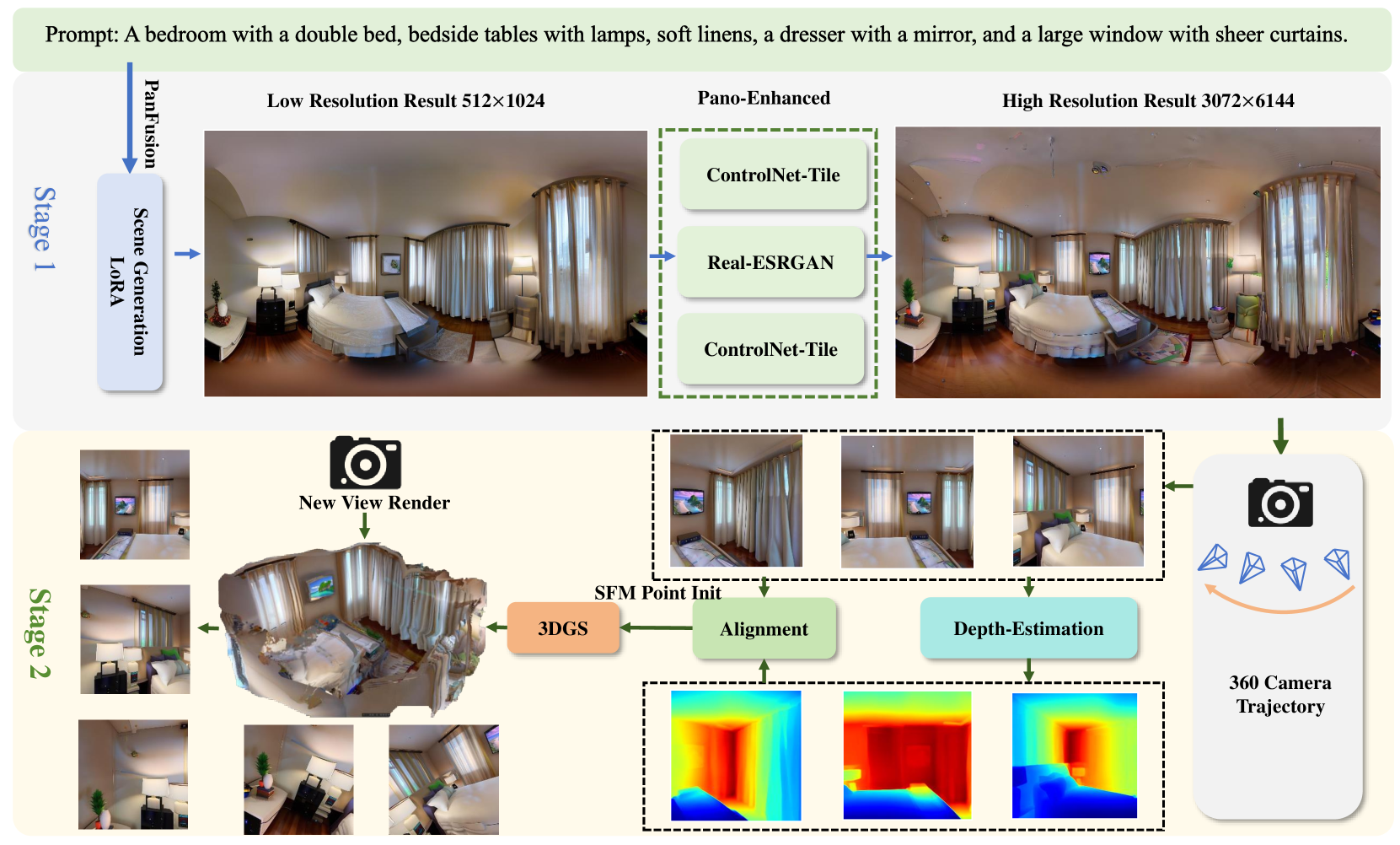

📊 实验亮点
SceneDreamer360通过全景图像生成和3DGS的结合,显著提高了文本驱动3D场景生成的质量和空间一致性。实验结果表明,SceneDreamer360生成的3D场景在视觉效果和空间一致性方面优于其他方法。具体的性能数据和提升幅度在摘要中未给出,需要在论文中查找。
🎯 应用场景
SceneDreamer360在虚拟现实、增强现实、游戏开发、电影制作等领域具有广泛的应用前景。它可以根据文本描述快速生成高质量、空间一致的3D场景,从而降低内容创作的成本和时间。未来,该技术可以应用于个性化场景定制、虚拟旅游、建筑设计等领域,具有重要的实际价值和商业潜力。
📄 摘要(原文)
Text-driven 3D scene generation has seen significant advancements recently. However, most existing methods generate single-view images using generative models and then stitch them together in 3D space. This independent generation for each view often results in spatial inconsistency and implausibility in the 3D scenes. To address this challenge, we proposed a novel text-driven 3D-consistent scene generation model: SceneDreamer360. Our proposed method leverages a text-driven panoramic image generation model as a prior for 3D scene generation and employs 3D Gaussian Splatting (3DGS) to ensure consistency across multi-view panoramic images. Specifically, SceneDreamer360 enhances the fine-tuned Panfusion generator with a three-stage panoramic enhancement, enabling the generation of high-resolution, detail-rich panoramic images. During the 3D scene construction, a novel point cloud fusion initialization method is used, producing higher quality and spatially consistent point clouds. Our extensive experiments demonstrate that compared to other methods, SceneDreamer360 with its panoramic image generation and 3DGS can produce higher quality, spatially consistent, and visually appealing 3D scenes from any text prompt. Our codes are available at \url{https://github.com/liwrui/SceneDreamer360}.