GRAB: A Challenging GRaph Analysis Benchmark for Large Multimodal Models
作者: Jonathan Roberts, Kai Han, Samuel Albanie
分类: cs.CV
发布日期: 2024-08-21 (更新: 2025-10-16)
备注: Accepted at ICCV 2025
💡 一句话要点
GRAB:一个用于评估大型多模态模型图分析能力的高难度基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图分析 大型多模态模型 基准测试 合成数据 模型评估
📋 核心要点
- 现有LMMs评估基准已无法充分测试其图分析能力,缺乏足够难度。
- 提出GRAB基准,包含合成的、高质量的图分析问题,涵盖多种任务和属性。
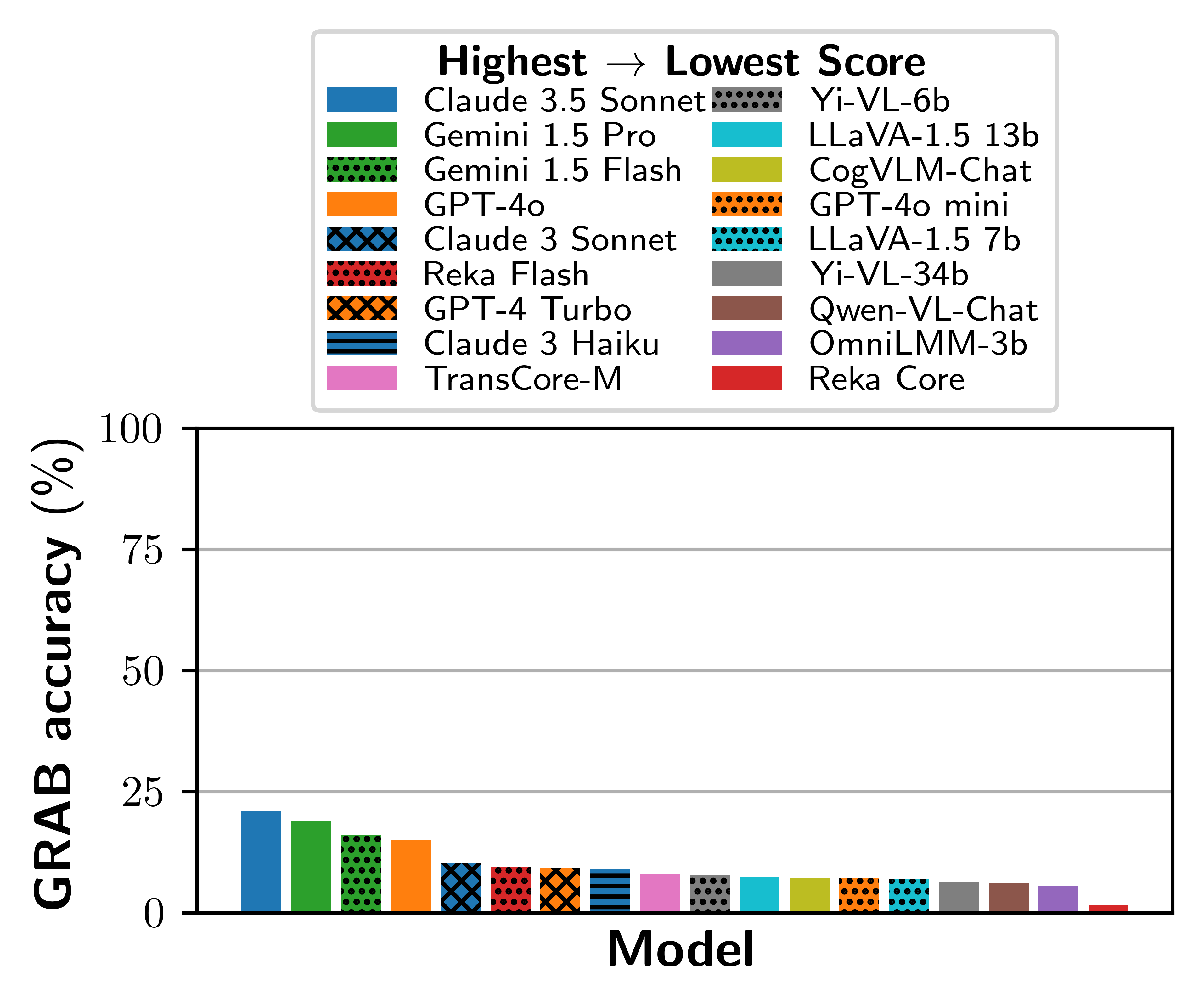
- 实验表明GRAB对现有LMMs构成挑战,最高性能模型得分仅为21.0%。
📝 摘要(中文)
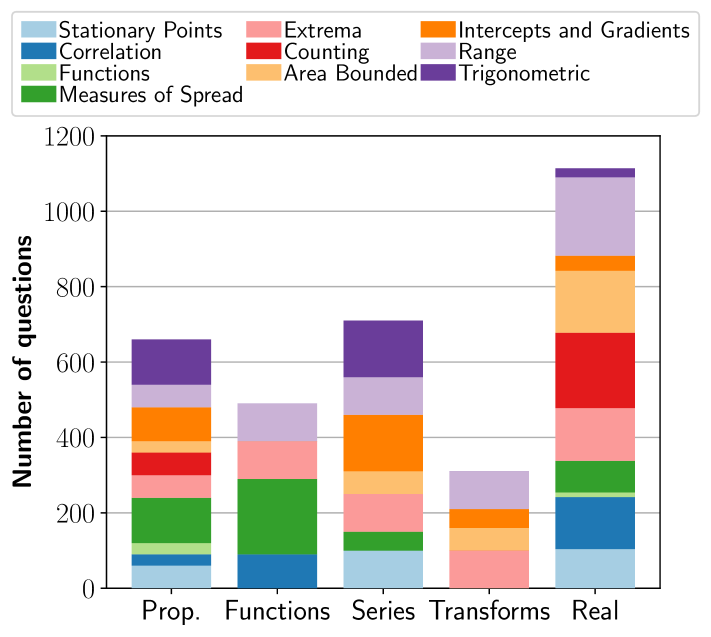
大型多模态模型(LMMs)在许多视觉任务中表现出卓越的能力。虽然已经存在许多用于评估模型性能的知名基准,但它们越来越难以满足需求。因此,迫切需要新一代的基准,以挑战下一代LMMs。图分析是LMMs展现潜力的一个领域,特别是分析师在解释图表时通常执行的任务,例如估计函数和数据序列的均值、截距或相关性。本文介绍GRAB,一个适用于当前和未来前沿LMMs的图分析基准。我们的基准主要是合成的,确保高质量、无噪声的问题。GRAB包含3284个问题,涵盖五个任务和23个图属性。我们在GRAB上评估了20个LMMs,发现它是一个具有挑战性的基准,性能最高的模型仅达到21.0%的分数。最后,我们进行了各种消融实验,以调查模型在哪些方面成功,哪些方面遇到困难。我们发布GRAB和一个轻量级的GRAB-Lite,以鼓励在这个重要且不断增长的领域取得进展。
🔬 方法详解
问题定义:论文旨在解决现有大型多模态模型在图分析任务中缺乏足够挑战性评估基准的问题。现有的基准测试无法充分评估LMMs在理解和推理图表数据方面的能力,尤其是在估计均值、截距和相关性等复杂属性时。这阻碍了LMMs在图分析领域的进一步发展和应用。
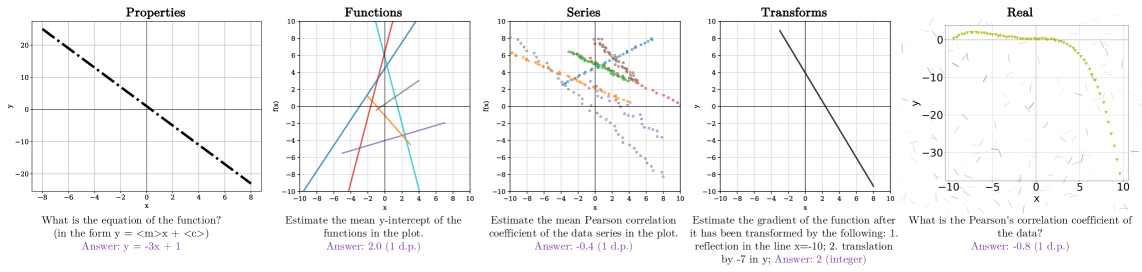
核心思路:论文的核心思路是构建一个合成的、高质量的图分析基准,称为GRAB。通过生成具有明确定义的属性和关系的图表,可以创建无噪声、可控的测试用例,从而更准确地评估LMMs的图分析能力。这种方法避免了真实世界数据的噪声和不确定性,使研究人员能够专注于评估模型的核心推理能力。
技术框架:GRAB基准包含以下主要组成部分:1)图表生成器:用于生成具有各种属性和关系的合成图表。2)问题生成器:根据生成的图表,自动生成关于图表属性的问题。3)评估指标:用于评估LMMs在回答问题方面的准确性和效率。4)GRAB-Lite:一个轻量级的版本,方便快速评估。整个流程旨在提供一个全面、可控的图分析评估平台。
关键创新:GRAB的关键创新在于其合成数据的生成方式和问题设计的针对性。与依赖真实世界数据的基准不同,GRAB通过程序化生成图表,确保了数据的质量和可控性。此外,GRAB的问题设计侧重于评估LMMs对图表属性的理解和推理能力,例如估计均值、截距和相关性等。这种设计使得GRAB能够更有效地评估LMMs在图分析方面的能力。
关键设计:GRAB包含五个任务和23个图属性,涵盖了常见的图分析场景。问题类型包括选择题和开放式问题。为了确保数据的多样性,图表生成器使用了多种参数设置,例如函数类型、噪声水平和数据点数量。评估指标包括准确率和F1分数。GRAB-Lite是GRAB的一个简化版本,包含更少的问题和图表,方便快速评估。
🖼️ 关键图片
📊 实验亮点
在GRAB基准上,20个LMMs的评估结果表明,现有模型在图分析方面仍面临挑战,最高性能模型得分仅为21.0%。消融实验揭示了模型在不同任务和属性上的表现差异,为未来的模型改进提供了方向。GRAB和GRAB-Lite的发布将促进图分析领域LMMs的研究和发展。
🎯 应用场景
GRAB基准的潜在应用领域包括金融分析、科学研究、社交网络分析等。通过提高LMMs在图分析方面的能力,可以帮助分析师更有效地理解和利用图表数据,从而做出更明智的决策。未来,GRAB可以扩展到更复杂的图分析任务,例如图神经网络的评估和优化。
📄 摘要(原文)
Large multimodal models (LMMs) have exhibited proficiencies across many visual tasks. Although numerous well-known benchmarks exist to evaluate model performance, they increasingly have insufficient headroom. As such, there is a pressing need for a new generation of benchmarks challenging enough for the next generation of LMMs. One area that LMMs show potential is graph analysis, specifically, the tasks an analyst might typically perform when interpreting figures such as estimating the mean, intercepts or correlations of functions and data series. In this work, we introduce GRAB, a graph analysis benchmark, fit for current and future frontier LMMs. Our benchmark is predominantly synthetic, ensuring high-quality, noise-free questions. GRAB is comprised of 3284 questions, covering five tasks and 23 graph properties. We evaluate 20 LMMs on GRAB, finding it to be a challenging benchmark, with the highest performing model attaining a score of just 21.0%. Finally, we conduct various ablations to investigate where the models succeed and struggle. We release GRAB and a lightweight GRAB-Lite to encourage progress in this important, growing domain.