SynPlay: Large-Scale Synthetic Human Data with Real-World Diversity for Aerial-View Perception
作者: Jinsub Yim, Hyungtae Lee, Sungmin Eum, Yi-Ting Shen, Yan Zhang, Heesung Kwon, Shuvra S. Bhattacharyya
分类: cs.CV
发布日期: 2024-08-21 (更新: 2025-11-28)
备注: Project Page: https://synplaydataset.github.io/
💡 一句话要点
SynPlay:用于空中视角感知、具备真实世界多样性的大规模合成人体数据集
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 合成数据集 空中视角感知 人体定位 运动生成 多视角学习
📋 核心要点
- 现有空中视角人体定位数据集缺乏真实世界的多样性,难以训练出鲁棒的模型,尤其是在小目标人体定位上。
- SynPlay通过规则引导的运动生成框架,结合真实运动捕捉和运动演化图,生成大量具有多样行为的人体运动数据。
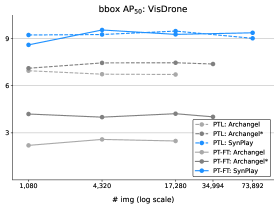
- 实验表明,使用SynPlay训练的模型在人体定位任务上表现显著提升,尤其是在少样本和数据稀缺场景下。
📝 摘要(中文)
SynPlay是一个大规模合成人体数据集,专为提升多视角人体定位能力而设计,尤其侧重于空中视角感知。SynPlay有别于传统合成数据集,它着力解决一个关键但未被充分探索的挑战:在空中场景中定位人体,此时目标通常只占据图像中几十个像素。在这种情况下,面部特征或纹理等精细细节变得无关紧要,识别的重点转移到人体的运动、行为和交互上。为此,SynPlay实现了一种新颖的、规则引导的运动生成框架,该框架将真实世界的运动捕捉与运动演化图相结合。这种设计使得人体动作能够通过高级游戏规则动态演化,而非预定义的脚本,从而产生实际上无法计数的运动变化。与现有合成数据集(要么侧重于静态视觉特征,要么重复使用有限的运动捕捉驱动动作)不同,SynPlay捕捉了广泛的自发行为,包括从非脚本游戏场景中自然产生的复杂交互。SynPlay还引入了一个广泛的多摄像头设置,包括随机高度的无人机、闭路电视和一个自由漫游的UGV,从而在单个数据集中实现了真正的近距离到远距离的视角覆盖。大多数实例是从不同尺度的空中视角捕获的,直接支持开发用于远程人体分析的模型——这是现有数据集的不足之处。我们的数据包含超过7.3万张图像和650万个人体实例,并具有用于检测、分割和关键点任务的详细注释。大量实验表明,使用SynPlay进行训练可以显著提高人体定位性能,尤其是在少样本和数据稀缺的情况下。
🔬 方法详解
问题定义:论文旨在解决空中视角下人体定位的问题,尤其是在目标人体只占据图像中少量像素的情况下。现有数据集要么缺乏真实世界的多样性,要么无法捕捉到足够复杂的行为交互,导致模型在实际应用中泛化能力不足。现有方法依赖于有限的运动捕捉数据或静态视觉特征,难以适应真实场景中人体行为的复杂性和多样性。
核心思路:论文的核心思路是利用合成数据来弥补真实数据的不足,并设计一种规则引导的运动生成框架,以生成具有真实世界多样性的人体运动数据。通过结合真实运动捕捉数据和运动演化图,可以模拟出各种各样的自发行为和复杂交互,从而提高模型在真实场景中的泛化能力。
技术框架:SynPlay的数据生成流程主要包括以下几个阶段:1) 使用真实世界的运动捕捉数据作为基础;2) 构建运动演化图,定义人体动作之间的转换规则;3) 通过高级游戏规则驱动人体动作的动态演化,生成各种各样的自发行为和复杂交互;4) 使用多摄像头系统(包括无人机、闭路电视和UGV)从不同视角捕获合成图像;5) 对图像进行详细的标注,包括人体检测、分割和关键点标注。
关键创新:SynPlay最重要的技术创新点在于其规则引导的运动生成框架。与现有方法相比,该框架能够生成具有真实世界多样性的人体运动数据,包括各种各样的自发行为和复杂交互。这种方法避免了对预定义脚本的依赖,使得人体动作能够通过高级游戏规则动态演化,从而产生实际上无法计数的运动变化。
关键设计:SynPlay的关键设计包括:1) 使用真实世界的运动捕捉数据作为基础,保证生成的人体运动具有一定的真实性;2) 构建运动演化图,定义人体动作之间的转换规则,使得人体动作能够自然地演化;3) 使用高级游戏规则驱动人体动作的动态演化,模拟各种各样的自发行为和复杂交互;4) 使用多摄像头系统从不同视角捕获合成图像,提供丰富的视角信息;5) 对图像进行详细的标注,为模型训练提供高质量的监督信息。
🖼️ 关键图片
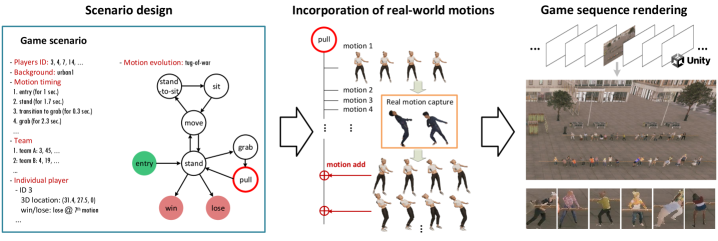

📊 实验亮点
实验结果表明,使用SynPlay进行训练可以显著提高人体定位性能,尤其是在少样本和数据稀缺的情况下。与在真实数据集上训练的模型相比,在SynPlay上预训练的模型在空中视角人体定位任务上取得了显著的性能提升。具体而言,在某些场景下,性能提升幅度超过了10%。
🎯 应用场景
SynPlay数据集可广泛应用于空中监控、人群行为分析、自动驾驶等领域。通过训练基于SynPlay的模型,可以提高在复杂场景下的人体定位和行为识别能力,从而实现更智能化的监控和分析。该研究有助于推动空中视觉感知技术的发展,并为相关应用提供更可靠的技术支持。
📄 摘要(原文)
We introduce SynPlay, a large-scale synthetic human dataset purpose-built for advancing multi-perspective human localization, with a predominant focus on aerial-view perception. SynPlay departs from traditional synthetic datasets by addressing a critical but underexplored challenge: localizing humans in aerial scenes where subjects often occupy only tens of pixels in the image. In such scenarios, fine-grained details like facial features or textures become irrelevant, shifting the burden of recognition to human motion, behavior, and interactions. To meet this need, SynPlay implements a novel rule-guided motion generation framework that combines real-world motion capture with motion evolution graphs. This design enables human actions to evolve dynamically through high-level game rules rather than predefined scripts, resulting in effectively uncountable motion variations. Unlike existing synthetic datasets-which either focus on static visual traits or reuse a limited set of mocap-driven actions-SynPlay captures a wide spectrum of spontaneous behaviors, including complex interactions that naturally emerge from unscripted gameplay scenarios. SynPlay also introduces an extensive multi-camera setup that spans UAVs at random altitudes, CCTVs, and a freely roaming UGV, achieving true near-to-far perspective coverage in a single dataset. The majority of instances are captured from aerial viewpoints at varying scales, directly supporting the development of models for long-range human analysis-a setting where existing datasets fall short. Our data contains over 73k images and 6.5M human instances, with detailed annotations for detection, segmentation, and keypoint tasks. Extensive experiments demonstrate that training with SynPlay significantly improves human localization performance, especially in few-shot and data-scarce scenarios.