SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs
作者: Yuanyang Yin, Yaqi Zhao, Yajie Zhang, Yuanxing Zhang, Ke Lin, Jiahao Wang, Xin Tao, Pengfei Wan, Wentao Zhang, Feng Zhao
分类: cs.CV
发布日期: 2024-08-21 (更新: 2025-09-05)
💡 一句话要点
提出SEA:用于MLLM中Token级视觉-文本对齐的监督嵌入对齐方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉-文本对齐 监督学习 嵌入对齐 大型语言模型 跨模态理解 token级别监督
📋 核心要点
- 现有MLLM依赖图像级监督的适配器进行视觉-文本对齐,导致模态间对齐不佳,限制了LLM对视觉特征的理解和推理能力。
- SEA方法提出token级别的监督嵌入对齐,在预训练阶段实现更精确的视觉-文本对齐,提升跨模态理解能力。
- 实验表明,SEA在各种模型尺寸上均能提升性能,尤其对小模型提升显著,例如Gemma-2B平均性能提升7.61%。
📝 摘要(中文)
多模态大型语言模型(MLLM)通过整合视觉和文本输入展示了卓越的能力,但模态对齐仍然是最具挑战性的方面之一。目前的MLLM通常依赖于简单的适配器架构和预训练方法来桥接视觉编码器和大型语言模型(LLM),并以图像级监督为指导。我们发现这种范式通常会导致模态之间次优的对齐,显著限制了LLM正确解释和推理视觉特征的能力,特别是对于较小的语言模型。这种限制降低了整体性能,尤其是在容量限制更为明显且适应能力有限的较小模型中。为了解决这个根本限制,我们提出了监督嵌入对齐(SEA),一种token级别的监督对齐方法,可以在预训练期间实现更精确的视觉-文本对齐。SEA引入了最小的计算开销,同时保留了语言能力,并显著提高了跨模态理解。我们的综合分析揭示了适配器在多模态集成中的关键作用,广泛的实验表明,SEA始终提高各种模型尺寸的性能,较小的模型受益最大(Gemma-2B的平均性能提升为7.61%)。这项工作为未来多模态系统开发更有效的对齐策略奠定了基础。
🔬 方法详解
问题定义:现有MLLM在视觉和文本模态对齐方面存在不足,主要体现在图像级别的监督信号不足以指导token级别的细粒度对齐。这导致LLM难以充分理解和利用视觉信息,尤其是在模型参数量较小的情况下,适配器的能力有限,问题更加突出。现有方法的痛点在于模态融合不够精细,视觉信息利用率不高。
核心思路:SEA的核心思路是在预训练阶段引入token级别的监督信号,直接对齐视觉和文本的嵌入表示。通过这种方式,模型能够学习到更精确的视觉-文本对应关系,从而提高跨模态理解能力。这样设计的目的是弥补图像级别监督的不足,提升模型对细粒度视觉信息的感知能力。
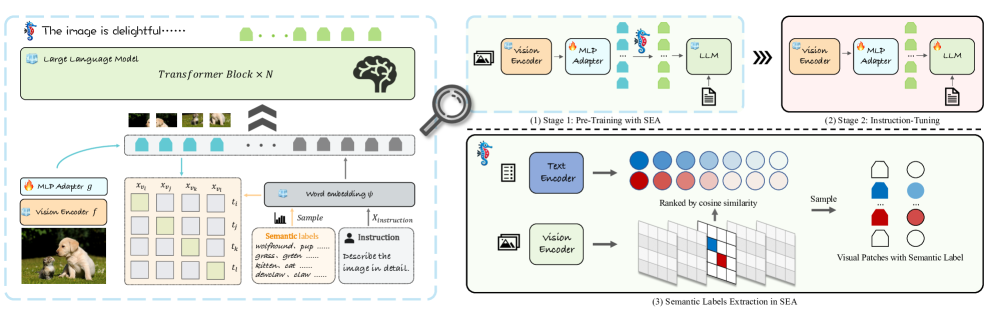
技术框架:SEA方法主要包含以下几个阶段:1) 使用视觉编码器提取图像的token级别特征;2) 使用文本编码器提取文本的token级别特征;3) 通过适配器将视觉特征映射到文本特征空间;4) 使用token级别的监督信号,对齐视觉和文本的嵌入表示。整体流程是在预训练阶段,通过最小化视觉和文本嵌入之间的距离,来学习更有效的跨模态表示。
关键创新:SEA最重要的技术创新点在于引入了token级别的监督对齐。与传统的图像级别监督相比,token级别监督能够提供更细粒度的对齐信息,从而使模型能够学习到更精确的视觉-文本对应关系。这种方法能够有效提升模型对视觉信息的利用率,尤其是在小模型上效果显著。SEA方法在计算开销增加不多的情况下,显著提升了跨模态理解能力。
关键设计:SEA的关键设计包括:1) 使用对比学习损失函数来对齐视觉和文本的嵌入表示,例如InfoNCE损失;2) 选择合适的适配器结构,例如线性层或Transformer层,用于将视觉特征映射到文本特征空间;3) 调整token级别监督信号的强度,以平衡语言建模和跨模态对齐之间的关系。具体参数设置需要根据不同的数据集和模型进行调整。
🖼️ 关键图片
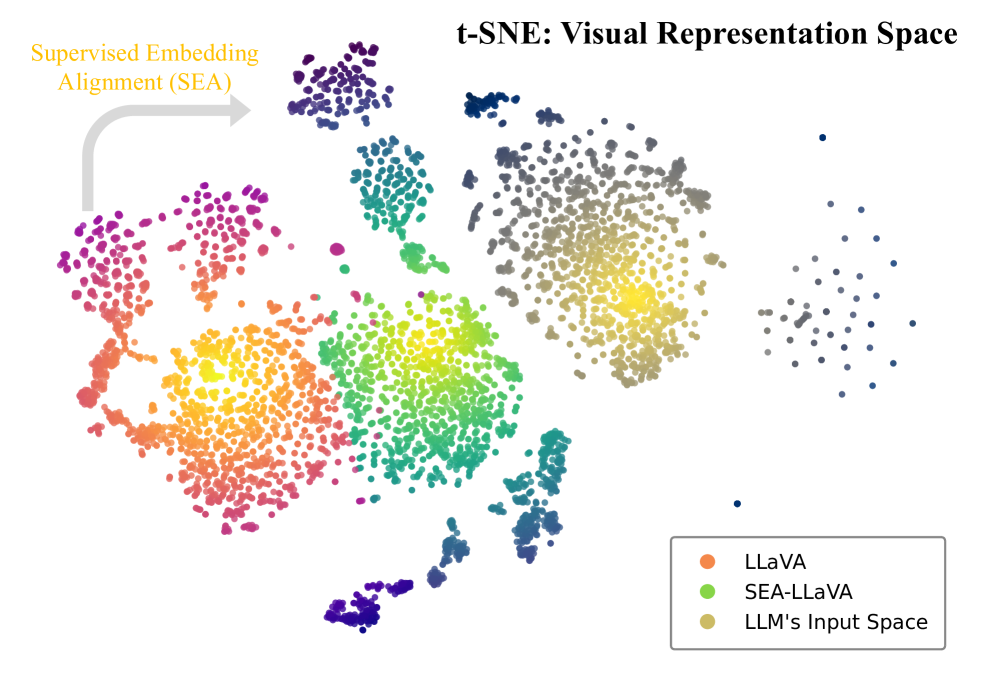

📊 实验亮点
SEA方法在多个基准测试中取得了显著的性能提升。例如,在Gemma-2B模型上,SEA实现了平均7.61%的性能提升。实验结果表明,SEA方法能够有效提升MLLM的跨模态理解能力,尤其是在小模型上效果显著。与现有方法相比,SEA在计算开销增加不多的情况下,实现了更高的性能。
🎯 应用场景
SEA方法可应用于各种需要视觉-文本融合的多模态任务,例如图像描述、视觉问答、视觉推理等。该方法能够提升MLLM对视觉信息的理解和利用能力,从而提高这些任务的性能。此外,SEA方法在小模型上的有效性,使其在资源受限的场景下具有重要的应用价值,例如移动设备上的智能助手。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities by integrating visual and textual inputs, yet modality alignment remains one of the most challenging aspects. Current MLLMs typically rely on simple adapter architectures and pretraining approaches to bridge vision encoders with large language models (LLM), guided by image-level supervision. We identify this paradigm often leads to suboptimal alignment between modalities, significantly constraining the LLM's ability to properly interpret and reason with visual features particularly for smaller language models. This limitation degrades overall performance-particularly for smaller language models where capacity constraints are more pronounced and adaptation capabilities are limited. To address this fundamental limitation, we propose Supervised Embedding Alignment (SEA), a token-level supervision alignment method that enables more precise visual-text alignment during pretraining. SEA introduces minimal computational overhead while preserving language capabilities and substantially improving cross-modal understanding. Our comprehensive analyses reveal critical insights into the adapter's role in multimodal integration, and extensive experiments demonstrate that SEA consistently improves performance across various model sizes, with smaller models benefiting the most (average performance gain of 7.61% for Gemma-2B). This work establishes a foundation for developing more effective alignment strategies for future multimodal systems.