OE3DIS: Open-Ended 3D Point Cloud Instance Segmentation
作者: Phuc D. A. Nguyen, Minh Luu, Anh Tran, Cuong Pham, Khoi Nguyen
分类: cs.CV, cs.AI
发布日期: 2024-08-21 (更新: 2025-08-12)
备注: Accepted at ICCVW'25 - OpenSUN3D: 5th Workshop on Open-World 3D Scene Understanding with Foundation Models
💡 一句话要点
提出OE3DIS,解决开放场景下无需预定义类名的3D点云实例分割问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D点云分割 实例分割 开放词汇 多模态学习 大型语言模型
📋 核心要点
- 现有开放词汇3D实例分割方法依赖预定义类别名称,限制了智能体的自主性。
- 提出开放式3D实例分割(OE3DIS)问题,核心在于无需预定义类名即可进行实例分割。
- 构建基线方法并提出新的开放式评分指标,实验表明该方法性能超越现有最优方法。
📝 摘要(中文)
本文提出了一种新的问题,称为开放式3D实例分割(OE3DIS),旨在消除测试阶段对预定义类名的依赖,从而提升智能体的自主性。为了解决该问题,本文构建了一套强大的基线方法,这些方法源于开放词汇3D实例分割(OV-3DIS)方法,并利用了2D多模态大型语言模型。为了评估OE3DIS系统的性能,本文引入了一种新的开放式评分,该评分结合了预测掩码的语义和几何质量及其相关类名,以及标准的AP评分。实验结果表明,该方法在ScanNet200和ScanNet++数据集上显著优于基线方法。值得注意的是,即使在没有真实对象类名的情况下,该方法也超越了OV-3DIS中当前最先进的方法Open3DIS的性能。
🔬 方法详解
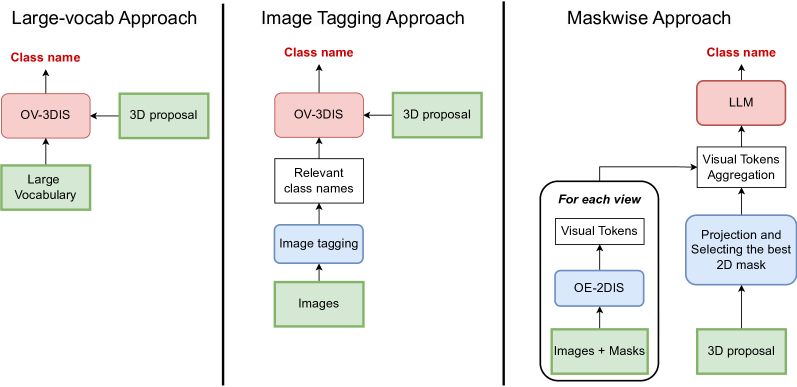
问题定义:现有开放词汇3D实例分割(OV-3DIS)方法虽然能够泛化到未见过的物体,但在测试时仍然需要预先定义的类别名称。这限制了智能体在真实世界中的自主性,因为智能体可能遇到无法提前预知的物体类别。因此,论文旨在解决在没有预定义类别名称的情况下进行3D点云实例分割的问题,即开放式3D实例分割(OE3DIS)问题。
核心思路:论文的核心思路是利用2D多模态大型语言模型(MLLM)的强大语义理解能力,结合3D几何信息,直接从点云数据中推断出实例的类别名称,而无需预先定义。通过将视觉信息与语言信息相结合,模型可以更好地理解场景,并对物体进行更准确的分割和分类。
技术框架:整体框架包含以下几个主要步骤:1) 使用现有的OV-3DIS方法生成3D点云的实例分割掩码;2) 将每个实例的3D点云投影到2D图像上;3) 使用2D多模态大型语言模型(例如,CLIP)提取2D图像的视觉特征和文本描述的语义特征;4) 将视觉特征和语义特征进行融合,预测每个实例的类别名称;5) 使用新的开放式评分指标评估分割掩码的质量和类别名称的准确性。
关键创新:该论文的关键创新在于提出了OE3DIS问题,并设计了一种利用2D多模态大型语言模型解决该问题的方法。与传统的OV-3DIS方法相比,该方法不需要预定义类别名称,从而提高了智能体的自主性和泛化能力。此外,论文还提出了一个新的开放式评分指标,可以更全面地评估OE3DIS系统的性能。
关键设计:在技术细节方面,论文使用了现有的OV-3DIS方法作为分割掩码的生成器,并利用CLIP模型提取视觉和语义特征。关键的设计在于如何将2D图像的视觉特征与3D点云的几何信息相结合,以及如何设计损失函数来优化模型的性能。此外,开放式评分指标的设计也至关重要,需要能够准确地评估分割掩码的质量和类别名称的准确性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在ScanNet200和ScanNet++数据集上显著优于基线方法。更重要的是,即使在没有真实对象类名的情况下,该方法也超越了OV-3DIS中当前最先进的方法Open3DIS的性能。这表明该方法具有很强的泛化能力和鲁棒性,能够在开放环境中有效地进行3D实例分割。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、场景理解等领域。例如,机器人可以在未知环境中识别和分割物体,从而更好地完成任务。自动驾驶系统可以识别道路上的各种障碍物,并进行相应的避让。该研究还有助于构建更智能、更自主的智能体,使其能够更好地适应复杂多变的环境。
📄 摘要(原文)
Open-Vocab 3D Instance Segmentation methods (OV-3DIS) have recently demonstrated their ability to generalize to unseen objects. However, these methods still depend on predefined class names during testing, restricting the autonomy of agents. To mitigate this constraint, we propose a novel problem termed Open-Ended 3D Instance Segmentation (OE-3DIS), which eliminates the necessity for predefined class names during testing. Moreover, we contribute a comprehensive set of strong baselines, derived from OV-3DIS approaches and leveraging 2D Multimodal Large Language Models. To assess the performance of our OE-3DIS system, we introduce a novel Open-Ended score, evaluating both the semantic and geometric quality of predicted masks and their associated class names, alongside the standard AP score. Our approach demonstrates significant performance improvements over the baselines on the ScanNet200 and ScanNet++ datasets. Remarkably, our method surpasses the performance of Open3DIS, the current state-of-the-art method in OV-3DIS, even in the absence of ground-truth object class names.