Positional Prompt Tuning for Efficient 3D Representation Learning
作者: Shaochen Zhang, Zekun Qi, Runpei Dong, Xiuxiu Bai, Xing Wei
分类: cs.CV
发布日期: 2024-08-21 (更新: 2025-09-24)
备注: Accepted at ACMMM 2025 Oral
🔗 代码/项目: GITHUB
💡 一句话要点
提出PPT:一种高效的3D表示学习位置提示微调方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D点云 表示学习 参数高效微调 位置编码 Transformer
📋 核心要点
- 现有基于点Transformer的3D表示学习方法计算成本高昂,微调效率低,限制了其在资源受限场景的应用。
- PPT通过引入可训练的位置编码和增加patch tokens,在冻结大部分预训练参数的同时,实现高效的参数微调。
- 实验表明,PPT仅需少量可训练参数即可在多个3D点云数据集上取得SOTA结果,验证了其有效性和效率。
📝 摘要(中文)
本文重新思考了位置编码在3D表示学习和微调中的作用。我们认为,在基于点Transformer的方法中使用位置编码有助于聚合点云的多尺度特征。此外,我们通过提示和适配器的视角探索了参数高效微调(PEFT),并提出了一种简单而有效的方法,称为PPT,用于点云分析。PPT结合了增加的patch tokens和可训练的位置编码,同时保持大多数预训练模型参数冻结。大量的实验验证了PPT的有效性和效率。我们提出的PEFT任务方法PPT,仅用1.05M的训练参数,在几个主流数据集上获得了最先进的结果,例如在ScanObjectNN OBJ_BG数据集上获得了95.01%的准确率。
🔬 方法详解
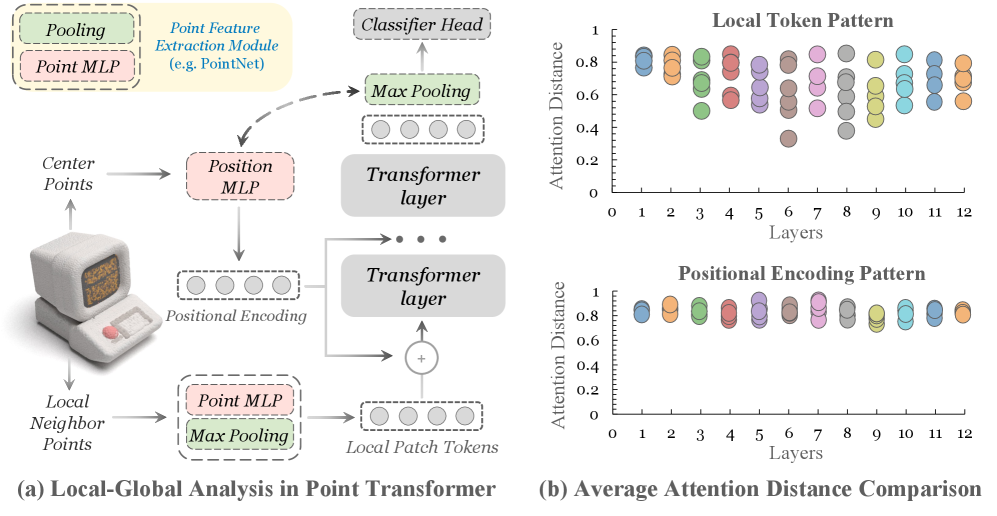
问题定义:论文旨在解决3D点云表示学习中,现有方法微调参数量大、计算成本高的问题。现有方法通常需要对整个模型进行微调,导致计算资源消耗大,效率低下,难以适应实际应用场景。
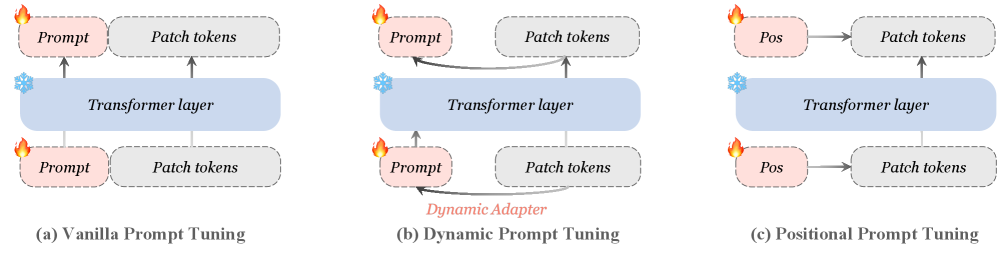
核心思路:论文的核心思路是利用参数高效微调(PEFT)的思想,通过引入可训练的位置编码(positional prompt)和增加patch tokens,在冻结大部分预训练模型参数的前提下,仅微调少量参数,从而实现高效的3D点云表示学习。这种方法旨在保留预训练模型的泛化能力,同时针对特定任务进行优化。
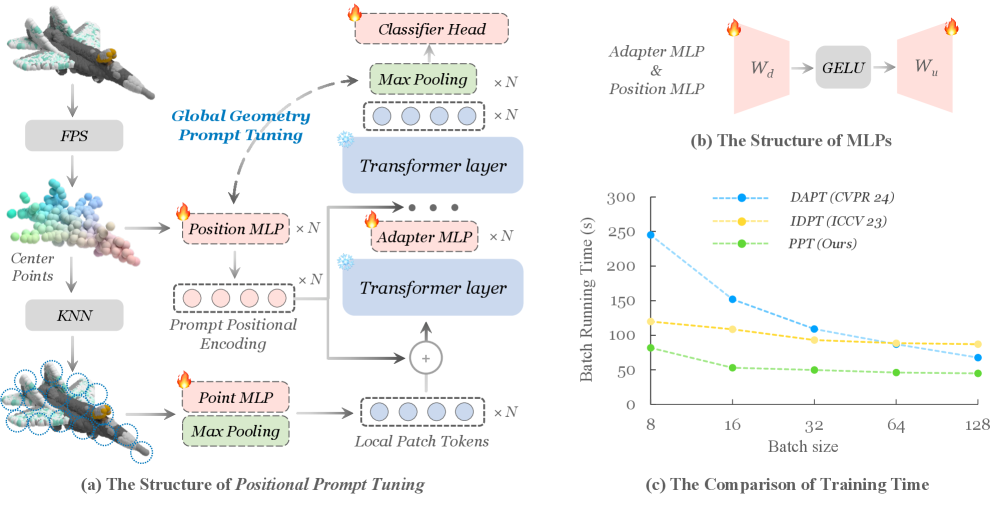
技术框架:PPT方法主要包含以下几个关键模块:1) 预训练的点Transformer模型;2) 可训练的位置编码模块,用于学习特定任务的位置信息;3) 增加的patch tokens,用于增强模型对局部特征的感知能力。整个流程是,首先将点云数据输入到预训练的点Transformer模型中提取特征,然后将提取的特征与可训练的位置编码和增加的patch tokens进行融合,最后将融合后的特征输入到下游任务进行微调。
关键创新:PPT的关键创新在于将位置编码视为一种prompt,通过学习特定任务的位置信息,引导模型更好地适应下游任务。与传统的微调方法相比,PPT只需要微调少量参数,大大降低了计算成本。此外,增加patch tokens的设计增强了模型对局部特征的感知能力,提高了模型的性能。
关键设计:PPT的关键设计包括:1) 可训练的位置编码的初始化方式,论文可能采用了随机初始化或基于预训练模型的位置编码进行初始化;2) patch tokens的数量和维度,这些参数需要根据具体的任务和数据集进行调整;3) 损失函数的设计,论文可能采用了交叉熵损失函数或其他的损失函数来优化模型。
🖼️ 关键图片
📊 实验亮点
PPT在ScanObjectNN OBJ_BG数据集上取得了95.01%的准确率,在多个主流数据集上获得了SOTA结果。该方法仅需1.05M的可训练参数,相比于全参数微调,大大降低了计算成本,验证了其在参数效率和性能方面的优越性。实验结果表明,PPT是一种高效且有效的3D点云表示学习方法。
🎯 应用场景
PPT方法可应用于各种3D点云分析任务,如物体识别、场景分割、三维重建等。该方法具有参数量小、计算效率高的优点,尤其适用于资源受限的移动平台或嵌入式设备。未来,该方法有望推动3D视觉技术在自动驾驶、机器人、增强现实等领域的广泛应用。
📄 摘要(原文)
We rethink the role of positional encoding in 3D representation learning and fine-tuning. We argue that using positional encoding in point Transformer-based methods serves to aggregate multi-scale features of point clouds. Additionally, we explore parameter-efficient fine-tuning (PEFT) through the lens of prompts and adapters, introducing a straightforward yet effective method called PPT for point cloud analysis. PPT incorporates increased patch tokens and trainable positional encoding while keeping most pre-trained model parameters frozen. Extensive experiments validate that PPT is both effective and efficient. Our proposed method of PEFT tasks, namely PPT, with only 1.05M of parameters for training, gets state-of-the-art results in several mainstream datasets, such as 95.01% accuracy in the ScanObjectNN OBJ_BG dataset. Codes and weights will be released at https://github.com/zsc000722/PPT.