EMO-LLaMA: Enhancing Facial Emotion Understanding with Instruction Tuning
作者: Bohao Xing, Zitong Yu, Xin Liu, Kaishen Yuan, Qilang Ye, Weicheng Xie, Huanjing Yue, Jingyu Yang, Heikki Kälviäinen
分类: cs.CV
发布日期: 2024-08-21
🔗 代码/项目: GITHUB
💡 一句话要点
EMO-LLaMA:通过指令微调增强多模态大语言模型在面部表情理解上的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 面部表情识别 多模态大语言模型 指令微调 情感人工智能 人机交互
📋 核心要点
- 现有面部表情识别方法泛化性差,缺乏自然语言语义对齐,且难以统一处理图像和视频,限制了其在多模态情感理解中的应用。
- EMO-LLaMA通过指令微调,并结合预训练面部分析网络的先验知识,增强MLLM对人脸信息的理解能力,从而提升面部表情识别性能。
- 实验结果表明,EMO-LLaMA在静态和动态面部表情识别数据集上取得了与SOTA方法相当或更优的结果,验证了其有效性。
📝 摘要(中文)
面部表情识别(FER)是情感人工智能中的一个重要研究课题。近年来,研究人员取得了显著进展。然而,当前的FER范式在泛化性、缺乏与自然语言对齐的语义信息以及难以在统一框架内处理图像和视频方面面临挑战,这使得它们在多模态情感理解和人机交互中的应用变得困难。多模态大语言模型(MLLM)最近取得了成功,为解决这些问题并可能克服当前FER范式的局限性提供了优势。然而,直接将预训练的MLLM应用于FER仍然面临一些挑战。我们对现有开源MLLM在FER上的零样本评估表明,与GPT-4V和当前有监督的SOTA方法相比,存在显著的性能差距。在本文中,我们旨在增强MLLM在理解面部表情方面的能力。我们首先使用Gemini为五个FER数据集生成指令数据。然后,我们提出了一种新的MLLM,名为EMO-LLaMA,它结合了来自预训练面部分析网络的先验知识,以增强人脸信息。具体来说,我们设计了一个人脸信息挖掘模块来提取全局和局部人脸信息。此外,我们利用手工制作的提示来引入年龄-性别-种族属性,考虑到不同人群的情感差异。大量的实验表明,EMO-LLaMA在静态和动态FER数据集上都取得了与SOTA相当或具有竞争力的结果。指令数据集和代码可在https://github.com/xxtars/EMO-LLaMA获取。
🔬 方法详解
问题定义:论文旨在解决现有面部表情识别(FER)方法的局限性,包括泛化能力不足、缺乏与自然语言的语义对齐以及难以统一处理图像和视频等问题。现有方法难以有效应用于多模态情感理解和人机交互。
核心思路:论文的核心思路是利用多模态大语言模型(MLLM)的优势,通过指令微调的方式,增强其在面部表情理解方面的能力。同时,引入预训练面部分析网络的先验知识,以提升人脸信息的提取和利用效率。
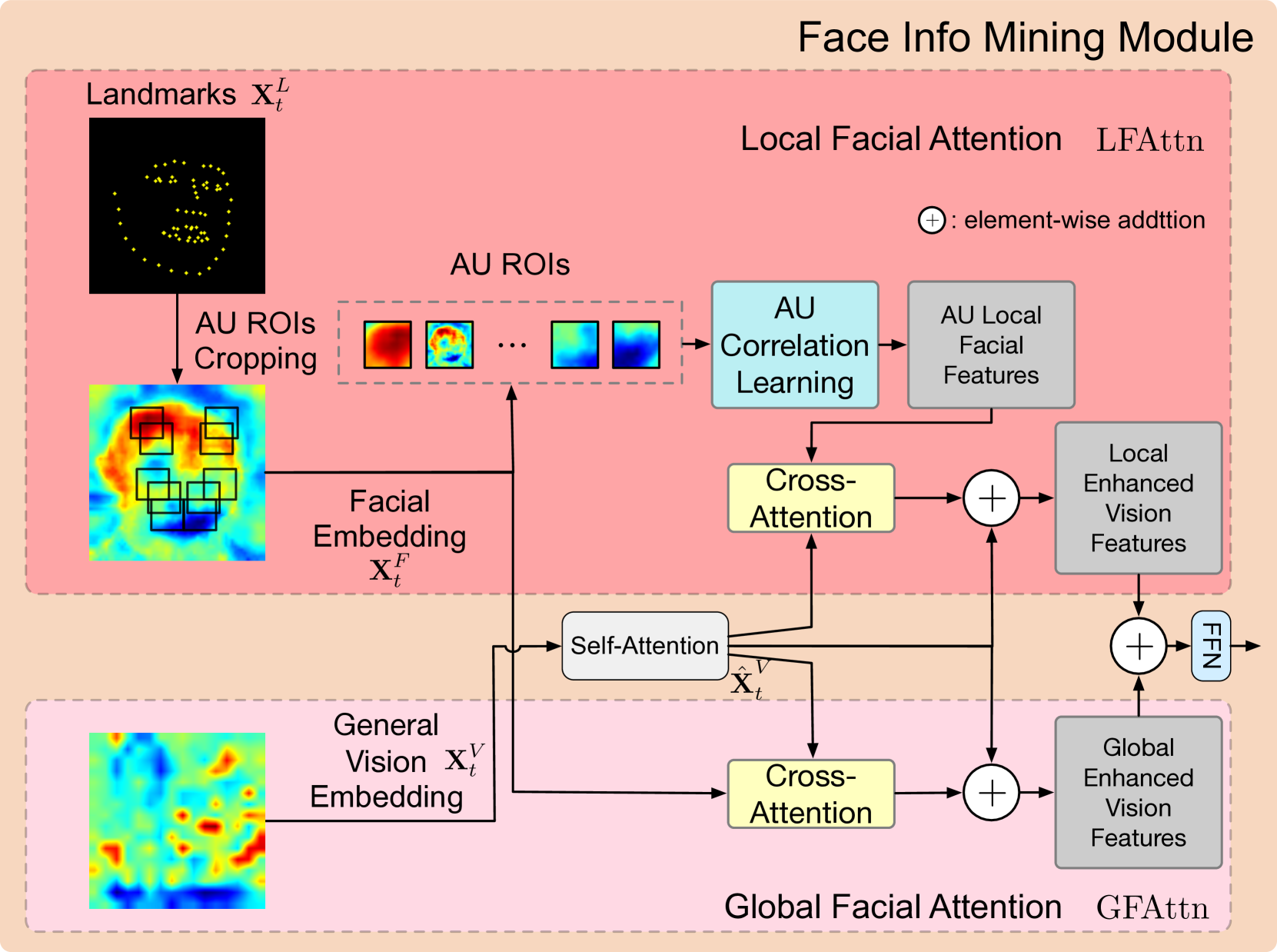
技术框架:EMO-LLaMA的整体框架包括以下几个主要模块:1) 使用Gemini生成FER数据集的指令数据;2) 设计Face Info Mining模块,提取全局和局部人脸信息;3) 利用手工制作的提示,引入年龄、性别和种族等属性;4) 使用生成的指令数据对MLLM进行微调。
关键创新:论文的关键创新在于:1) 提出了EMO-LLaMA模型,该模型结合了预训练面部分析网络的先验知识,能够更有效地提取人脸信息;2) 设计了Face Info Mining模块,用于提取全局和局部人脸信息;3) 利用手工制作的提示,引入了年龄、性别和种族等属性,从而考虑了不同人群的情感差异。
关键设计:Face Info Mining模块的具体设计细节未知,但其目标是提取全局和局部人脸信息。手工制作的提示的具体内容未知,但其目的是引入年龄、性别和种族等属性。损失函数和网络结构等其他技术细节也未知。
🖼️ 关键图片


📊 实验亮点
EMO-LLaMA在静态和动态FER数据集上取得了与SOTA方法相当或具有竞争力的结果。具体性能数据和对比基线未在摘要中明确给出,但论文强调了其性能优于现有开源MLLM,并接近或达到GPT-4V的水平。该模型在多个数据集上验证了其有效性。
🎯 应用场景
EMO-LLaMA的研究成果可应用于情感计算、人机交互、智能监控、心理健康评估等领域。例如,可以用于开发更自然、更智能的聊天机器人,或者用于辅助医生诊断心理疾病。该研究有助于提升机器对人类情感的理解能力,从而促进人与机器之间的更有效沟通。
📄 摘要(原文)
Facial expression recognition (FER) is an important research topic in emotional artificial intelligence. In recent decades, researchers have made remarkable progress. However, current FER paradigms face challenges in generalization, lack semantic information aligned with natural language, and struggle to process both images and videos within a unified framework, making their application in multimodal emotion understanding and human-computer interaction difficult. Multimodal Large Language Models (MLLMs) have recently achieved success, offering advantages in addressing these issues and potentially overcoming the limitations of current FER paradigms. However, directly applying pre-trained MLLMs to FER still faces several challenges. Our zero-shot evaluations of existing open-source MLLMs on FER indicate a significant performance gap compared to GPT-4V and current supervised state-of-the-art (SOTA) methods. In this paper, we aim to enhance MLLMs' capabilities in understanding facial expressions. We first generate instruction data for five FER datasets with Gemini. We then propose a novel MLLM, named EMO-LLaMA, which incorporates facial priors from a pretrained facial analysis network to enhance human facial information. Specifically, we design a Face Info Mining module to extract both global and local facial information. Additionally, we utilize a handcrafted prompt to introduce age-gender-race attributes, considering the emotional differences across different human groups. Extensive experiments show that EMO-LLaMA achieves SOTA-comparable or competitive results across both static and dynamic FER datasets. The instruction dataset and code are available at https://github.com/xxtars/EMO-LLaMA.